| 线上产品代码一般是编译过的,前端的编译处理过程包括不限于
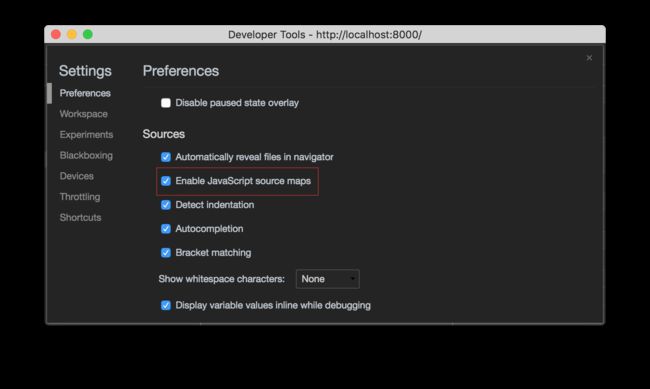
这里提及的都是可生成source map 的操作。 经过这一系列骚气的操作后,发布到线上的代码已经面目全非,对带宽友好了,但对开发者调试并不友好。于是就有了 source map。顾名思义,他是源码的映射,可以将压缩后的代码再对应回未压缩的源码。使得我们在调试线上产品时,就好像在调试开发环境的代码。 来看一个工作的示例准备两个测试文件,一个 log.js function sayHello(name) {
if (name.length > 2) {
name = name.substr(0, 1) + '...'
}
console.log('hello,', name)
}
一个 sayHello('世界')
sayHello('第三世界的人们')
我们使用 npm install uglify-js -g
uglifyjs log.js main.js -o output.js --source-map "url='/output.js.map'"
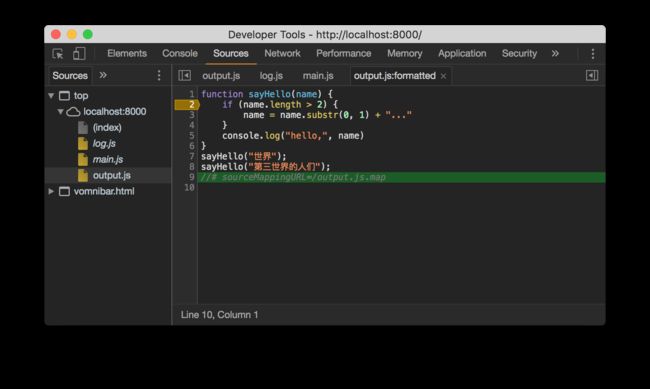
安装并执行后,我们得到了一个输出文件 output.js function sayHello(name){if(name.length>2){name=name.substr(0,1)+"..."}console.log("hello,",name)}sayHello("世界");sayHello("第三世界的人们");
//# sourceMappingURL=/output.js.map
output.js.map {"version":3,"sources":["log.js","main.js"],"names":["sayHello","name","length","substr","console","log"],"mappings":"AAAA,SAASA,SAASC,MACd,GAAIA,KAAKC,OAAS,EAAG,CACjBD,KAAOA,KAAKE,OAAO,EAAG,GAAK,MAE/BC,QAAQC,IAAI,SAAUJ,MCJ1BD,SAAS,MACTA,SAAS"}
为了能够让 source map 能够被浏览器加载和解析,
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>source map demotitle>
head>
<body>
source map demo
<script src="output.js">script>
body>
html>
python3 -m http.server
在浏览器中开启 source map 最后,就可以访问
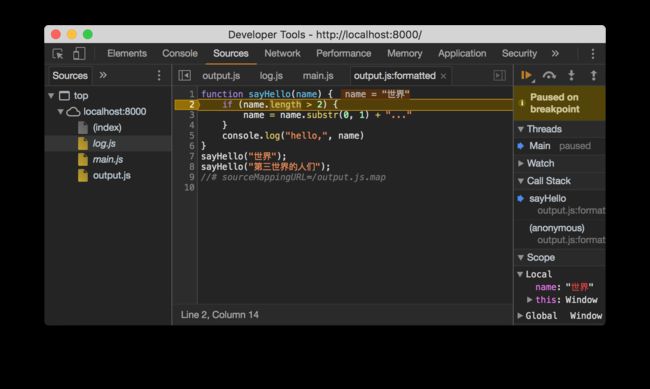
在压缩过的代码中打断点 从截图中可以看到,开启 source map 后,除了页面中引用的 为了测试,我们将 output.js 在调试工具中进行格式化,然后在 刷新页面后,我们发现,断点正确定位到了
代码的还原 会否觉得很赞啊! 下面我们来了解它的工作原理。 我们所想象的 source map将现实中的情况简化一下无非是以下的场景: 上面,输出无疑就是需要发布到产品线上的浏览器能运行的代码。这里只讨论 js,所以输出是 js 代码,当然,其实source map 也可以运用于其他资源比如 LESS/SASS 等编译到的 CSS。 而 source map 的功能是帮助我们在拿到输出后还原回输入。如果我们自己来实现,应该怎么做。 最直观的想法恐怕是,将生成的文件中每个字符位置对应的原位置保存起来,一一映射。请看来自这篇文章中给出的示例: 一个简单的文本转换输出,其中
这里之所以将输入文件也作为映射的必需值,它可以告诉我们从哪里去找源文件。并且,在代码合并时,生成输出文件的源文件不止一个,记录下每处代码来自哪个文件,在还原时也很重要。 上面可以直观看出,生成文件中 (1,0) 位置的字符对应源文件中 (1,5)位置的字符,... 这样确实能够将处理后的文件映射回原来的文件,但随着内容的增多,转换规则更加地复杂,这个记录映射的编码将飞速增长。这里源文件 省去输出文件中的行号大多数情况下处理后的文件行数都会少于源文件,特别是 js,使用 UglifyJS 压缩后的文件通常只有一行。基于此,每必要在每条映射中都带上输出文件的行号,转而在这些映射中插入 可符号化字符的提取这个例子中,一共有三个单词,拿输出文件中 所以,首先我们将文件中可符号化的字符提取出来,将他们作为整体来处理。
于是得到一个所有包含所有符号的数组: 在记录时,只需要记录一个索引,还原时通过索引来这个 所以 可以简化为 同时,考虑到代码经常会有合并打包的情况,即输入文件不止一个,所以可以将输入文件抽取一个数组,记录时,只需要记录一个索引,还原的时候再到这个数组中通过索引取出文件的位置及文件名即可。 所以上面 于是我们得到了完整的映射为: 记录相对位置当文件内容巨大时,上面精简后的编码也有可能会因为数字位数的增加而变得很长,同时,处理较大数字总是不如处理较小数字容易和方便。于是考虑将上面记录的这些位置用相对值来记录。比如(1,1001)第一行第999列的符号,如果用相对值,我们就不用每次记录都从0开始数,假如前一个符号位置为 (1,999),那后面这个符号可记录为(0,2),类似这样的相对值帮我们节省了空间,同时降低了数据的维度。 具体到本例中,看看最初的表格中,记录的输出文件中的位置:
对应到整个表格则是:
然后我们得到的编码为: 注意
VLQ (Variable Length Quantities)进一步的优化则需要引入一个新的概念了,VLQ(Variable-length quantity)。 VLQ 以数字的方式呈现如果你想顺序记录4个数字,最简单的办法就是将每个数字用特殊的符号隔开: 如果如果提前告诉你这些被记录的数字都是一位的,那这个分隔线就没必要了,只需要简单记录成如下样子也能被正确识别出来: 此时这个记录值的长度是原来的1/2,省了不少空间。 但实际上我们不可能只记录个位数的数字,使用 VLQ 方式时,如果一个数字后面还跟有剩余数字,将其标识出来即可。假设我们想记录如下的四个数字: 我们使用下划线来标识一个数字后跟有其他数字: 1234567 所以解读规则为:
VLQ 以二进制方式的方式呈现上面的示例中,引入了数字系统外的符号来标识一个数字还未结束。在二进制系统中,我们使用6个字节来记录一个数字(可表示至多64个值),用其中一个字节来标识它是否未结束(正文 C 标识),不需要引入额外的符号,再用一位标识正负(下方 S),剩下还有四位用来表示数值。用这样6个字节组成的一组拼起来就可以表示出我们需要的数字串了。
第一个字节组(四位作为值) 这样一个字节组可以表示的数字范围为:
* -0 没有实际意义,但技术上它是存在的 任意数字中,第一个字节组中已经标明了该数字的正负,所以后续的字节组中无需再标识,于是可以多出一位来作表示值。
未结束的字节组(五位作为值) 现在我们使用上面的二进制规则来重新编码之前的这个数字序列 先看每个数字对应的真实二进制是多少:
1需要一位来表示,还好对于首个字节组,我们有四位来表示值,所以是够用的。
23的二进制为10111一共需要5位,第一组字节组只能提供4位来记录值,所以用一组字节组不行,需要使用两组字节组。将 10111拆分为两组,后四位0111放入第一个字节组中,剩下一位1放入第二个字节组中。
456的二进制111001000需要占用9个字节,同样,一个字节组放不下,先拆出最后四位(1000)放入一个首位字节组中,剩下的5位(11100)放入跟随的字节组中。
3的二进制为111,首位字节组能够存放得下,于是编码为:
将上面的编码合并得到最终的编码:
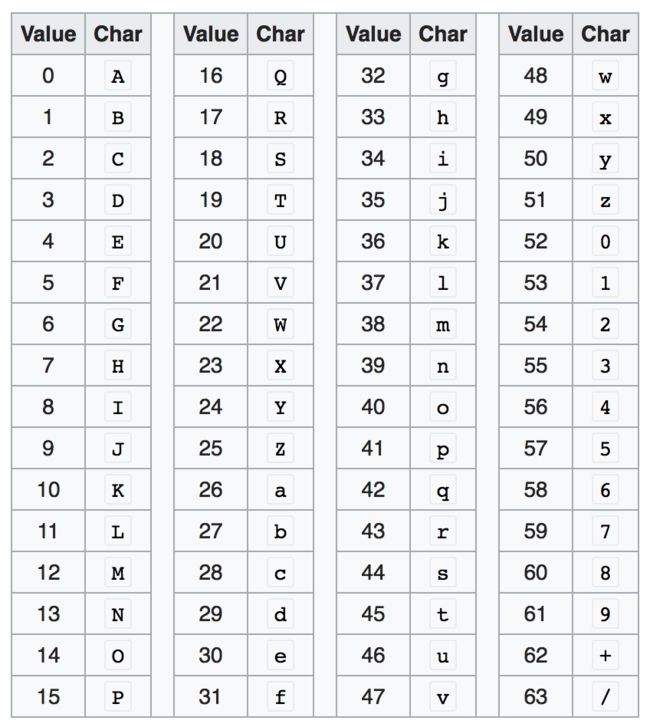
base64 编码表 结合上面的 Base64 编码表,上面的结果转成对应的 base64 字符为: 利用 Base64 VLQ 编码生成最终的 srouce map通过上面讨论的方法,回到开始的示例中,前面我们已经得到的编码为 sources: ['Yoda_input.txt']
names: ['the','force','feel']
mappings (31 字符): 0|0|1|5|0, 4|0|1|4|1, 6|0|1|-9|1;
现在来编码 合并后的编码为: 再转 Base64 后得到字符形式的结果: 后面两串数通过类似的做法也能得到对应的 Base64编码,所以最终我们得到的 source map 看起来是这样的: 而真实的 srouce map 如我们文章开头那个示例一样,是一个 json 文件,所以最后我们得到的一分像模像样的 source map 为: {
"version": 3,
"file": "Yoda_output.txt",
"sources": ["Yoda_input.txt"],
"names": ["the", "force", "feel"],
"mappings": "AACKA,IACIC,MACTC;"
}
略去不必要的字段上面的例子中,每一片段的编码由五位组成。真实场景中,有些情况下某些字段其实不必要,这时就可以将其省略。当然,这里给出的这个例子看不出来。 省略其中某些字段后,一个编码片段就不一定是5位了,他的长度有可能为1,4或者5。
以上,便探究完了 srouce map 生成的全过程,了解了其原理。 如果感兴趣,这个Source map visualizer tool 工具可以在线将 source map 与对应代码可见化展现出来,方便理解。 另外需要介绍的是,尽管 source map 对于线上调试非常有用,各主流浏览器也实现对其的支持,但关于它的规范没有见诸各 Web 工作组或团体的官方文档中,它的规范是写在一个 Google 文档中的!这你敢信,不信去看一看喽~ Source Map Revision 3 Proposal 相关资料
后续
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||