如果关注这个领域的同学可能知道,Ray其实在去年就已经在开源社区正式发布了,只不过后来就一直没有什么太大动静,前段时间也是因为机缘巧合,我又回头学习了解了一下,顺便总结如下:
Ray是什么?
Ray 是RISELab实验室(前身也就是开发Spark/Mesos等的AMPLab实验室)针对机器学习领域开发的一种新的分布式计算框架。按照官方的定义:“Ray is a flexible, high-performance distributed execution framework”。看起来很明确的定义对吧,不过所谓的:“灵活的高性能的分布式执行框架”,这句话无论是哪个分布式计算框架,大概都会往自己身上套。那么Ray的不同之处在哪里呢?当Spark/Flink/TensorFlow等一众计算框架在机器学习领域中不断开疆扩土,风头正劲的时候,为什么RISELab的同学们又要另起炉灶,再发明一个新的轮子呢?

这个问题的答案和其他发明轮子的同学的说法也很类似:因为既有的系统不满足某种需求。那么这种需求是真需求还是伪需求,如果是真需求,既有的系统不能满足的原因是暂时的,可以改进的,不关本质的具体实现问题,还是由于根源上的架构和方案的局限性所决定的呢?下面就让我来现学现卖,分析讨论一下。
目标问题
Ray的目标问题,主要是在类似增强学习这样的场景中所遇到的工程问题。那么增强学习的场景和普通的机器学习,深度学习的场景又有什么不同呢?简单来说,就是对整个处理链路流程的时效性和灵活性有更高的要求。
增强学习的场景,按照原理定义,因为没有预先可用的静态标签信息,所以通常需要引入实际的目标系统(为了加快训练,往往是目标系统的模拟环境)来获取反馈信息,用做损失/收益判断,进而完成整个训练过程的闭环反馈。典型的步骤是通过观察特定目标系统的状态,收集反馈信息,判断收益,用这些信息来调整参数,训练模型,并根据新的训练结果产出可用于调整目标系统的行为Action,输出到目标系统,进而影响目标系统状态变化,完成闭环,如此反复迭代,最终目标是追求某种收益的最大化(比如对AlphoGo来说,收益是赢得一盘围棋的比赛)。
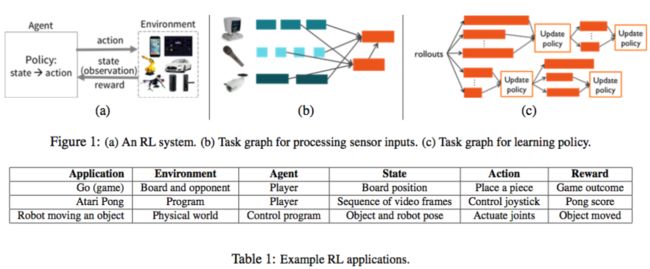
在这个过程中,一方面,模拟目标系统,收集状态和反馈信息,判断收益,训练参数,生成Action等等行为可能涉及大量的任务和计算(为了选择最佳Action,可能要并发模拟众多可能的行为)。而这些行为本身可能也是千差万别的异构的任务,任务执行的时间也可能长短不一,执行过程有些可能要求同步,也有些可能更适合异步。
另一方面,整个任务流程的DAG图也可能是动态变化的,系统往往可能需要根据前一个环节的结果,调整下一个环节的行为参数或者流程。这种调整,可能是目标系统的需要(比如在自动驾驶过程中遇到行人了,那么我们可能需要模拟计算刹车的距离来判断该采取的行动是刹车还是拐弯,而平时可能不需要这个环节),也可能是增强学习特定训练算法的需要(比如根据多个并行训练的模型的当前收益,调整模型超参数,替换模型等等)。
此外,由于所涉及到的目标系统可能是具体的,现实物理世界中的系统,所以对时效性也可能是有强要求的。举个例子,比如你想要实现的系统是用来控制机器人行走,或者是用来打视频游戏的。那么整个闭环反馈流程就需要在特定的时间限制内完成(比如毫秒级别)。
总结来说,就是增强学习的场景,对分布式计算框架的任务调度延迟,吞吐量和动态修改DAG图的能力都可能有很高的要求。按照官方的设计目标,Ray需要支持异构计算任务,动态计算链路,毫秒级别延迟和每秒调度百万级别任务的能力。
那么现有的框架,真的不能满足这种场景的需求么?
从上面提到的目标问题来看,需求在对应的场景下是真需求应该问题不大。但现有的框架,通过适当的改进,真的满足不了这些需求么?以下我们主要结合Spark/Flink/TensorFlow等常见的当红分布式计算框架来讨论一下这些问题,也算是为Ray的方案选择再做一下理论和背景铺垫。
海量任务调度能力
首先来看每秒百万级别任务调度的能力,上述三种计算框架,基本采用的是中心集中式的任务调度机制,在作业任务调度的角色集中在单个中心节点的情况下,单个作业要实现每秒百万级别任务的调度能力,的确是不太现实的。
但问题未必只有一种解决方式,如果不能实现百万级别的任务调度能力,那么想办法降低需要调度的任务的数量就好了。比如像Flink这类以流式计算模型为基础的框架,往往可以将任务的调度问题转化为数据和指令的传输问题。所以在很多场景下,换一种处理模型,在同样的场景下,可能就不需要发起大量的任务调度了。
而对于Spark这样的批处理型框架来说,要提高任务调度的吞吐率,也可以有多种改进方案。比如通过任务树拆分,批量统一预调度等来分散调度负载,提高调度效率。当然这些框架如果要引入类似的改进,从工程实现的角度来看,需要一定的时间。但是本质上来说,是完全可以实现的,和他们的整体框架的核心思想本身并没有绝对的冲突。而Spark 2.3的版本中引入的continuous computation的概念,实际上也是用另一种方式,引入预调度的思想,通过建立long run的任务,简化多个Epoc批次的任务的调度流程,客观上减少了需要调度的任务的数量,同时,更重要的是对端到端的计算延迟也有显著改进。
另外,比如各种改进的PS参数服务器模型,引入各种PS端UDF或存储过程的实现,实际上从某种意义上来说,也是将一些子任务派发到PS节点去执行,减少了由于框架限制带来的数据和任务分发问题,客观上也能降低需要中心节点统一规划处理的任务的数量和负载。
毫秒级别的延迟
延迟其实有两个概念,一个是任务调度自身的延迟,另一个是整体数据计算的延迟。当然,前者是后者的基础,对后者是强相关影响的。对于基于流式计算模型的框架来说,当任务拓扑逻辑确定以后,通常不涉及更多的后续任务调度,所以整体的计算延迟,从流程上来说,只受数据流转效率的影响。在排除了计算的代价开销后,基本上就取决于数据传输批次Buffer的长度选择。追求吞吐率就使用较大的buffer来缓冲数据,追求端到端延迟则采用较小的buffer加快流转,比如Flink就允许用户定义相关参数。而此外,如前所述,Spark等框架也引入了连续计算模型来规避流式计算场景下的超短周期任务调度问题,从而改进端到端的计算延迟
异构任务的支持
这里说的异构任务,不光指的是不同类型的任务,还包括同类型的一批任务,由于环境,数据,参数的差异和变化,可能导致的计算时间上的倾斜问题。不管什么原因,概括起来就是在High level的一次训练迭代过程中,不同的任务的执行时间可能有很大的差异。
那么不同的任务,执行时间有差异,会给分布式计算框架的设计带来什么影响或者要求吗?
这里,主要的问题是,当前多数系统的调度逻辑,容错策略和执行性能是与同一批次的任务执行时间接近的假设相关的。比如分批次的任务调度,各批次之间的同步可能受最慢的Lagger任务的影响,资源的分配,慢任务的处理策略,往往也基于同批次任务执行时间应该接近的前提假设来设计,当这个前提假设不成立的时候,基本的流程策略的合理性和性能的好坏也就可能会受到比较大的影响。
如果是流式计算框架,链路上各计算步骤环节的算子,往往没有明确的任务划分的概念,所以从模型上来说,其实不太涉及异构任务的问题。当然,从数据处理的业务流程上来说,流式计算框架也还是有批次和同步的概念的,比如快照,window,跨流join等环节,就往往需要在各个算子乃至同一个算子的多个处理节点之间,达成一定的同步。但这种同步在具体框架的实现中,未必是通过时间域上的所有算子的绝对同步来实现,也未必涉及框架的调度性能等问题,所以和Ray的目标问题的定义还是有一些区别的,但这就要具体问题具体分析了。
任务拓扑图动态修改的能力
什么是动态修改任务拓扑图的能力呢?其实简单来说,就是你在编写程序,或者计算框架在开始启动任务时,并不能完全确定具体的任务执行流程,需要根据程序执行的中间结果来判断任务流程或者调整任务的拓扑结构。
所以,对于预先定义好计算逻辑,然后手动定义任务拓扑逻辑或者由框架优化执行计划并自动生成调度或任务拓扑逻辑的系统来说,不论Spark,Flink,storm还是Tensorflow,在任务执行的过程中,当任务拓扑逻辑已经生成的情况下,确实都不太具备严格意义上的动态修改任务拓扑图的能力。
但是不是一旦使用这些计算框架,就完全不能根据中途的计算结果和状态变化来调整程序的执行逻辑了呢?显然不是。
对于批处理型的任务,你完全可以根据上一步的结算结果,走不同的流程,选择生成下一步逻辑所需的任务拓扑结构。比如Hive任务就可以根据前一个Stage的执行结果,对下一步执行计划进行筛选,是执行本地Map Join还是走MR任务做Shuffle等。当然,这种修改拓扑图的能力是在更粗的粒度意义上的,有一定的局限性。
而对于流式计算框架,你也可以通过传输指令,或者状态变化触发的方式,在原有的任务拓扑逻辑结构内调整程序的执行逻辑。如果你能预先把所有可能的任务执行逻辑都部署好,通过指令或状态选择执行具体的逻辑路径,一定程度上也能满足动态修改任务流程的需要。当然,这对拓扑逻辑规划和具体编程也提出了更高的要求。
把上述问题结合起来完整的来看
如前所诉,上述问题需求如果分开来看,现有的框架或多或少都能通过这样或那样的方式在一定程度上满足需求,又或者可以通过别的手段来规避问题,迂回解决。但是在一个场景下,同时满足所有的需求,相对来说就比较困难了。
这其中,海量任务的调度能力和毫秒级别的延迟这两个需求的组合同时满足是难度之一,现有的框架往往很难同时兼顾,或者只能在特定的约束条件下部分满足。而对于异构任务的处理和任务拓扑图的动态修改能力这两点要求,从灵活性和性能考量方面来看,现有的框架也有很大的局限性,具体实现时,往往需要用户在应用逻辑层面自行规划,实现代价也可能比较高。
总之,好比CAP理论,这些问题要妥善的解决,至少现阶段,并没有面面俱到的完美方案。当前已有的方案,实际上也没有对错之分,只是各种计算框架的侧重点和取舍不同,那么Ray是如何进行取舍的呢。
Ray的基本架构设计思路
从任务调度的吞吐率和响应速度这两方面需求的角度来说,Ray的方案就是分而治之,概括来说,Ray没有采用中心任务调度的方案,而是采用了类似层级(hierarchy)调度的方案,除了一个全局的中心调度服务节点(实际上这个中心调度节点也是可以水平拓展的),任务的调度也可以在具体的执行任务的工作节点上,由本地调度服务来管理和执行。
与传统的层级调度方案,至上而下分配调度任务的方式不同的是,Ray采用了至下而上的调度策略。也就是说,任务调度的发起,并不是先提交给全局的中心调度器统筹规划以后再分发给次级调度器的。而是由任务执行节点直接提交给本地的调度器,本地的调度器如果能满足该任务的调度需求就直接完成调度请求,在无法满足的情况下,才会提交给全局调度器,由全局调度器协调转发给有能力满足需求的另外一个节点上的本地调度器去调度执行。
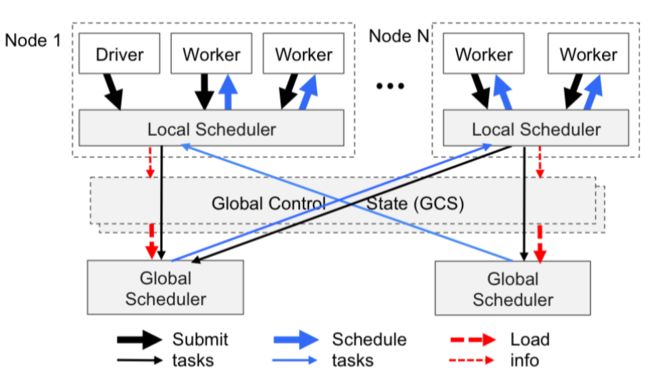
这么做的好处,一方面减少了跨节点的RPC开销,另一方面也能规避中心节点的瓶颈问题。当然缺点也不是没有,由于缺乏全局的任务视图,无法进行全局规划,因此任务的拓扑逻辑结构也就未必是最优的了。
从支持动态任务拓扑图和异构任务的角度来说,Ray的思路基本就是别在编程模型上做太多假定和约束限制,怎么灵活怎么来。问题是这要如何实现呢?
如果在单机上,其实后面两点要求很简单。所谓的动态拓扑逻辑,就是各种程序执行分支呗,各种函数调用和程序判断逻辑,天然就是根据当前程序的状态选择后续的执行路径,至于异构任务,不外乎就是不同路径触发不同的函数而已,如果需要并行处理,那么引入多线程,异步调用等等机制就好了,对于单机程序来说,这些都是再普通不过的标准实践,灵活性显然不是问题。
而Ray的基本设计思想,就是在分布式计算的环境下,实现类似单机执行程序的能力。让用户能在函数级别随意调用而不用操心这个函数具体执行的位置,不论从调用者的角度还是被调用者的角度,结合嵌套调用和本地任务调度的能力,整体上的执行流程也就不存在需要预先在中心节点进行规划部署的问题。
所以Ray的理想的实现,相当于把单机程序的执行能力在不做大的编程模型改造的前提下,适配到分布式计算的多节点环境中。如果能做到这一点,显然前面提到的任务拓扑的动态性和灵活性问题也就不是问题了。
Ray的具体实现
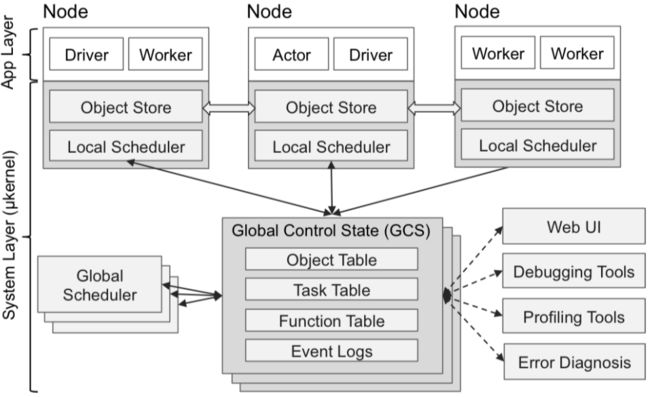
要实现上述思想,从工程的角度来说,有几个重要的问题需要解决。
首先来看至下而上分而治之的层级调度的实现问题。
本地调度器要能发挥最大的作用,就需要尽量减少任务通过全局调度器中转的必要性,因此本地调度器需要具备尽可能完备的获取系统全局信息的能力。此外,在分布式环境下,为了增强系统的鲁棒性,工作节点崩溃以后,该节点上本地调度器所管理任务的迁移能力,显然也是必备的。再有,对于全局调度器来说,也要具备HA的能力,而全局调度器的水平拓展能力则是进一步拓展任务调度吞吐率的基本要求。
为了应对这些需求,Ray将任务调度的执行逻辑和任务调度的状态信息进行了分离处理。通过全局的状态存储服务(Global Control State GCS)来存储和管理各类任务控制和状态信息,包括任务拓扑结构信息,数据和任务的生产关系信息,函数(任务)之间的调用关系拓扑结构信息等等。将这些状态信息剥离出来统一管理以后,调度器本身就成为了一个无状态的服务,因此也就具备了实现前面所说的任务迁移,扩展和信息共享的能力。
此外为了能和各种需要维护状态的任务进行交互,比如所模拟的目标系统的状态变迁,以及其它各种第三方有状态任务或接口逻辑的封装(比如通过TensorFlow训练一个神经网络模型的任务,这些第三方系统可能无法将内部状态信息暴露出来交给Ray来管理),Ray也定义了名为Actor的抽象封装。在Ray中,Actor是一种有状态的任务,通过暴露特定的方法接口供外部进行远程调用。而对于Actor的调用历史,也可以转化成一种自依赖关系拓扑图,保存在GCS中。从而将促成Actor内部状态变迁的调用过程也通过任务图的方式记录了下来,从而系统也就具备了Actor状态重建的能力。
其次,是实现函数能在任何节点上进行远程调用的问题。
Ray让用户通过显示的定义,比如@ray.remote的装饰器的形式来告知系统需要允许远程调用的函数。当一个远程调用函数被定义以后,它就会被推送到所有的工作节点上,已备后续调用。相关的函数代码也会被存储到GCS中。这样后续的任务调度,容错恢复等过程都能够更简单的实现,
@ray.remote
def f(x):
return x + 1
不过由于远程函数是在定义以后就立刻被推送到工作节点上去的,所以在远程函数中并不能引用后面的代码中所定义的函数/变量(大概是因为需要对闭包进行序列化的原因,而在运行时,无法执行编译时传统的二次扫描过程,只能或许截止目前已有的信息),这个问题,个人感觉对于写代码的同学来说应该是个很大的限制,不排除后续可以有更好的解决办法。
要使函数能在任意节点上远程执行,代码分发部署的问题解决以后,剩下的就是数据读写的问题。被远程调用的函数显然需要能够获取它所需要处理的数据。与代码的全局分发部署不同,数据显然无法也不适合提前在所有节点上都同步一份。Ray是通过在GCS中保存一份全局数据对象列表的方式,来管理各个工作节点上的本地数据。如果一个函数需要处理的数据对象不在工作节点本地,那么该工作节点上的对象存储服务(object Store)就会去GCS寻找该对象所在的节点映射信息,然后从对应节点的Object Store中拷贝一份数据到本地供函数执行时所用。而函数产出的数据对象也会由本地Object Store管理和保存,并将相关映射信息登记到GCS中供后续函数调用查询。
这么做,整体上看起来是把数据往代码处移动,和现代大数据环境下,典型的代码往数据移动的思想正好相反,貌似又走回到更早期的网格计算的旧路上去了。但实际计算过程中,如果上下游相关的远程函数调用最终被本地调度器调度到同一个工作节点上执行的话,数据实际上是在本地节点的。由于Object Store实现了数据零拷贝的本地共享能力,所以在任务调度合理的情况下,这种方案实际产生的数据拷贝动作的代价可能未必很高。加上高速网络的应用推广,数据拷贝成为瓶颈的可能性也大大降低,当然,对计算流程的latency还是有一些影响的。此外,因为实际的数据拷贝是在object Store之间直接点对点进行的,所以也不存在数据中转瓶颈的担忧。最后,其实这种数据向代码移动的设计,我理解和后面要解决的另一个问题:异构任务和任务执行时间倾斜问题的解决方案也是相关的。所以它其实是各种因素综合考虑以后取舍的结果。
最后来看一下计算框架流程上另一个重要的问题,就是对于异构任务和任务执行时间可能存在倾斜的问题处理。
Ray对于这个问题的解决方案是全面引入Future的概念,任务的执行不仅仅是Lazy的,结果数据的处理更是异步的。远程函数的调用,会立即返回一个结果数据的Future对象,这个Future对象可以进一步传递给下一个远程函数调用,当真正需要读取数据的时候,才会Block等待数据的真正计算完成。
这么做的结果,自然就是无法(或者不适合)提前根据数据的位置来确定代码执行的位置,因此,客观的也就导致了数据往代码移动,而不是代码往数据移动的计算模型。
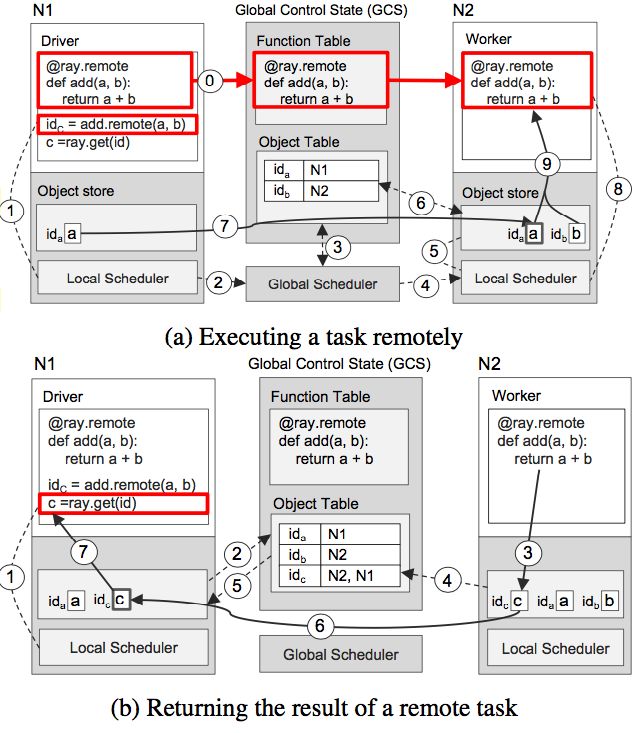
那么使用Future的好处是什么呢?一方面当然是为了尽可能提升并行效率。流程上执行快慢进度不一的任务之间,也不需要互相等待,降低各个任务之间非必要的进度同步的代价。另一方面,在分布式任务执行场景下,具体的算法策略也可以根据部分任务的执行结果来提前结束一次迭代或着调整计算流程,进而提高程序整体流转效率。比如,多个子模型同时训练的时候,根据最先完成的部分模型的结果来决策下一步的行动,使用部分计算结果先行调整模型参数等等。
这种打破全局批量同步(BSP)模型的应用场景在其它一些机器学习计算框架的实现中也有类似的例子,比如腾讯的Angel参数服务器所支持的SSP,ASP等处理模型。不过Angel提供的是框架自身定义好的,固定的同步逻辑实现,而Ray的核心框架层,则是通过Future和wait原语的方式将基础的语义暴露给用户,让用户自己来构建实现所需要的模型逻辑,相对来说更加灵活一些,当然,具体场景的实现代价也就稍微更高一些了。
和当前主流热门计算框架整体上再比较一下
分布式计算模型的发展历程就是一个在易用性,灵活性和效率性能之间进行平衡的过程。早期,MapReduce模型通过极度简化编程模型,大大降低了分布式编程的难度,但是为了提高编程效率,提供更加灵活的应用模型,社区在上层又开发了Hive/Pig等业务语义更加丰富的模型,但限于底层MR模型的约束,在性能上就受到了一定的限制,因此反过来,又促成了比如Tez等模型的发展,出现了Hive on Tez之类的实现。
Spark/Flink/TensorFlow等框架,从各自不同的角度重新定义或着放宽了编程模型的约束,增加了系统的灵活性,但本身核心的编程模型的使用和实现难度也就更高,开发过程中,需要开发人员对稳定性,性能进行的考虑也往往更多,这就要求这些框架的上层API可以通过封装和抽象,进一步简化和降低开发代价,又或者需要应用开发人员投入更多的精力和知识储备去针对性的解决问题。
Ray的整体设计思想,仅从核心框架的角度来对比的话,可以看到最突出的优势还是动态构建任务拓扑逻辑图的能力。因此更加适合一些任务流程复杂,需要按需调整的场景,典型的也就是前文提到的增强学习的场景。而其它的计算框架由于整体编程模型约束相对更强,所以要实现复杂的流程场景会更加困难一些,比如需要自行定制一些分布式的处理逻辑,对一些流程进行粘合等。所以,个人认为,Ray的成败关键,就在于在这类应用场景下,能替用户降低多少开发成本,能让用户多大程度上在保留灵活性的同时,减少开发和维护的成本。简单来说,易用性的好坏或许决定了Ray最终的价值。
比如远程函数一方面给了用户灵活切割代码逻辑,便于复用逻辑的好处。另一方面,它也需要用户明确的定义函数的边界,要求用户能够清晰的理顺自己程序的分布式运行逻辑,如何切分代码逻辑,不同的切分方案对性能是否有影响,函数之间的并发如何设定,如何交互,哪些逻辑适合用无状态的模式实现,哪些需要构建有状态的Actor等等,都需要用户自己来考虑,随之而来的问题就是应用构建的难度可能更高。如果要降低开发代价,就需要更智能的解决这个问题,需要上层API层/应用层提供不同层次的抽象,来降低特定场景的应用构建门槛。
用同类系统做个类比,比如,Spark的核心编程模型是RDD,它的基本思想就是构建RDD对象,然后按RDD间的依赖关系切分作业任务,递推执行,这个思想本身很聪明,但如果Spark只是单纯提供这个核心思想的基本实现框架的话,显然不可能成为一个热门的计算框架,因为用户的学习成本和开发成本太高了。所以,Spark在上层提供了各类基本算子,抽象简化了常见计算流程的开发模式,让用户一定程度上无需太多关心RDD的概念细节,而是关注在算子逻辑的串联和应用上。但仅仅如此还不够,RDD为编程接口的模型对于多数用户来说还是门槛太高,所以Spark进一步抽象封装了包括Stream/SQL/Graph/ML/DataFrame/Dataset在内的各个层级的高层语义或算法逻辑来进一步降低开发成本,应该说,这些上层API的完善,才是Spark计算框架能够更好的推广应用的关键所在。
Flink和TensorFlow也不例外,核心的编程模型(TensowFlow的核心思想再简单不过了,数据用Tensor表达,在节点间传递Tensor,具体算子适配和屏蔽底层硬件细节)本身并不是决定他们成败的关键,有太多的类似思想的系统实现,关键的是至下而上整体各个层面的具体实现的好坏,完整性和易用性,包括业务表达层的设计,决定了大量同类思想系统的最终命运。
现状
Ray从一年多前发布到现在,现状是API层以上的部分还比较薄弱,Core模块核心逻辑估计也需要时间打磨。这仅从项目的代码量大致就可以看出来了,目标如此宏伟的系统,主要模块目前一共也就两百多个python文件和不到一百个C++文件。
国内目前除了蚂蚁金服和RISELab有针对性的合作以外(据说是投入了不少资源的重点项目),关注程度还很低,更没有什么实际的应用实例看到,整体来说还处于比较早期的框架构建阶段。
当然,Ray在核心Core模块以上,也开始构建类似Ray RLLib这样的针对增强学习训练算法的上层Library。不过目前看来这些library也是非常基本的概念实现,代码量都不大。当然,也有可能是Core模块足够强大,上层算法策略并不需要写太多代码。不过,不管怎么说,这块显然也是处于早期阶段,需要实践检验和打磨,毕竟,能用和好用,中间还有很长的路。类比Spark中图计算框架的实现,用于实现pregel的几行代码显然和后面的graphx没法同日而语。
至于其它的ML/SQL/Stream/Graph之类的实现,暂时没有看到,理论上Ray目标定位的“灵活的”编程模型,也是可以用来实现这些更高层的编程语义模型的。但实际上,目前现状一方面的原因可能是为时尚早,Ray还没有来得及拓展到这些领域,另一方面,相对于其它计算框架,Ray在这些领域可能也未必有优势。相反的由于Ray的分层调度模型和数据向代码移动的计算模型所带来的全局任务的优化难度,在任务拓扑逻辑图相对固定的场景下,Ray的整体计算性能效率很可能长远来说,也并不如当前这些主流的计算框架。
所以Ray能否成长成为一个足够通用的计算框架,目前我觉得还无法判断,但如果你需要标准化,模式化的解决大量类似增强学习的这种流程复杂的大规模分布式计算问题,那么Ray至少是一种有益的补充,可能值得关注一下,将它和TensorFlow等框架进行局部的结合,让Ray来关注和整合计算处理流程,让其它系统解决各自擅长的问题,可能也是短期内可行的应用方式,Ray自己目前貌似也是朝着这个所谓的混合计算的方向前进的。
相关文档
- 项目文档主页:http://ray.readthedocs.io/en/latest/index.html
- Ray 论文,Ray: A Distributed Framework for Emerging AI Applications (https://arxiv.org/pdf/1712.05889.pdf)
- Ray RLLib 论文:https://arxiv.org/abs/1712.09381
常按扫描下面的二维码,关注“大数据务虚杂谈”,务虚,我是认真的 ;)
