机器学习 Scikit Learn
scikit learn website
Choosing the right estimator
Scikit-learn集成了很多机器学习需要使用的函数,Scikit-learn能简洁、快速写出机器学习程序
-
scikit-learn简称sklearn,支持包括分类、回归、降维和聚类四大机器学习算法。还包含了特征提取、数据处理和模型评估三大模块。
 scikit_learn.png
scikit_learn.png
# 数据分割 训练测试集
from sklearn.model_selection import train_test_split
# 数据处理 标准化
from sklearn.preprocessing import StandardScaler
# 分类模型性能评测报告
from sklearn.metrics import classification_report
# 特征转换
from sklearn.feature_extraction import DictVectorizer
# 回归模型评估
from sklearn.metrics import r2_score, mean_squared_error, mean_absolute_error
机器学习
机器学习是设计和研究能够根据过去的经验来为未来做决策的软件,它是通过数据进行研究的程序。机器学习的基础是归纳(generalize),就是从已知案例数据中找出未知的规律。
一般我们将机器学习的任务分为
- 监督学习(Supervised Learning),关注对事物未知表现的预测,分类问题(Classification)和回归(Regression)
- 无监督学习(Unsupervised Learning),对事物本身特性的分析,聚类(Clustering)和数据降维(Dimensionality Reducting)
- 增强学习(Reinforcement Learning),一个能感知环境的自治agent,怎样通过学习选择能达到其目标的最优动作。
-
监督学习问题是,从成对的已经标记好的输入和输出经验数据作为一个输入进行学习,用来预测输出结果,是从有正确答案的例子中学习。
监督学习是通过一个输入产生一个带标签的输出的经验数据对中进行学习。
监督式机器学习任务就是分类 (classification)和回归(regression)- 分类认为需要学会从若干变量约束条件中预测出目标变量的值,就是必须预测出新观测值的类型,种类或标签。
- 回归问题需要预测连续变量的数值,比如预测新产品的销量,或者依据工作的描述预算工资水平等。
-
无监督学习是程序不能从已经标记好的数据中学习。它需要在数据中发现一些规律。假如我们获取了人的身高和体重数据,非监督学习的例子就是把数据点分成组别。
无监督式机器学习任务是通过训练数据发现相关观测值的组别,称为类(clusters)。主要方式是聚类(clustering),即通过一些相似性度量方法把一些观测值分成同一类。数据的相似性
降维(Dimensionality reduction)是另一个常见的无监督学习任务。有些问题可能包含成千上万个解释变量,处理起来非常麻烦。另外,有些解释变量属于噪音,也有些完全是无边的变量,这些影响都会降低程序的归纳能力。降维是发现对响应变量影响最大的解释变量的过程。降维可以更容易的实现数据可视化。对事物特性进行压缩和筛选——数据压缩降维- 聚类应用场景比如有一些影评数据,聚类算法可以分辨积极的和消极的影评。系统是不能给类加上“积极”或“消极”的标签的;没有监督,系统只能通过相似性度量方法把观测值分成两类。聚类分析的应用场景是用市场产品销售数据为客户分级。
监督学习与非监督学习可以看作机器学习的两端。
半监督学习,既包含监督数据也有非监督数据,这类问题可以看作是介于监督学习与非监督学习之间的学习。半监督机器学习案例是一种增强学习(Reinforcement Learning),问题可以通过决策来获得反馈,但是反馈与某一个决策可能没有直接关系。
增强学习就是将情况映射为行为,也就是去最大化收益。学习者并不是被告知哪种行为将要执行,而是通过尝试学习到最大增益的行为并付诸行动。也就是说增强学习关注的是智能体如何在环境中采取一系列行为,从而获得最大的累积回报。通过增强学习,一个智能体应该知道在什么状态下应该采取什么行为。RL是从环境状态到动作的映射的学习,我们把这个映射称为策略。
机器学习三要素:1.模型;2.策略;3.算法
- 公式(方法) = 模型 + 策略 + 算法
模型、参数、目标函数
-
模型 根据不同的业务或使用场景选择合适的模型
 ml_select
ml_select
参数 模型的参数用来让数据更好的适应结果
目标函数也为代价函数,
目标是让代价(错误)最小
而如何找到最优解呢,这就需要使用代价函数来求解了:
目标函数的求解
引出了梯度下降:能够找出cost function函数的最小值;
梯度下降原理:将函数比作一座山,我们站在某个山坡上,往四周看,从哪个方向向下走一小步,能够下降的最快;
当然解决问题的方法有很多,梯度下降只是其中一个,还有一种方法叫Normal Equation;
方法:
- 先确定向下一步的步伐大小,我们称为Learning rate
- 任意给定一个初始值
- 确定一个向下的方向,并向下走预先规定的步伐,并更新
- 当下降的高度小于某个定义的值,则停止下降
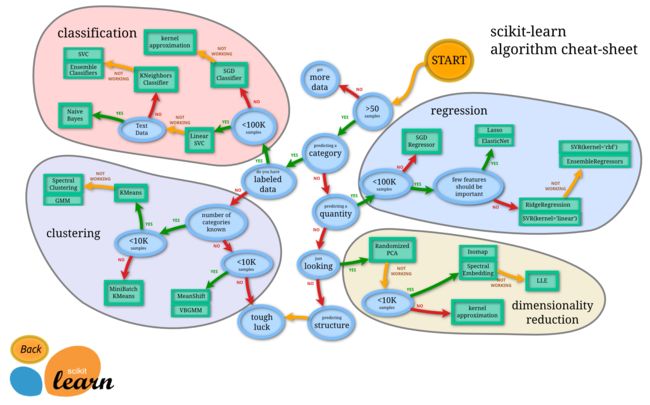
[机器学习算法地图(下图) 摘自"SIGAI"微信公众号]
监督学习 分类——乳腺癌分类案例
监督学习 分类/回归
即根据已有经验知识对未知样本的目标/标记进行预测
据目标预测变量的类型不同,分为分类和回归
流程顺序:
- 获取数据
- 抽取所需特征,形成特征向量(Feature Vectors)
- 特征向量+标签数据(Labels)构成模型所需数据格式
- 数据分割成 训练集,测试集,验证集
- 模型训练,评估验证等
分类
- 二分类(Binary Classification),即判断是非
- 多类分类(Multiclass Classification),多于两个类别中选择一个
线性分类器(Linear Classifiers)
假设特征与分类结果存在某种线性关系
二分类之逻辑回归(Logistic Regression)
也被称为对数几率回归
逻辑回归(Logistic Regression)是用于处理因变量为分类变量的回归问题,常见的是二分类或二项分布问题,也可以处理多分类问题,它实际上是属于一种分类方法。
- 读取数据,查看数据情况 pandas
# 引入所需包
import numpy as np
import pandas as pd
# 使用sklearn.model_selection里的train_test_split模块用于分割数据。得到 训练/测试数据
# http://scikit-learn.org/stable/modules/generated/sklearn.model_selection.train_test_split.html
from sklearn.model_selection import train_test_split
# 创建特征列表, 每列名称
column_names = ['Sample code number', 'Clump Thickness', 'Uniformity of Cell Size',
'Uniformity of Cell Shape', 'Marginal Adhesion', 'Single Epithelial Cell Size',
'Bare Nuclei', 'Bland Chromatin', 'Normal Nucleoli', 'Mitoses', 'Class']
# 使用pandas.read_csv函数读取指定数据
data = pd.read_csv('data/breast-cancer-wisconsin.csv', names = column_names)
# 将?替换为标准缺失值表示,缺失值处理
data = data.replace(to_replace='?', value=np.nan)
# 丢弃带有缺失值的数据
data = data.dropna(how='any')
# 输出data的数据量和维度。
print('数据维度为: {}'.format(data.shape))

-
查看数据具体内容情况
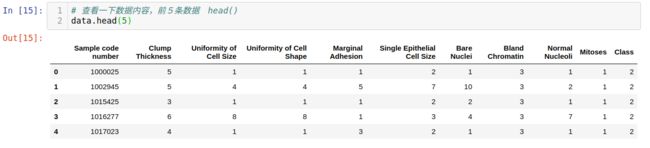 image.png
image.png 将数据切分成 训练集测试集
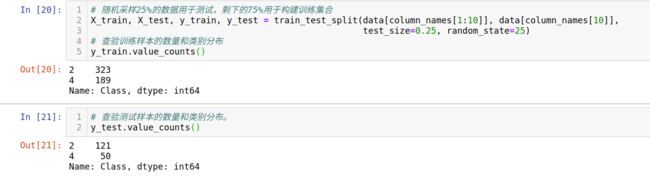
# 随机采样25%的数据用于测试,剩下的75%用于构建训练集合
X_train, X_test, y_train, y_test = train_test_split(data[column_names[1:10]], data[column_names[10]],
test_size=0.25, random_state=25)
# 查验训练样本的数量和类别分布
y_train.value_counts()
- 用逻辑回归进行二分类模型训练及预测并作出性能评测
# 引入 线性分类 进行预测
# 数据先做 标准化处理
from sklearn.preprocessing import StandardScaler
# 引入 逻辑回归 与 随机梯度分类器
from sklearn.linear_model import LogisticRegression
from sklearn.linear_model.stochastic_gradient import SGDClassifier
# 从sklearn.metrics里导入classification_report模块。
from sklearn.metrics import classification_report
# 标准化数据,保证每个维度的特征数据方差为1,均值为0。使得预测结果不会被某些维度过大的特征值而主导。
ss = StandardScaler()
X_train = ss.fit_transform(X_train)
X_test = ss.transform(X_test)
# 实例化分类器
lr = LogisticRegression()
sgdc = SGDClassifier(max_iter=5, tol=None)
# 调用LogisticRegression中的fit函数/模块用来训练模型参数。
lr.fit(X_train, y_train)
# 使用训练好的模型lr对X_test进行预测,结果储存在变量lr_y_predict中。
lr_y_predict = lr.predict(X_test)
# 调用SGDClassifier中的fit函数/模块用来训练模型参数。
sgdc.fit(X_train, y_train)
# 使用训练好的模型sgdc对X_test进行预测,结果储存在变量sgdc_y_predict中。
sgdc_y_predict = sgdc.predict(X_test)
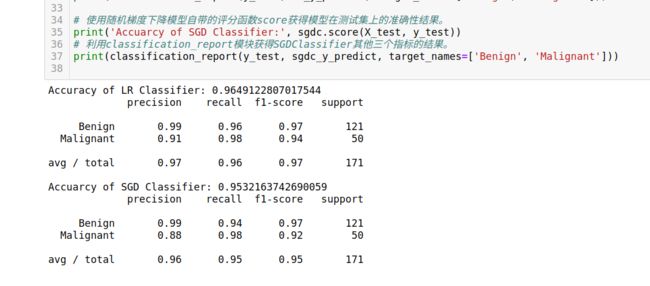
# 使用逻辑斯蒂回归模型自带的评分函数score获得模型在测试集上的准确性结果。
print('Accuracy of LR Classifier:', lr.score(X_test, y_test))
# 利用classification_report模块获得LogisticRegression其他三个指标的结果。
print(classification_report(y_test, lr_y_predict, target_names=['Benign', 'Malignant']))
# 使用随机梯度下降模型自带的评分函数score获得模型在测试集上的准确性结果。
print('Accuarcy of SGD Classifier:', sgdc.score(X_test, y_test))
# 利用classification_report模块获得SGDClassifier其他三个指标的结果。
print(classification_report(y_test, sgdc_y_predict, target_names=['Benign', 'Malignant']))