上次给大家分享了《2017年最全的excel函数大全14—统计函数(3)》,这次分享给大家统计函数(4)。
FORECAST.ETS.CONFINT 函数
说明
返回指定目标日期预测值的置信区间。 95% 的置信区间意味着 95% 的未来点预计将处于 FORECAST.ETS 预期结果中的此范围内(使用正态分布)。 使用置信区间可以帮助掌握预测模型的准确度。较小的区间意味着在针对此特定点的预测中有更多置信。
用法
预测. ets . confint ( target_date "、"值"、"时间线",[ confidence_level ]、[ seasonality ],[ data_completion ],[汇总])
FORECAST.ETS.CONFINT 函数用法具有以下参数:
target_date 必需。要为其预测值的数据点。目标日期可以是日期/时间或数字。 如果目标日期在历史时间线结束前按时间顺序排序,则 FORECAST.ETS.CONFINT 将返回 #NUM! 错误。
值 必需。 值是"历史值,您要为其预测下一点。
时间线 必需。独立数组或数值数据区域。时间线中的日期之间必须有一致步长且不能为零。 无需对时间线进行排序,因为 FORECAST.ETS.CONFINT 会对其进行隐式排序,以进行计算。 如果无法在提供的时间线中识别一致步长,则 FORECAST.ETS.CONFINT 将返回 #NUM! 错误。 如果时间线包含重复值,则 FORECAST.ETS.CONFINT 将返回 #VALUE! 错误。 如果时间线和值的范围大小不同,则 FORECAST.ETS.CONFINT 将返回 #N/A 错误。
confidence_level 可选。0 和 1 之间的一个数值(独占),指示计算置信区间的置信度。 例如,对于 90% 的置信区间,将计算 90% 置信度(90% 的未来点将处于此预测范围内)。 默认值为 95%。 对于 (0,1) 范围外的数值,FORECAST.ETS.CONFINT 将返回 #NUM! 错误。
季节性 可选。一个数值。 默认值为 1,意味着 Excel 自动检测季节性进行预测,并使用正整数作为季节性模式的长度。 0 表示无季节性,意味着预测为线性预测。 正整数指示算法使用此长度模式作为季节性。 对于其他任何值,FORECAST.ETS.CONFINT 将返回 #NUM! 错误。
最大支持 seasonality 是8,760(一年中的小时数)。 该数字上方的任何 seasonality 将导致"# NUM ! 错误。
数据完成 可选。虽然时间线需要数据点之间的一致步长,但 FORECAST.ETS.CONFINT 支持最多 30% 的丢失数据,并会自动对其进行调整。 0 表示算法将缺少的点视为零。 通过将缺少的点算为邻接点的平均值,默认值 1 将计算缺少的点。
聚合 可选。虽然时间线需要数据点之间的一致步长,但 FORECAST.ETS.CONFINT 会聚合具有相同时间戳的多个点。聚合参数是一个数值,指明要用于聚合具有相同时间戳的多个值的方法。默认值 0 将使用 AVERAGE,而其他选项为 SUM、COUNT、COUNTA、MIN、MAX、MEDIAN。
FORECAST.ETS.SEASONALITY 函数
说明
返回 Excel 针对指定时间系列检测到的重复模式的长度。 FORECAST.ETS.Seasonality 可用于FORECAST.ETS之后,确定已检测到的自动季节性和 FORECAST.ETS 使用的季节性。 虽然它可以独立于 FORECAST.ETS 使用,但鉴于相同的输入参数会影响数据完整性,函数会受到限制,因为在该函数中检测到的季节性与 FORECAST.ETS 使用的季节性相同。
用法
FORECAST.ETS.SEASONALITY(值, 时间线,[data_completion], [聚合])
FORECAST.ETS.SEASONALITY 函数用法具有下列参数:
值 必需。 值是"历史值,您要为其预测下一点。
时间线 必需。独立数组或数值数据区域。时间线中的日期之间必须有一致步长且不能为零。 无需对时间线进行排序,因为 FORECAST.ETS.SEASONALITY 会对其进行隐式排序,以进行计算。 如果无法在提供的时间线中识别一致步长,则 FORECAST.ETS.SEASONALITY 将返回 #NUM! 错误。 如果时间线包含重复值,则 FORECAST.ETS.SEASONALITY 将返回 #VALUE! 错误。 如果时间线和值的范围大小不同,则 FORECAST.ETS.SEASONALITY 将返回 #N/A 错误。
数据完成 可选。虽然时间线需要数据点之间的一致步长,但 FORECAST.ETS.SEASONALITY 支持最多 30% 的丢失数据,并会自动对其进行调整。 0 表示算法将缺少的点视为零。 通过将缺少的点算为邻接点的平均值,默认值 1 将计算缺少的点。
聚合 可选。虽然时间线需要数据点之间的一致步长,但 FORECAST.ETS.SEASONALITY 会聚合具有相同时间戳的多个点。聚合参数是一个数值,指明要用于聚合具有相同时间戳的多个值的方法。默认值 0 将使用 AVERAGE,而其他选项为 SUM、COUNT、COUNTA、MIN、MAX、MEDIAN。
FORECAST.ETS.STAT 函数
说明
返回作为时间序列预测的结果的统计值。
统计值类型表明此函数请求的统计信息。
用法
FORECAST.ETS.STAT(值, 时间线, statistic_type, [季节性], [data_completion], [聚合])
FORECAST.ETS.STAT 函数用法具有以下参数:
值 必需。 值是"历史值,您要为其预测下一点。
时间线 必需。独立数组或数值数据区域。时间线中的日期之间必须有一致步长且不能为零。 无需对时间线进行排序,因为 FORECAST.ETS.STAT 会对其进行隐式排序,以进行计算。 如果无法在提供的时间线中识别一致步长,则 FORECAST.ETS.STAT 将返回 #NUM! 错误。 如果时间线包含重复值,则 FORECAST.ETS.STAT 将返回 #VALUE! 错误。 如果时间线和值的范围大小不同,则 FORECAST.ETS.STAT 将返回 #N/A 错误。
statistic_type 必需。 数字值介于1和8之间,指示哪些统计值将不会为计算预测返回。
季节性 可选。一个数值。 默认值为 1,意味着 Excel 自动检测季节性进行预测,并使用正整数作为季节性模式的长度。 0 表示无季节性,意味着预测为线性预测。 正整数指示算法使用此长度模式作为季节性。 对于其他任何值,FORECAST.ETS.STAT 将返回 #NUM! 错误。
最大支持 seasonality 是8,760(一年中的小时数)。 该数字上方的任何 seasonality 将导致"# NUM ! 错误。
数据完成 可选。虽然时间线需要数据点之间的一致步长,但 FORECAST.ETS.STAT 支持最多 30% 的丢失数据,并会自动对其进行调整。 0 表示算法将缺少的点视为零。 通过将缺少的点算为邻接点的平均值,默认值 1 将计算缺少的点。
聚合 可选。虽然时间线需要数据点之间的一致步长,但 FORECAST.ETS.STAT 会聚合具有相同时间戳的多个点。聚合参数是一个数值,指明要用于聚合具有相同时间戳的多个值的方法。默认值 0 将使用 AVERAGE,而其他选项为 SUM、COUNT、COUNTA、MIN、MAX、MEDIAN。
下列可选的统计信息可以返回:
Alpha ets 算法的参数 返回参数较高值"基值为最近的数据点的详细粗细。
Beta ets 算法的参数 返回参数的趋势值较高值为最近的趋势的详细粗细。
ets 算法的伽玛参数 返回参数 seasonality 值较高值为"最近使用的季节性期间内的详细粗细。
mase 跃点 返回绝对按比例缩放的错误平均值跃点数度量值预测的准确性。
smape 跃点 返回绝对跃点数基于百分比错误的准确性度量值的百分比错误的对称平均值。
mae 跃点 返回绝对跃点数基于百分比错误的准确性度量值的百分比错误的对称平均值。
rmse 跃点 返回 根 平均值平方值错误跃点数预测和观察值之间的差异的度量。
检测到步骤大小 返回历史时间线中检测到的步骤大小。
FORECAST.LINEAR 函数
说明
根据现有值计算或预测未来值。 预测值为给定 x 值后求得的 y 值。 已知值为现有的 x 值和 y 值,并通过线性回归来预测新值。 可以使用该函数来预测未来销售、库存需求或消费趋势等。
用法
预测.线性( x , known _ y ' s , known _ x ' s )
FORECAST.LINEAR 函数用法具有以下参数:
X 必需。 需要进行值预测的数据点。
Known_y's 必需。 相关数组或数据区域。
Known_x's 必需。 独立数组或数据区域。
FREQUENCY 函数
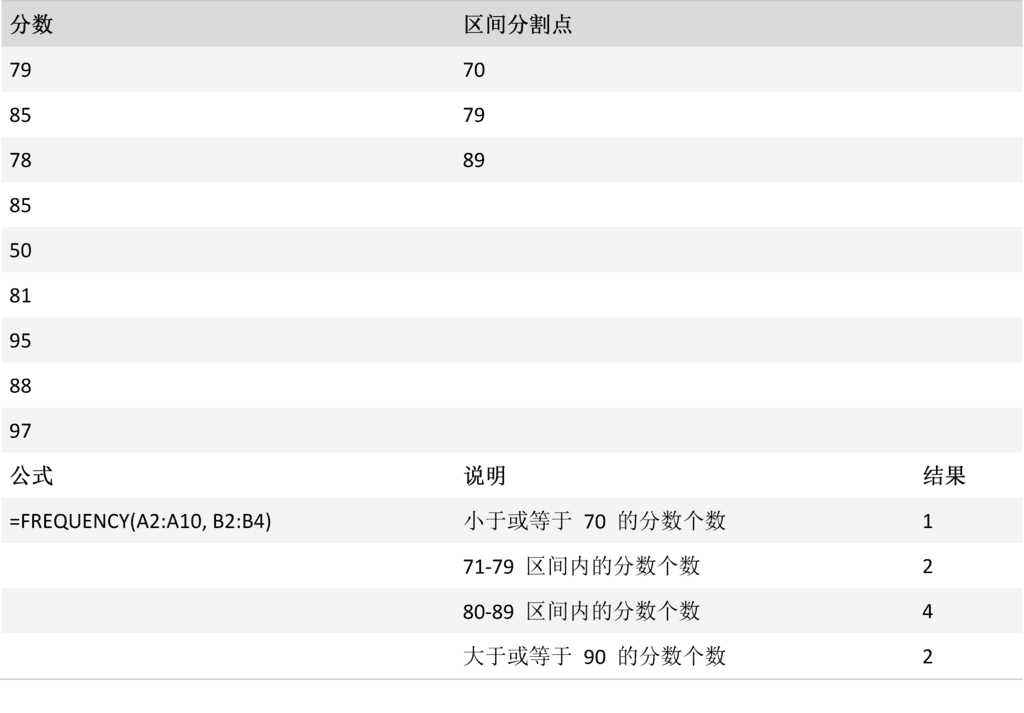
说明
计算数值在某个区域内的出现频率,然后返回一个垂直数组。 例如,使用函数 FREQUENCY 可以在分数区域内计算测验分数的个数。 由于 FREQUENCY 返回一个数组,所以它必须以数组公式的形式输入。
用法
FREQUENCY(data_array, bins_array)
FREQUENCY 函数用法具有下列参数:
Data_array必需。 要对其频率进行计数的一组数值或对这组数值的引用。 如果 data_array 中不包含任何数值,则 FREQUENCY 返回一个零数组。
Bins_array必需。 要将 data_array 中的值插入到的间隔数组或对间隔的引用。 如果 bins_array 中不包含任何数值,则 FREQUENCY 返回 data_array 中的元素个数。
备注
在选择了用于显示返回的分布结果的相邻单元格区域后,函数 FREQUENCY 应以数组公式的形式输入。
返回的数组中的元素比 bins_array 中的元素多一个。 返回的数组中的额外元素返回最高的间隔以上的任何值的计数。 例如,在对输入到三个单元格中的三个值范围(间隔)进行计数时,确保将 FREQUENCY 输入到结果的四个单元格。 额外的单元格将返回 data_array 中大于第三个间隔值的值的数量。
函数 FREQUENCY 将忽略空白单元格和文本。
对于返回结果为数组的公式,必须以数组公式的形式输入。
案例
GAMMA 函数
说明
返回 gamma 函数值。
用法
GAMMA(number)
GAMMA 函数用法具有下列参数:
Number 必需。 返回一个数字。
备注
GAMMA 使用以下公式:
Г(N+1) = N * Г(N)
如果 Number 为负整数或 0,则 GAMMA 返回 错误值 #NUM!。
如果 Number 包含无效的字符,则 GAMMA 返回 错误值 #VALUE!。
案例

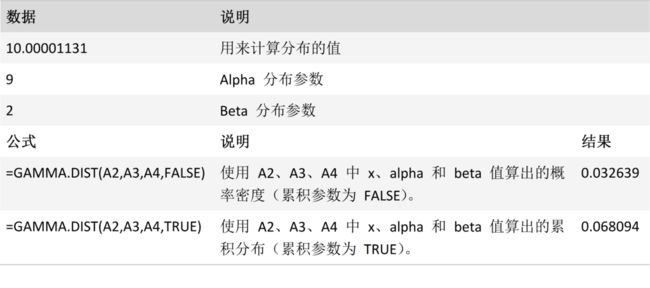
GAMMA.DIST 函数
说明
返回伽玛分布函数的函数值。 可以使用此函数来研究呈斜分布的变量。 伽玛分布通常用于排队分析。
用法
GAMMA.DIST(x,alpha,beta,cumulative)
GAMMA.DIST 函数用法具有下列参数:
X必需。 用来计算分布的数值。
Alpha必需。 分布参数。
Beta必需。 分布参数。 如果 beta = 1,则 GAMMA.DIST 返回标准伽玛分布。
Cumulative必需。 决定函数形式的逻辑值。 如果 cumulative 为 TRUE,则 GAMMA.DIST 返回累积分布函数;如果为 FALSE,则返回概率密度函数。
备注
如果 x、alpha 或 beta 为非数值型,则 GAMMA.DIST 返回 错误值 #VALUE!。
如果 x < 0,则 GAMMA.DIST 返回 错误值 #NUM!。
如果 alpha ≤ 0 或 beta ≤ 0,则 GAMMA.DIST 返回 错误值 #NUM!。
伽玛概率密度函数的计算公式如下:
标准伽玛概率密度函数为:
当 alpha = 1 时,GAMMA.DIST 返回如下的指数分布:
对于正整数 n,当 alpha = n/2,beta = 2 且 cumulative = TRUE 时,GAMMA.DIST 以自由度 n 返回 (1 - CHISQ.DIST.RT(x))。
当 alpha 为正整数时,GAMMA.DIST 也称为爱尔朗 (Erlang) 分布。
案例
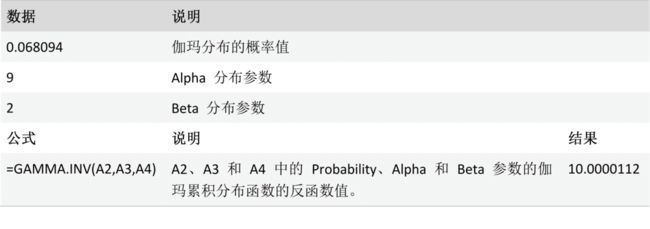
GAMMA.INV 函数
说明
返回伽玛累积分布函数的反函数值。 如果 p = GAMMA.DIST(x,...),则 GAMMA.INV(p,...) = x。 使用此函数可以研究有可能呈斜分布的变量。
用法
GAMMA.INV(probability,alpha,beta)
GAMMA.INV 函数用法具有下列参数:
Probability必需。 伽玛分布相关的概率。
Alpha必需。 分布参数。
Beta必需。分布参数。如果 beta = 1,则 GAMMA.INV 返回标准伽玛分布。
备注
如果任一参数为文本型,则 GAMMA.INV 返回 错误值 #VALUE!。
如果 probability < 0 或 probability > 1,则 GAMMA.INV 返回 错误值 #NUM!。
如果 alpha ≤ 0 或 beta ≤ 0,则 GAMMA.INV 返回 错误值 #NUM!。
如果已给定概率值,则 GAMMA.INV 使用 GAMMA.DIST(x, alpha, beta, TRUE) = probability 求解数值 x。 因此,GAMMA.INV 的精度取决于 GAMMA.DIST 的精度 GAMMA.INV 使用迭代搜索技术。 如果搜索在 64 次迭代之后没有收敛,则函数返回错误值 #N/A。
案例
GAMMALN 函数
说明
返回伽玛函数的自然对数,Γ(x)。
用法
GAMMALN(x)
GAMMALN 函数用法具有下列参数:
X必需。 要计算其 GAMMALN 的数值。
备注
如果 x 为非数值型,则 GAMMALN 返回 错误值 #VALUE!。
如果 x ≤ 0,则 GAMMALN 返回 错误值 #NUM!。
数字 e 的 GAMMALN(i) 次幂的返回值与 (i - 1)! 的结果相同,其中 i 为整数。
GAMMALN 的公式为:
其中:
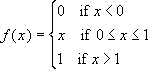
案例

GAMMALN.PRECISE 函数
说明
返回伽玛函数的自然对数,Γ(x)。
用法
GAMMALN.PRECISE(x)
GAMMALN.PRECISE 函数用法具有下列参数:
X必需。 要计算其 GAMMALN.PRECISE 的数值。
备注
如果 x 为非数值型,则 GAMMALN.PRECISE 返回 错误值 #VALUE!。
如果 x ≤ 0,则 GAMMALN.PRECISE 返回 错误值 #NUM!。
数字 e 的 GAMMALN.PRECISE(i) 次幂返回与 (i-1)! 相同的结果,其中 i 为整数。
GAMMALN.PRECISE 计算公式如下:
GAMMALN.PRECISE=LN(Γ(x))
其中:

案例

GAUSS 函数
说明
计算标准正态总体的成员处于平均值与平均值的 z 倍标准偏差之间的概率。
用法
GAUSS(z)
GAUSS 函数用法具有下列参数:
z 必需。返回一个数字。
备注
如果 z 不是有效数字,GAUSS 返回 错误值 #NUM!。
如果 z 不是有效数据类型,GAUSS 返回 错误值 #VALUE!。
因为 NORM.S.DIST(0,True) 总是返回 0.5,所以 GAUSS (z) 将总是等于NORM.S.DIST(z,True) - 0.5。
案例

GEOMEAN 函数
说明
返回一组正数数据或正数数据区域的几何平均值。 例如,可以使用 GEOMEAN 计算可变复利的平均增长率。
用法
GEOMEAN(number1, [number2], ...)
GEOMEAN 函数用法具有下列参数:
number1, number2, ...Number1 是必需的,后续数字是可选的。 用于计算平均值的 1 到 255 个参数。 也可以用单一数组或对某个数组的引用来代替用逗号分隔的参数。
备注
参数可以是数字或者是包含数字的名称、数组或引用。
逻辑值和直接键入到参数列表中代表数字的文本被计算在内。
如果数组或引用参数包含文本、逻辑值或空白单元格,则这些值将被忽略;但包含零值的单元格将计算在内。
如果参数为错误值或为不能转换为数字的文本,将会导致错误。
如果任一数据点小于等于 0,则 GEOMEAN 返回 错误值 #NUM!。
几何平均值的公式为:
案例

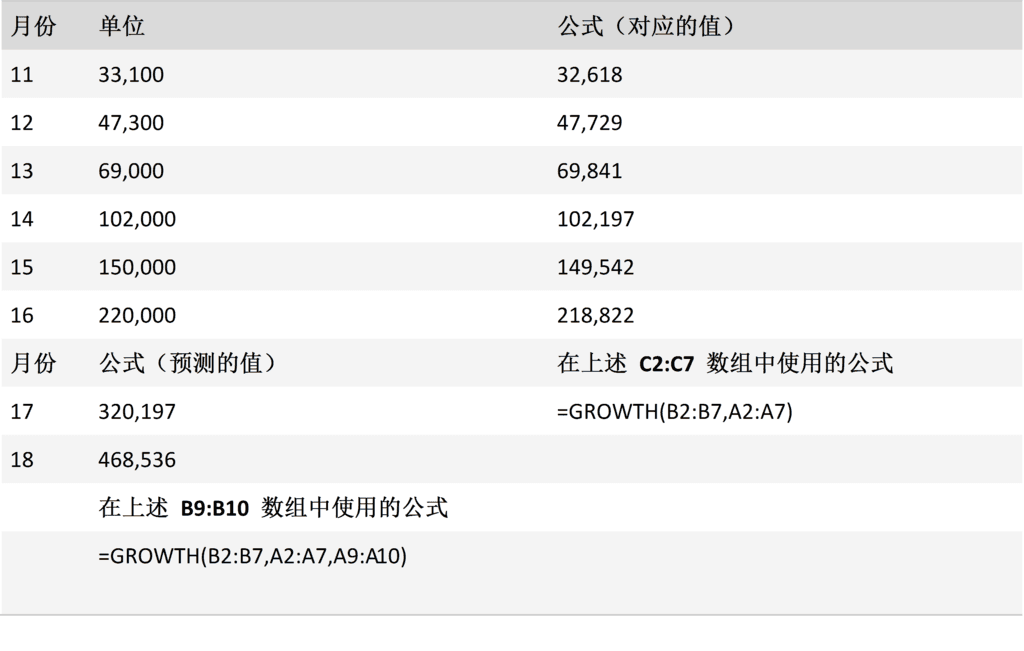
GROWTH 函数
说明
使用现有数据计算预测的指数等比。 GROWTH 通过使用现有的 x 值和 y 值,返回指定的一系列的新 x 值的 y 值。 您也可以使用 GROWTH 工作表函数以拟合指数曲线与现有的 x 值和 y 值。
用法
GROWTH(known_y's, [known_x's], [new_x's], [const])
GROWTH 函数用法具有下列参数:
Known_y's必需。 关系表达式 y = b*m^x 中已知的 y 值集合。
如果数组 known_y's 在单独一列中,则 known_x's 的每一列被视为一个独立的变量。
如果数组 known_y's 在单独一行中,则 known_x's 的每一行被视为一个独立的变量。
如果 known_y's 中的任何数为零或为负数,则 GROWTH 返回。 错误值 #NUM!。
Known_x's可选。 关系表达式 y=b*m^x 中已知的 x 值集合,为可选参数。
数组 known_x's 可以包含一组或多组变量。 如果仅使用一个变量,那么只要 known_x's 和 known_y's 具有相同的维数,则它们可以是任何形状的区域。 如果用到多个变量,则 known_y's 必须为向量(即必须为一行或一列)。
如果省略 known_x's,则假设该数组为 {1,2,3,...},其大小与 known_y's 相同。
New_x's可选。 需要 GROWTH 返回对应 y 值的新 x 值。
New_x's 与 known_x's 一样,对每个自变量必须包括单独的一列(或一行)。 因此,如果 known_y's 是单列的,known_x's 和 new_x's 应该有同样的列数。 如果 known_y's 是单行的,known_x's 和 new_x's 应该有同样的行数。
如果省略 new_x's,则假设它和 known_x's 相同。
如果 known_x's 与 new_x's 都被省略,则假设它们为数组 {1,2,3,...},其大小与 known_y's 相同。
Const可选。 一个逻辑值,用于指定是否将常量 b 强制设为 1。
如果 const 为 TRUE 或省略,b 将按正常计算。
如果 const 为 FALSE,b 将设为 1,m 值将被调整以满足 y = m^x。
备注
对于返回结果为数组的公式,在选定正确的单元格个数后,必须以数组公式的形式输入。
当为参数(如 known_x's)输入数组常量时,应当使用逗号分隔同一行中的数据,用分号分隔不同行中的数据。
案例
HARMEAN 函数
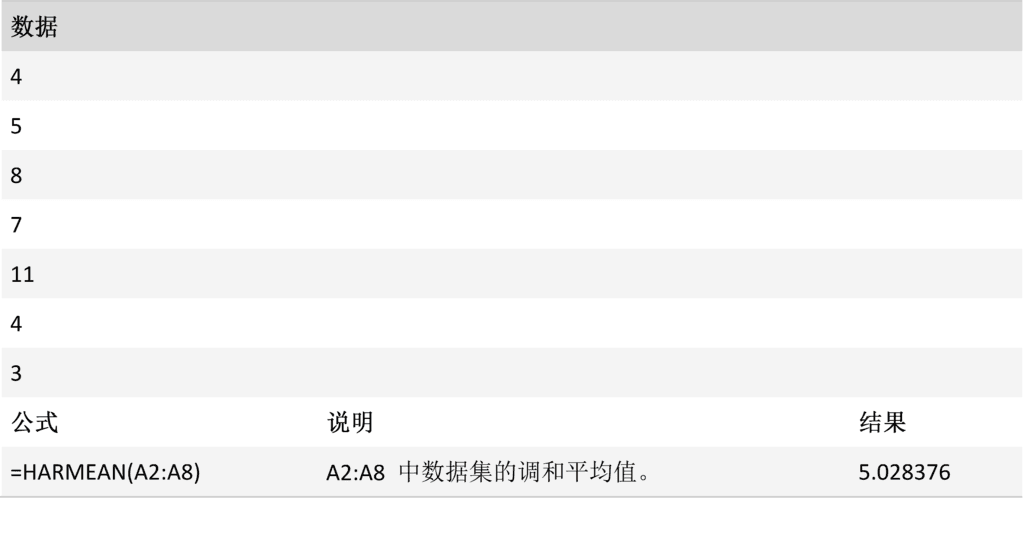
说明
返回一组数据的调和平均值。 调和平均值与倒数的算术平均值互为倒数。
用法
HARMEAN(number1, [number2], ...)
HARMEAN 函数用法具有下列参数:
number1, number2, ...Number1 是必需的,后续数字是可选的。 用于计算平均值的 1 到 255 个参数。 也可以用单一数组或对某个数组的引用来代替用逗号分隔的参数。
备注
调和平均值始终小于几何平均值,而几何平均值总是小于算术平均值。
参数可以是数字或者是包含数字的名称、数组或引用。
逻辑值和直接键入到参数列表中代表数字的文本被计算在内。
如果数组或引用参数包含文本、逻辑值或空白单元格,则这些值将被忽略;但包含零值的单元格将计算在内。
如果参数为错误值或为不能转换为数字的文本,将会导致错误。
如果任一数据点小于等于 0,则 HARMEAN 返回 错误值 #NUM!。
调和平均值的公式为:
案例
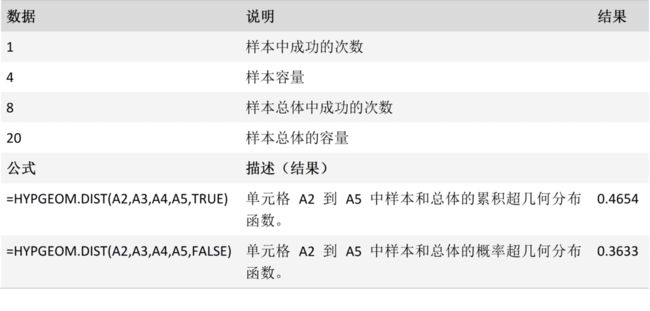
HYPGEOM.DIST 函数
说明
返回超几何分布。 如果已知样本量、总体成功次数和总体大小,则 HYPGEOM.DIST 返回样本取得已知成功次数的概率。 Use HYPGEOM.DIST 用于处理以下的有限总体问题,在该有限总体中,每次观察结果或为成功或为失败,并且已知样本量的每个子集的选取是等可能的。
用法
HYPGEOM.DIST(sample_s,number_sample,population_s,number_pop,cumulative)
HYPGEOM.DIST 函数用法具有下列参数:
Sample_s必需。 样本中成功的次数。
Number_sample必需。 样本量。
Population_s必需。 总体中成功的次数。
Number_pop必需。 总体大小。
cumulative必需。 决定函数形式的逻辑值。 如果 cumulative 为 TRUE,则 HYPGEOM.DIST 返回累积分布函数;如果为 FALSE,则返回概率密度函数。
备注
所有参数都将被截尾取整。
如果任一参数为非数值型,则 HYPGEOM.DIST 返回 错误值 #VALUE!。
如果 sample_s < 0 或 sample_s 大于 number_sample 和 population_s 中的较小值,则 HYPGEOM.DIST 返回 错误值 #NUM!。
如果 sample_s 小于 0 和 (number_sample - number_population + population_s) 中的较大值,则 HYPGEOM.DIST 返回 错误值 #NUM!。
如果 number_sample ≤ 0 或 number_sample > number_population,则 HYPGEOM.DIST 返回 错误值 #NUM!。
如果 population_s ≤ 0 或 population_s > number_population,则 HYPGEOM.DIST 返回 错误值 #NUM!。
如果 number_pop ≤ 0,则 HYPGEOM.DIST 返回 错误值 #NUM!。
超几何分布的公式为:
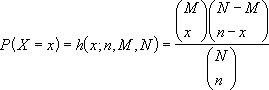
其中:
x = sample_s
n = number_sample
M = population_s
N = number_pop
函数 HYPGEOM.DIST 用于在有限样本总体中进行不退回抽样的概率计算。
案例
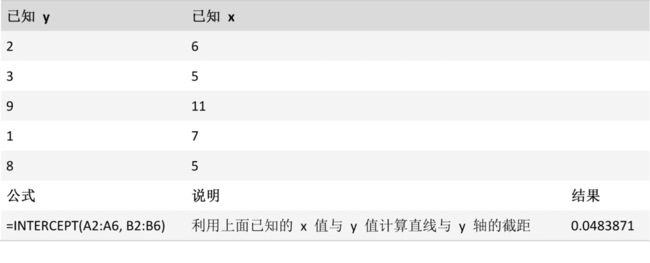
INTERCEPT 函数
说明
利用已知的 x 值与 y 值计算直线与 y 轴交叉点。 交叉点是以通过已知 x 值和已知 y 值绘制的最佳拟合回归线为基础的。 当自变量是 0(零)时,可使用 INTERCEPT 函数确定因变量的值。 例如,当您在室温或更高温度的情况下采集数据点时,您可以使用 INTERCEPT 函数预测金属在 0°C 时的电阻。
用法
INTERCEPT(known_y's, known_x's)
INTERCEPT 函数用法具有下列参数:
Known_y's必需。 因变的观察值或数据的集合。
Known_x's必需。 自变的观察值或数据的集合。
备注
参数可以是数字,或者是包含数字的名称、数组或引用。
如果数组或引用参数包含文本、逻辑值或空白单元格,则这些值将被忽略;但包含零值的单元格将计算在内。
如果 known_y's 和 known_x's 所包含的数据点个数不相等或不包含任何数据点,则函数 INTERCEPT 返回错误值 #N/A。
回归线 a 的截距公式为:
公式中斜率 b 计算如下:

其中 x 和 y 是样本平均值 AVERAGE(known_x's) 和 AVERAGE(known_y's)。
INTERCEPT 和 SLOPE 函数中使用的下层算法与 LINEST 函数中使用的下层算法不同。 当数据未定且共线时,这些算法之间的差异会导致不同的结果。 例如,如果参数 known_y's 的数据点为 0,参数 known_x's 的数据点为 1:
INTERCEPT 和 SLOPE 返回 错误 #DIV/0!。 INTERCEPT 和 SLOPE 的算法用于只查找一个答案,在这种情况下,还可能会出现多个答案。
LINEST 会返回值 0。 LINEST 的算法用来返回共线数据的合理结果,在这种情况下至少可找到一个答案。
案例
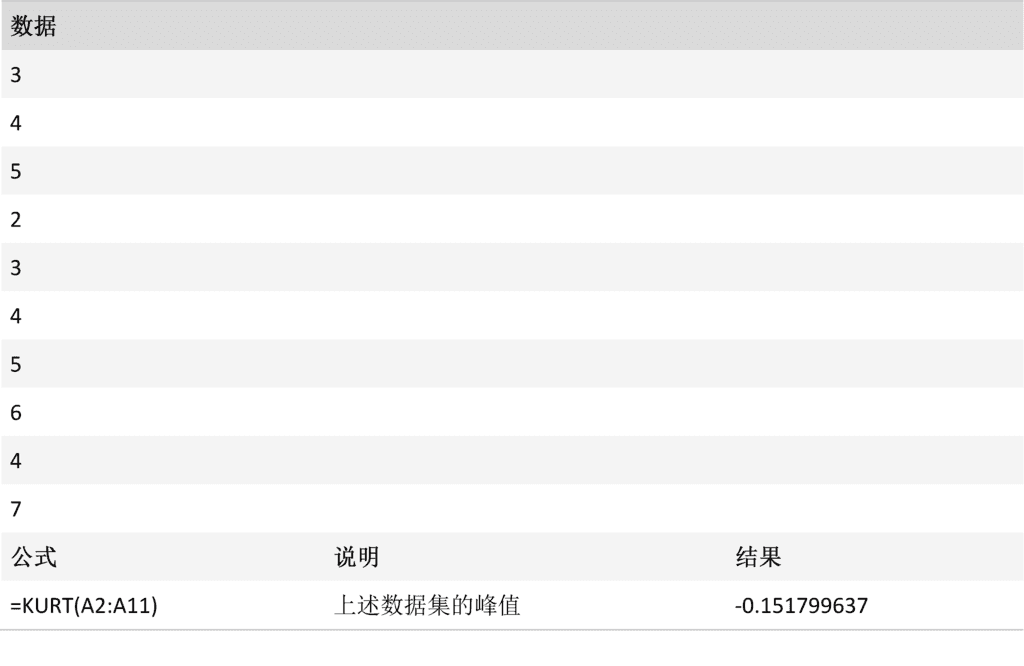
KURT 函数
说明
返回一组数据的峰值。 峰值反映与正态分布相比某一分布的相对尖锐度或平坦度。 正峰值表示相对尖锐的分布。 负峰值表示相对平坦的分布。
用法
KURT(number1, [number2], ...)
KURT 函数用法具有下列参数:
number1, number2, ...Number1 是必需的,后续数字是可选的。 用于计算峰值的 1 到 255 个参数。 也可以用单一数组或对某个数组的引用来代替用逗号分隔的参数。
备注
参数可以是数字或者是包含数字的名称、数组或引用。
逻辑值和直接键入到参数列表中代表数字的文本被计算在内。
如果数组或引用参数包含文本、逻辑值或空白单元格,则这些值将被忽略;但包含零值的单元格将计算在内。
如果参数为错误值或为不能转换为数字的文本,将会导致错误。
如果数据点少于 4 个,或样本标准偏差等于 0,则 KURT 返回 错误值 #DIV/0!。
峰值的公式为:

S 为样本的标准偏差。
案例
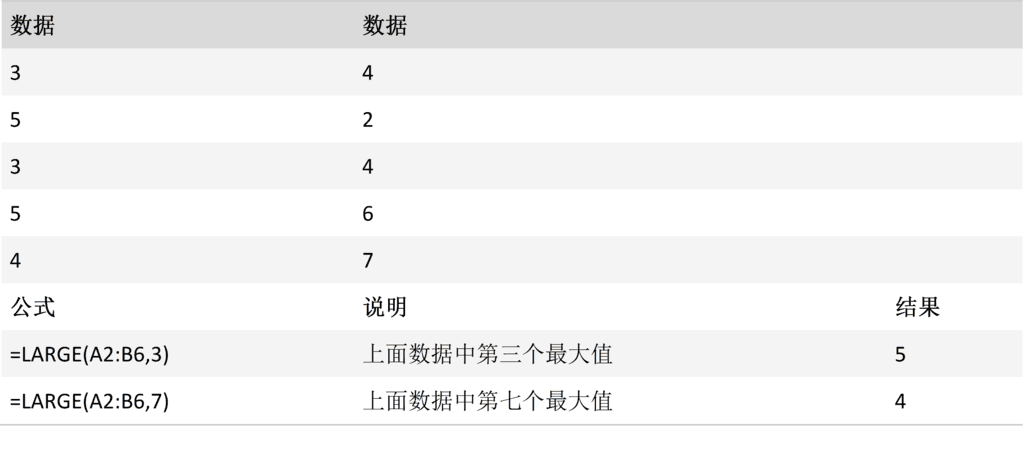
LARGE 函数
说明
返回数据集中第 k 个最大值。 您可以使用此功能根据其相对位置选择一个值。 例如,您可以使用 LARGE 返回最高、第二或第三的分数。
用法
LARGE(array,k)
LARGE 函数用法具有下列参数:
Array必需。 需要确定第 k 个最大值的数组或数据区域。
K必需。 返回值在数组或数据单元格区域中的位置(从大到小排)。
备注
如果数组为空,则 LARGE 返回 错误值 #NUM!。
如果 k ≤ 0 或 k 大于数据点的个数,则 LARGE 返回 错误值 #NUM!。
如果区域中数据点的个数为 n,则函数 LARGE(array,1) 返回最大值,函数 LARGE(array,n) 返回最小值。
案例
以上是所有EXCEL的统计函数(4)说明用法以及使用案例。这次分享中存在哪些疑问或者哪些不足,可以在下面进行评论。如果觉得不错,可以分享给你的朋友,让大家一起掌握这些excel的统计函数(4)。