2018年数人云Meetup第一站,联合vivo在深圳举办 Building Microservice 系列活动第一期。本次技术沙龙vivo、中兴通讯、华为、数人云共同派出技术大咖,为开发者们带来有关微服务、容器化、配置中心、服务网格等领域的实战与干货分享。
数人云Meetup每月一期,欢迎大家来面基、学习。本文为vivo云计算架构师袁乐林分享的“vivo云服务容器化实践”现场演讲实录。
今天讲的内容主要是介绍技术背景,产品的技术架构,我们关键技术的实践,前车之鉴,以及对下一代云服务架构的设想。
技术背景

vivo这些年的业务增长非常快,用户数已经上亿,服务器到了万级,业务域好几百,后端系统的复杂度在迅速攀升,不光是运维方面、架构体系复杂度也非常高,vivo技术架构也是到了破茧化蝶的时候。
我们做过容器、虚拟机与物理机性能对比测试。上面这张图是当时做的性能测试架构图。得出了一些测试结论:
1.容器化app(4c8g)在性能上略优于非容器化app测试指标
2.容器化app(32c64g)性能相较于裸跑同物理机有近4%左右性能损耗,其中TPS有3.85%损耗,平均响应时间3.95%(1毫秒)的增加,对业务请求无影响。
3.容器化app在12h的稳定性测试中表现正常
4.容器化app在cpu相对配额,cpu绑定以及绝对配额场景下,业务性能CPU相对配额 > CPU绑定 > 绝对配额。
5.容器化app在组部件异常,单计算节点,控制异常场景下,容器运行正常。
综上所述,容器化app性能上接近物理机,在多测试场景下,表现相对稳定可靠。同时,对计算密集型app,相对权重配额能实现CPU资源利用率最大化。
vivo容器化云服务框架

正是因为这个性能测试数据的支撑,就有了vivo容器化云服务框架,我们给它取名 Kiver,提供轻量级、高可靠的容器化生产方案。

在这个框架之上vivo一共有八个云服务,按照后来统计数据来看,MySQL加上其他两个服务占到80%的比例,这也非常符合“二八”原则。

vivo整个云服务容器化产品的架构,左边是运维自动化的工具集,比如日志、监控等,日志在业界应用非常广泛,我们用采集容器的数据、容器的监控指标。
这里有两个日志,上面是中间件的业务日志平台,所有业务基于中间件日志规范,输出日志后都会送到这里面收集起来,但是这个业务日志平台功能目前比较薄弱,对新增加的一些组件,比如ECTD等不支持。vivo又引入了现在容器领域比较常见的日志方案EFK,今后会规划把两个日志整合到一起。
vivo在运维方面做了一些工具,如 vivo MachineCtl和 KiverCtl,两个工具主要实现宿主机的自动化,简单来说可以把宿主机操作系统自动化地装起来,装完之后变成Kiver的计算节点或者控制节点。还有KiverPerfermance,是我们内嵌的一个小的性能测试插件。
再来看右边,是vivo的基础设施,物理机和交换机,网络设备和防火墙等,上面是Docker,Docker容器虚拟化技术把物理机上面的相关资源虚拟化用起来。
右边有 Ceph 块存储,实现数据备份,上面是vivo自研的DevOps平台,做了调度框架,右边是用harbor做的镜像仓库,再往上就是云服务Portal,前面所说的那些云服务,同时也可以跑长生命周期应用。
宿主机自动化实践

下面我们讲一下vivo的实践。现在物理机一旦上了规模之后,装操作系统就成为一件大事,我们提供了 vivoMachineCtl,这个工具是一个命令行给运维人员使用,可以实现宿主机集中化的参数配置和自动化。
利用 vivoMachineCtl,首先和物理机管理卡做一个交互,交互之后拿到物理机的MAC地址,这里有个BMC,也有厂商叫iDrac卡,它可以取得这台服务器网卡的MAC地址,创建以MAC地址命名的Bootfile,指明现在需要装什么操作系统,和其他一些参数。再进一步给它一个ipmi消息对服务器复位,然后服务器开始重启。
重启之后,服务器第一次会发dhcp请求,拿到IP地址,之后会走一个pxe的协议,拿到bootfile,下载Bootfile所指明的小系统和内存文件系统文件下来,加载到物理机中,然后开始进行操作系统安装。这就是操作系统安装的过程。操作系统安装完成之后,把安装类和文件系统切换成正在启动的文件系统,在post阶段到集中化的配置中心,把相关的配置拉下来,包括IP地址,主机名和网关等信息,这是宿主机的自动化部署。
KiverCtl实际上就是把操作系统的宿主机变成计算节点或者控制节点。计算节点有如下几个功能:第一,基本的包安装,第二,Docker、Netplugin初始化,启动kiver-guard/flume/cadvisor容器,完成日志和监控指标的采集。
控制节点上面有Etcd和Netmaster,也会可选地Prometheus/alertmanager/grafana/启动起来。vivoMachineCtl和KiverCtl实现了云服务器节点从物理机到宿主机的转变。
业务日志集成到日志平台实践

这是vivo日志采集的实践,在宿主机上做日志分区,容器运行起来之后挂这个目录,每个容器起来之后会创建一个自己的文件目录。外面有kiver-guard,用来侦听内核文件系统的新日志文件创建的通知。
根据通知会创建软件链接,链接到上一级Flume监控的日志目录,由Flume推到kafka。大数据平台会来消费这里的数据,业务日志平台也会消费这个数据,然后持久化到ES里,最后由中间件日志平台来实现对日志的检索和展示。
为什么要这么做?当时用的flume版本不支持自动收集递归子目录下日志新增内容的收集,完整的文件可以收集进去,但是日志文件在递归子目录下有不停地追加是输不进去的。

kiver-guard本身也是一个容器,它起来之后把宿主机日志目录挂上去,在容器里面侦听日志目录下的create事件。
不管这些日志路径有多深或者在哪里,都可以链接出来。做链接的时候有一点需要注意,要确保链接过来之后文件名称是唯一的。有些容器被删除了,或者日志被轮转删除了,同样也会针对Delete事件,侦测到delete是件之后删除上层flume监控日志路径的对应链接。
基础组件日志收集实践

基础组件日志采用Etcd、Ceph、CentOS、Netmaster等一些网上比较热门的EFK组件,开箱即用。
监控与告警实践

这是监控和告警实践,在容器领域比较常见,vivo采用的是Promethus和Alertmanager。Promethus采用双节点,双拉(拉两遍),两个Promethus之间没有做主从,为了解决高可用问题,挂了一个另外一个还在。

之后接短信邮件中心,后面接Grafana作为监控面板,前面用了telegraf。我们做的东西不仅仅有容器,还有其他的组件像Ceph。我们用Cadvisor收集容器监控指标。
我们对集群健康做监控,也对集群资源使用情况进行监控,集群的健康性采用telegraf可以调用外部shell脚本的特性。我们在控制节点写了脚本,用来检查Etcd的健康情况,也和各个节点进行通讯,检查各个节点是不是健康。之后会返回数值,给出集群健康状态码。
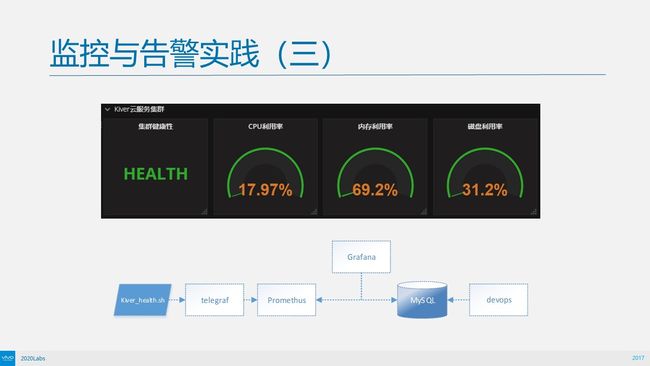
这个就是前面讲的自定义的一些监控指标,这是集群的健康检查,这是集群的资源利用率,大致两条数据链进来。一个脚本由telegraf去拉,推到Prometheus里面,最后展现在Grafana上面。另一个,由DevOps框架把数据写到Mysql里面,再由Grafana定义Mysql的软件源。
这边拉出来的自定义的健康指标支持返回码,这个返回码需要翻译成文字,实际上Grafana已经具备这个特性,我们可以去做一个映射,比如1代表监控,2代表网络问题等等,它可以自动翻译来。
数据持久化实践

说到云服务大家都会关注这个问题,数据怎么做到持久化,做到不丢。容器启动的时候会挂在宿主机上面的一个数据目录,和日志类似,有容器的启动进程,直接写脚本也可以,创造二级目录。
用主机名,是在容器默认的主机名,就是它的默认ID号。如果这个ID已经存在就不用创建,说明容器是起用一个旧的容器,最后建立软链接到数据目录。这样确保每个容器日志数据都持久化到宿主机,还可以确保容器重启后数据不丢。
第二,数据本身有一个单独的备份系统,它会每天晚上凌晨2点跑一遍,把Mysql数据推到Ceph块存储当中,实现数据的可靠性。
集群可靠性实践

这是容器集群可靠性实践,最典型的是三个副本,副本能够实现数据和服务的可靠性。

失效重试,在集群各节点提供一个crontab定时任务,每隔一段时间探测一次docker服务进程健康状况,若不健康,则拉起Docker服务进程。同时我们开启了docker的Restartalways选项,确保容器服务异常退出后,能被重新拉起来。

关于隔离,首先是分区隔离,宿主机业务日志目录/app/log独立分区,避免日志量过大时侵占宿主机系统分区或者业务分区磁盘。
第二,资源隔离,flume当时是跑进程的,我们做的第一件事情是进行容器化,之后做配额,限制能使用的资源使用量,避免大日志传输时侵占宿主机过多资源。
第三,故障隔离,开启dockerlive-restore选项,保障docker服务进程不影响容器服务。
前车之辙

我们犯过一些错误,不负责物理机运营的童鞋可能感受不明显。如果磁盘引导分区被破坏,就可能导致操作系统被重装,这个问题是很严重的。原因也很简单,服务器一般有多引导的选项,比如磁盘、网络、CD,一般在顺序上磁盘第一,网络第二。
但如果磁盘引导分区坏了,服务器会认为没有操作系统,然后就从第二个上引导。这时候不幸的事情是,在你的网络环境里如果之前刚好装过操作系统,采用了第三方开源的部署服务器,而没有把之前的文件删掉,那么它就会把那些操作重新装上。
解决办法很简单,我们提供了定时任务,对两个小时前创建的引导文件,能看见它的创建时间、访问时间,并进行强制性删除。

第二个前车之辙,在收集Ceph日志时碰到困难,当时是用fluent-plugin-ceph插件来做。具体的情况是,第一,官方配置文档不正确,因为提交者没按官方文档格式编码,导致看到的配置是一行,拿回来根本不知道怎么办。第二,它和td-agent1.0 版本不兼容。摸索出的解决方法就是图片上显示的办法。
** 下一代云服务架构**
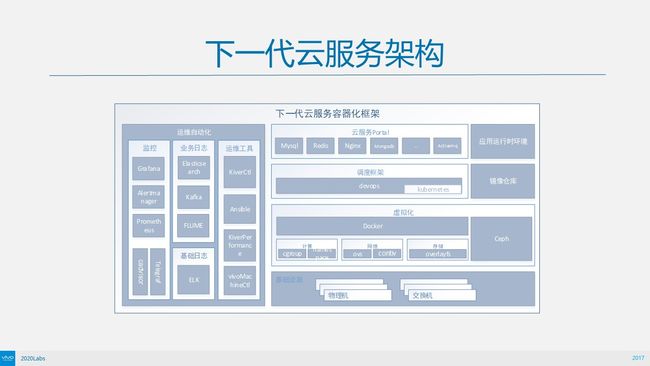
这是我们下一代云服务架构,与上一代的主要区别在于,把编排框架换成了Kubernetes。目前AI这块已经用起来了,AI部分在线上大概有一百台物理机,跑Job任务,短任务每天可以跑到三万个,一次性可以调动3000个容器,未来会把这个些换成Kubnernetes,包括我们的AI、云服务都会跑在Kubernetes上。
XaaS on Kubernetes

如果把云服务跑到Kubernetes上,第一个要做的事情,可能会采用ceph块存储做后面的数据和数据持久化。目前vivo已经有了数据ceph块存储,但功能还不强大。第二,要解决pod漂移调度问题,如果不用ceph块存储,pod失效调度到其他节点上有问题,调过去没用的,没有数据。 第三,也是最常见的一个,固定POD IP,看到网上有人讨论这个事情,觉得容器坏了,没必要把容器固定起来,因为有违微服务的原则。这种观点不太对,有一些场景,比如在vivo的企业IT架构里面,很多东西都跟IP挂钩,比如安全策略,它不是跟域名挂钩,而是PODIP挂钩,交换机、防火墙等很多的配置都跟这个相关。所以vivo要干的很重要的事情,就是把POD IP固定。 目前业界对这块也有一些实践,比如京东最近有这方面的分享,把PODIP放在一个APP的IP 小池子里面,小池子里面还有IP的话,就从小池子里拿,没有的话就从大池子里去申请。
在数人云微信公众号后台回复“127”,即可获取本次演讲PPT《vivo云服务容器化实践》。