Redis 的特点
- 性能极高 – Redis能读的速度是110000次/s,写的速度是81000次/s 。
- Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
- Redis支持数据的备份,即master-slave模式的数据备份。
- 丰富的数据类型 – Redis支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。
- 原子 – Redis的所有操作都是原子性的,意思就是要么成功执行要么失败完全不执行。单个操作是原子性的。多个操作也支持事务,即原子性,通过MULTI和EXEC指令包起来。
- 高可用和分布式:哨兵机制实现高可用,保证redis节点故障发现和自动转移
- 丰富的特性 – Redis还支持 publish/subscribe, 通知, key 过期等等特性。
Redis 的五种数据类型
string
string 数据类型是最常用、简单的key-value类型,普通的key/value 存储都可以归为此类。value不仅可以是字符串,也可以是数字,图片(base64),对象(序列化);
使用场景 :
做缓存数据的功能 spring-boot-starter-data-redis
存储 session 信息 spring-session-data-redis
做分布式锁 Redisson
# ex:秒级过期时间,nx:键不存在时才能设置成功,xx键存在时才能设置成功 set key value [ex seconds] [px milliseconds] [nx|xx]全局唯一 Id ,这比使用 uuid 会高效,使用的命令为
# key 在每次执行 incr 会增加 1 incr key # 如果应用系统每次获取 id 时,都发一次命令,会对 redis 造成很大的压力,一般的做法是应用系统每次取一定量的 id ,然后存储在本地内存,然后内部使用锁或原子数来增加 incrby key count计数,也是使用 incr 命令;常见的场景有点赞数,阅读数
接口防刷,比如验证码,如果有人用程序不停的调用的你的验证码接口,可以用 redis 的 key 的过期时间解决
# 验证码,单个手机号,一分钟过期 ,一分钟之内只能发送一次 set shortMsg:checkCode:${phoneNum} ex 60 nx
hash
使用场景 :
- hash 可以用来存储结构化数据,比如用户信息
- 非业务表可以使用 hash 来做数据缓存,比如字典表就很符合 hash 的数据结构
list
list 在 redis 中的实现是双向链表,可以在两端进行插入和弹出,还可以在一定范围内取出元素,列表中的元素有序,可重复,是一种比较灵活的数据结构。

使用场景 :
列表数据缓存;
一个项目中的真实案例,有 100 万个装在车上的设备,然后设备的每一段里程都会上报,由另一个部门数据部门进行统计,我们业务部门有一个统计报表需要知道车辆一个时间段内的里程信息,会调用数据部门的接口,由于数据部门的数据是每一小时会保存一份(考虑到最小统计单位是小时),所以如果时间跨度比较大的话,数据部门会有大量的统计比较耗时,当时使用的是 list 做数据缓存,用查询时间段做为 key
阻塞队列
brpop 命令有个特性,可以在有消息的时候弹出,在没有消息的时候阻塞
可以使用 lpush 和 lpop 实现栈
可以使用 lpush 和 rpop 实现队列
set
集合是一种无序,不允许重复元素,很类似于数学中的集合,可以用它来求交集,并集,差集,补集等问题; 相比于 org.apache.commons.collections.CollectionUtils 来说,它对于更大数据量的交集运算会更合适一点。
使用场景 :常用在社交软件中
- 共同关注,共同爱好
- 可能认识的人
zset
排序的集合,不能有重复的元素,而且还可以排序,它和列表使用索引下标作为排序依据不同的是,它给每个元素设置一个分数(score)作为排序的依据,我们可以使用自定义的规则计算一个分值,并分配给元素。
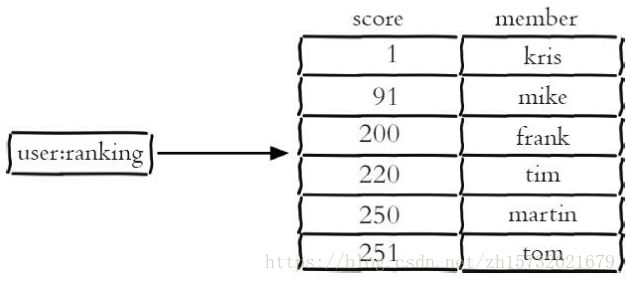
使用场景 :
- 博客排名 ,像 csdn 的排名
- 排行榜,计算统合得分
持久化 AOF 和 RDB
RDB 方式指生成快照的方式,以二进制形式存储全部数据。
AOF 会定时将写入命令追加到 aof_buf 缓冲区,然后使用 sync 异步刷到磁盘。
RDB 持久化方式
执行 bgsave 命令时,redis 进程执行 fork 创建子进程完成持久化,是 save 命令的优化,save 会阻塞当前进程
在 redis-cli 执行 shutdown 命令时,如果没有启 aof ,将自动执行 bgsave
优点:适合于做数据冷备,恢复速度快,文件体积小
缺点:如果两台服务器的 redis 版本不一致,存在兼容性问题,无法实时持久化
相关配置
# 表示在多少秒内,有几次改变,将执行 rdb 持久化; 如果只配置了 save "" 将关闭 rdb 持久化
save
# 是否启用压缩,一般都需要启用
rdbcompression yes
# 数据库文件,默认就行
dbfilename dump.rdb
# 数据文件目录,自已玩默认就行
dir ./ AOF 持久化方式
需要打开配置 appendonly yes
写入命令会追加到一个缓冲区,然后定时向磁盘做 sync 同步
当文件越来越大时需要优化重写 aof 文件来压缩,使用 bgrewriteaof 机制,fork 子进程来进行 aof 文件的重写
redis 重启时可加载 aof 文件进行数据恢复。
优点:实时持久化,可尽可能的恢复数据
缺点:文本格式,体积过大,恢复速度慢
相关配置
# 开启 aof
appendonly yes
# aof 文件名,默认就行
appendfilename "appendonly.aof"
# 每秒一次 flush 操作,默认就行
appendfsync everysec
# 在 aof 文件重写的时候是否不刷数据到磁盘,而是留在缓存区
no-appendfsync-on-rewrite yes
# aof 文件大小比上次重写增加 100% 进行重写
auto-aof-rewrite-percentage 100
# 超过 64m 时进行重写
auto-aof-rewrite-min-size 64mbAOF 文件格式
下面是一个命令的例子,简单的在0 库的一个 set 命令 set sanri mm
*2
$6
SELECT
$1
0
*3
$3
set
$5
sanri
$2
mm- 数据或指令都会独占一行
- * 表示一个命令的开始 ,*2 表示接下来的命令有 2 个占位,select 0
- $6 表示接下来的数据或指令有 6 个字符
基于 aof 的文件格式,可以从数据库导数据到 redis
其实就是拼接成 aof 的文件格式的数据,然后恢复进 redis 库
写好拼装的 sql 脚本,比如 vehicle.sql
执行 sql ,插入redis 的 2 号数据库 ,使用 pipe 方式
mysql -uroot -p123456 newgps --skip-column-names --default-character-set=utf8 --raw < vehicle.sql | redis-cli -a hhxredis --pipe -n 2
具体实现可以参照我的另一篇文章 导出 mysql 数据到 redis
Redis 重启时恢复加载 AOF 和 RDB 的顺序及流程
- 当 AOF 和 RDB 文件同时存在时,优先加载 AOF
- 若关闭了 AOF ,加载 RDB 文件
- 加载AOF/RDB成功,redis重启成功
- AOF/RDB存在错误,redis启动失败并打印错误信息
Springboot 整合 Redis
引入 maven 依赖
org.springframework.boot
spring-boot-starter-data-redis
配置 redis 和连接池
spring.redis.host=192.168.163.100
spring.redis.port=6379
#spring.redis.password=
spring.redis.database=0
# 连接超时时间(毫秒)
spring.redis.timeout=5000
# 连接池最大连接数(使用负值表示没有限制)
spring.redis.pool.max-active=1000
# 连接池最大阻塞等待时间(使用负值表示没有限制)
spring.redis.pool.max-wait=-1
# 连接池中的最大空闲连接
spring.redis.pool.max-idle=10
# 连接池中的最小空闲连接
spring.redis.pool.min-idle=2配置序列化工具
默认情况下,SpringBoot 已经配置好了两个模板工具
RedisTemplate键和值都使用 Jdk 序列化StringRedisTemplate键和值都使用 String 序列化
jdk 序列化存在体积大,还容易因为修改了类的属性而存在反序列化异常,需要一个 serialVersionUID 等问题,一般都自定义序列化工具,常见的序列化工具可以是 fastjson,kryo,Hessian,Protostuff,见文章 序列 化工具性能对比
看网上大多是重新定义 RedisTemplate 类来修改序列化,但个人不建议这么做,你可能把别人用的给打乱了,或者项目已经有旧数据在 redis 上,用的 jdk 序列化,如果改动会造成很大的影响,应该新建一个类,重新在 IOC 容器注册一个新类的实例,来使用新的序列化。相关源码
一点小推广
创作不易,希望可以支持下我的开源软件,及我的小工具,欢迎来 gitee 点星,fork ,提 bug 。
Excel 通用导入导出,支持 Excel 公式
博客地址:https://blog.csdn.net/sanri1993/article/details/100601578
gitee:https://gitee.com/sanri/sanri-excel-poi
使用模板代码 ,从数据库生成代码 ,及一些项目中经常可以用到的小工具
博客地址:https://blog.csdn.net/sanri1993/article/details/98664034
gitee:https://gitee.com/sanri/sanri-tools-maven