原文链接:这一次,带你搞清楚MySQL的事务隔离级别!
使用过关系型数据库的,应该都事务的概念有所了解,知道事务有 ACID 四个基本属性:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability),今天我们主要来理解一下事务的隔离性。
声明:MySQL专栏学习系列,基本上是本人学习极客时间《MySQL实战45讲》专栏内容的笔记,并在专栏基础上进行知识点挖掘。侵删。
本人也不是什么 DBA,所以有些错误的地方请大家指正,相互交流,共同进步!
什么是事务?
数据库事务(简称:事务)是数据库管理系统执行过程中的一个逻辑单位,由一个有限的数据库操作序列构成。—— 维基百科
事务的概念看上去不难,但是需要注意以下几个点:
1、首先,事务就是要保证一组数据库操作,要么全部成功,要么全部失败;
2、在 MySQL 中,事务支持是在引擎层实现的;
3、并不是所有引擎都支持事务,如 MyISAM 就不支持,InnoDB 就支持;
今天,我们的主角是隔离性,隔离性是指当多个用户并发操作数据库时,数据库为每一个用户开启不同的事务,这些事务之间相互不干扰,相互隔离。
为什么需要隔离性?
如果事务之间不是互相隔离的,可能将会出现以下问题。
1、脏读
脏读(dirty read),简单来说,就是一个事务在处理过程中读取了另外一个事务未提交的数据。
这种未提交的数据我们称之为脏数据。依据脏数据所做的操作肯能是不正确的。
还记得上节中我们提到的 dirty page 吗?这种临时处理的未提交的,都是「脏」的。
举例
| 时间点 | 事务A | 事务B |
|---|---|---|
| 1 | 开启事务A | |
| 2 | 开启事务B | |
| 3 | 查询余额为100 | |
| 4 | 余额增加至150 | |
| 5 | 查询余额为150 |
比如,你给小编赞赏 1 分钱,整个事务需要两个步骤:
①给小编账号加一分钱,这时小编看到了,觉得很欣慰;
②你的账号减一分钱;
但是,若该事务未提交成功,最终所有操作都会回滚,小编看到的一分钱也只是镜花水月。
2、不可重复读
不可重复读(non-repeatable read),是指一个事务范围内,多次查询某个数据,却得到不同的结果。
在第一个事务中的两次读取数据之间,由于第二个事务的修改,第一个事务两次读到的数据可能就是不一样的。
举例
| 时间点 | 事务A | 事务B |
|---|---|---|
| 1 | 开启事务A | |
| 2 | 开启事务B | |
| 3 | 查询余额为100 | |
| 4 | 余额增加至150 | |
| 5 | 查询余额为100 | |
| 6 | 提交事务 | |
| 7 | 查询余额为150 |
接着上一个例子,假设你真给小编打赏了一分钱,小编乐得屁颠屁颠地去准备提现,一查,发现真多了一分钱。
在这同时,在我还没有提现成功之前,小编的老婆已经提前将这一分钱支走了,小编此时再次查账,发现一分钱也没了。

脏读和不可重复读有点懵逼?
二者的区别是,脏读是某一事务读取了另外一个事务未提交的数据,不可重复读是读取了其他事务提交的数据。
其实,有些情况下,不可重复读不是问题,比如,小编提现期间,一分钱被老婆支走了,这不是问题!
而脏读,是可以通过设置隔离级别避免的。
3、幻读
幻读(phantom read),是事务非独立执行时发生的一种现象。
例如事务 T1 对一个表中所有的行的某个数据项做了从“1”修改为“2”的操作,这时事务 T2 又对这个表中插入了一行数据项为“1”的数据,并且提交给数据库。
而操作事务 T1 的用户如果再查看刚刚修改的数据,会发现数据怎么还是 1?其实这行是从事务 T2 中添加的,就好像产生幻觉一样,这就是发生了幻读。
举例
| 时间点 | 事务A | 事务B |
|---|---|---|
| 1 | 开启事务A | |
| 2 | 开启事务B | |
| 3 | 查询id<3的所有记录,共3条 | |
| 4 | 插入一条记录id=2 | |
| 5 | 提交事务 | |
| 6 | 查询id<3的所有记录,共4条 |
其实上面的解释已经是一个例子了,但是还是要举个例子。
比如,小编准备提取你打赏的一分钱,提取完了,这时又有其他热心网友打赏了一分钱,小编一看,明明已经取出了,怎么又有一分钱!?
小编此时以为像做梦一样,我觉得也可以叫「梦读」,哈哈。
幻读和不可重复读都是读取了另一条已经提交的事务(这点就脏读不同),所不同的是不可重复读查询的都是同一个数据项,而幻读针对的是一批数据整体(比如数据的个数)。
事务的隔离级别
为了解决上面可能出现的问题,我们就需要设置隔离级别,也就是事务之间按照什么规则进行隔离,将事务隔离到什么程度。
首先,需要明白一点,隔离程度越强,事务的执行效率越低。
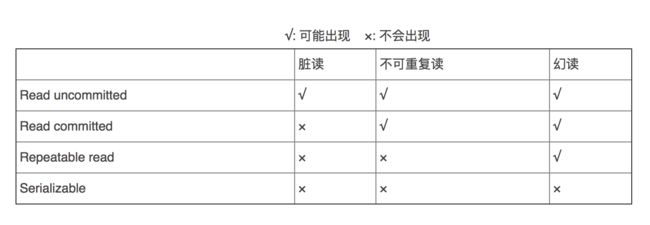
ANSI/ISO SQL 定义了 4 种标准隔离级别:
① Serializable(串行化):花费最高代价但最可靠的事务隔离级别。
“写”会加“写锁”,“读”会加“读锁”。当出现读写锁冲突的时候,后访问的事务必须等前一个事务执行完成,才能继续执行。
事务 100% 隔离,可避免脏读、不可重复读、幻读的发生。
② Repeatable read(可重复读,默认级别):多次读取同一范围的数据会返回第一次查询的快照,即使其他事务对该数据做了更新修改。事务在执行期间看到的数据前后必须是一致的。
但如果这个事务在读取某个范围内的记录时,其他事务又在该范围内插入了新的记录,当之前的事务再次读取该范围的记录时,会产生幻行,这就是幻读。
可避免脏读、不可重复读的发生。但是可能会出现幻读。
③ Read committed (读已提交):保证一个事物提交后才能被另外一个事务读取。另外一个事务不能读取该事物未提交的数据。
可避免脏读的发生,但是可能会造成不可重复读。
大多数数据库的默认级别就是 Read committed,比如 Sql Server , Oracle。
④ Read uncommitted (读未提交):最低的事务隔离级别,一个事务还没提交时,它做的变更就能被别的事务看到。
任何情况都无法保证。
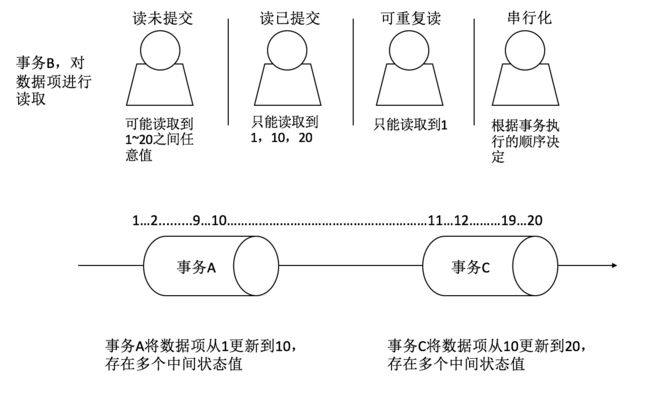
下图中是一个很好的例子,分别解释了四种事务隔离级别下,事务 B 能够读取到的结果。
看着还是有点懵逼?那我们再举个例子。
A,B 两个事务,分别做了一些操作,操作过程中,在不同隔离级别下查看变量的值:
|:-:|:-:|:-:|:-:|:-:|:-:|
|启动事务,查询变量V的值为1|启动事务|||||
||查询V的值为1|||||
||将V的值修改为2|||||
|查询V的值||2|1|1|1|
||提交事务B||||
|查询V的值||2|2|1|1|
|提交事务A||||||
|查询V的值||2|2|2|2|
隔离级别是串行化,则在事务 B 执行「将 1 改成 2」的时候,会被锁住。直到事务 A 提交后,事务 B 才可以继续执行。
再次总结
读未提交:别人改数据的事务尚未提交,我在我的事务中也能读到。
读已提交:别人改数据的事务已经提交,我在我的事务中才能读到。
可重复读:别人改数据的事务已经提交,我在我的事务中也不去读。
串行:我的事务尚未提交,别人就别想改数据。
这 4 种隔离级别,并行性能依次降低,安全性依次提高。
总的来说,事务隔离级别越高,越能保证数据的完整性和一致性,但是付出的代价却是并发执行效率的低下。
隔离级别的实现
事务的机制是通过视图(read-view)来实现的并发版本控制(MVCC),不同的事务隔离级别创建读视图的时间点不同。
- 可重复读是每个事务重建读视图,整个事务存在期间都用这个视图。
- 读已提交是每条 SQL 创建读视图,在每个 SQL 语句开始执行的时候创建的。隔离作用域仅限该条 SQL 语句。
- 读未提交是不创建,直接返回记录上的最新值
- 串行化隔离级别下直接用加锁的方式来避免并行访问。
这里的视图可以理解为数据副本,每次创建视图时,将当前已持久化的数据创建副本,后续直接从副本读取,从而达到数据隔离效果。
隔离级别的实现
我们每一次的修改操作,并不是直接对行数据进行操作。
比如我们设置 id 为 3 的行的 A 属性为 10,并不是直接修改表中的数据,而是新加一行。
同时数据表其实还有一些隐藏的属性,比如每一行的事务 id,所以每一行数据可能会有多个版本,每一个修改过它的事务都会有一行,并且还会有关联的 undo 日志,表示这个操作原来的数据是什么,可以用它做回滚。
那么为什么要这么做?
因为如果我们直接把数据修改了,那么其他事务就用不了原先的值了,违反了事务的一致性。
那么一个事务读取某一行的数据到底返回什么结果呢?
取决于隔离级别,如果是 Read Committed,那么返回的是最新的事务的提交值,所以未提交的事务修改的值是不会读到的,这就是 Read Committed 实现的原理。
如果是 Read Repeatable 级别,那么只能返回发起时间比当前事务早的事务的提交值,和比当前事务晚的删除事务删除的值。这其实就是 MVCC 方式。
undo log
undo log 中存储的是老版本数据。假设修改表中 id=2 的行数据,把 Name='B' 修改为 Name = 'B2' ,那么 undo 日志就会用来存放 Name='B' 的记录,如果这个修改出现异常,可以使用 undo 日志来实现回滚操作,保证事务的一致性。
当一个旧的事务需要读取数据时,为了能读取到老版本的数据,需要顺着 undo 链找到满足其可见性的记录。当版本链很长时,通常可以认为这是个比较耗时的操作。
假设一个值从 1 被按顺序改成了 2、3、4,在回滚日志里面就会有类似下面的记录。
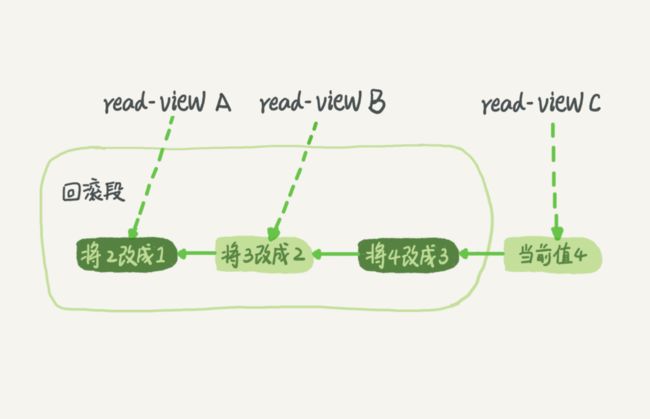
当前值是 4,但是在查询这条记录的时候,不同时刻启动的事务会有不同的 read-view。
如图中看到的,在视图 A、B、C 里面,这一个记录的值分别是 1、2、4,同一条记录在系统中可以存在多个版本,就是数据库的多版本并发控制(MVCC)。对于 read-view A,要得到 1,就必须将当前值依次执行图中所有的回滚操作得到。
同时你会发现,即使现在有另外一个事务正在将 4 改成 5,这个事务跟 read-view A、B、C 对应的事务是不会冲突的。
另外,在回滚段中的 undo log 分为: insert undo log 和 update undo log:
- insert undo log : 事务对 insert 新记录时产生的 undolog,只在事务回滚时需要,并且在事务提交后就可以立即丢弃。(谁会对刚插入的数据有可见性需求呢!!)
- update undo log : 事务对记录进行 delete 和 update 操作时产生的 undo log。不仅在事务回滚时需要,一致性读也需要,所以不能随便删除,只有当数据库所使用的快照中不涉及该日志记录,对应的回滚日志才会被 purge 线程删除。
何时删除?
在不需要的时候才删除。也就是说,系统会判断,当没有事务再需要用到这些回滚日志时,回滚日志会被删除。
就是当系统里没有比这个回滚日志更早的 read-view 的时候。
长事务
直观感觉,一个事务花费很长时间不能够结束,就是一个长的事务,简称长事务(Long Transaction)。
长事务是数据库用户经常会碰到且是非常令人头疼的问题。长事务处理需要恰当进行,如处理不当可能引起数据库的崩溃,为用户带来不必要的损失。
根据上面的论述,长事务意味着系统里面会存在很老的事务视图。
由于这些事务随时可能访问数据库里面的任何数据,所以这个事务提交之前,数据库里面它可能用到的 undo log 都必须保留,这就会导致大量占用存储空间。
在 MySQL 5.5 及以前的版本,回滚日志是跟数据字典一起放在 ibdata 文件里的,即使长事务最终提交,回滚段被清理,文件也不会变小。
除了对回滚段的影响,长事务还占用锁资源,也可能拖垮整个库,这个我们会在后面讲锁的时候展开。
因此,我们要尽量避免长事务。
小结
这一节主要是事务的隔离级别,主要需要记住几个隔离级别、了解一下实现方式。
感觉东西有点乱,涉及了 MVCC 的东西,作者也没有展开,我能力有限,也就没有再深挖。后续,作者在涉及相关知识点时,我们再进行探讨。

最近搜集到传智播客 2018 最新 Python 和 Java 教程!关注本公众号,后台回复「2018」即可获取下载地址。
公众号提供CSDN资源免费下载服务!