果子老师做过一个非常惊人的举动,用DESeq2处理1225例样本的TCGA数据,在没有使用DESeq多线程参数parallel的情况下,跑了将近40个小时。
那么问题来了,在那么大的样本量的情况下,应该用DESeq2进行数据处理吗?我的结论是不应该,DESeq2的适用场景是小样本的差异表分析,降低假阳性。当你的样本量足够多的时候,我们其实有更好的选择。
这里以果子老师的数据为例,来对比DESeq2的结果和我的分析结果进行比较.
加载DESeq2结果
load(file="dds_very_long.Rdata")
library(DESeq2)
deseq2_result <- results(dds)
table(deseq2_result$padj < 0.01)
# FALSE TRUE
# 23997 25072
下面我分析时的数据预处理 部分,
options(stringsAsFactors = FALSE)
# 加载数据
load(file = "BRCA_RNASEQ_exprdf.Rdata")
# 提取表达量矩阵
expr_mt <- as.matrix(expr_df[,-1])
row.names(expr_mt) <- expr_df$gene_id
colnames(expr_mt) <- colnames(expr_df)[-1]
# 根据文库大小标准化
expr_mt <- expr_mt / rep(colSums(expr_mt), each=nrow(expr_mt)) * 1e6
# 过滤地表达基因
expr_mt <- expr_mt[rowSums(expr_mt > 0) > (ncol(expr_mt) / 3), ]
# 统计癌症和癌旁
TCGA_id <- colnames(expr_mt)
table(substring(TCGA_id,14,15))
### 我们发现了7个转移的样本,本次分析,我们关注的是癌症和癌旁,先把转移的样本去掉
### 原发和转移的对比作为家庭作业
TCGA_id <- TCGA_id[substring(TCGA_id,14,15)!="06"]
### 创建metadata
sample <- ifelse(substring(TCGA_id,14,15)=="01","cancer","normal")
sample <- factor(sample,levels = c("normal","cancer"),ordered = F)
metadata <- data.frame(TCGA_id,sample)
下一步,利用非参数检验方法, wilcox.test,关于非参数检验的缘起可以看「女士品茶」的第16章摆脱参数
威尔科克森注释着计算t检验和方法分析的公式,意识到这些不同寻常的极端数值会对结果产生极大的影响,导致“学生”的t检验偏小。 ... 如果异常值体现了某种因素对系统数据的系统性污染,那么使用非参数方法只会让事情变得更糟。
# wilcox.test差异分析 ---------------------------------------------------------
cancer_sample <- metadata[metadata$sample == "cancer", "TCGA_id"]
normal_sample <- metadata[metadata$sample == "normal", "TCGA_id"]
cancer_mt <- expr_mt[,colnames(expr_mt) %in% cancer_sample ]
normal_mt <- expr_mt[,colnames(expr_mt) %in% normal_sample ]
# 计算logFoldChanges
logFC <- log2(rowMeans(as.matrix(cancer_df)) / rowMeans(as.matrix(normal_df)))
library(future.apply)
plan(multiprocess)
p_values <- future_lapply(seq(nrow(cancer_df)), function(x){
res <- wilcox.test(x = cancer_mt[x,], y = normal_mt[x,] )
res$p.value
})
p <- unlist(p_values)
p.adj <- p.adjust(p, method = "fdr")
table(p.adj < 0.01)
# FALSE TRUE
# 10997 24030
我们得到了24,030个校正后p值小于0.01的基因,而DESeq2是25,072个。如果比较全部的基因的话,韦恩图上可以发现,绝大部分基因都是相同的。
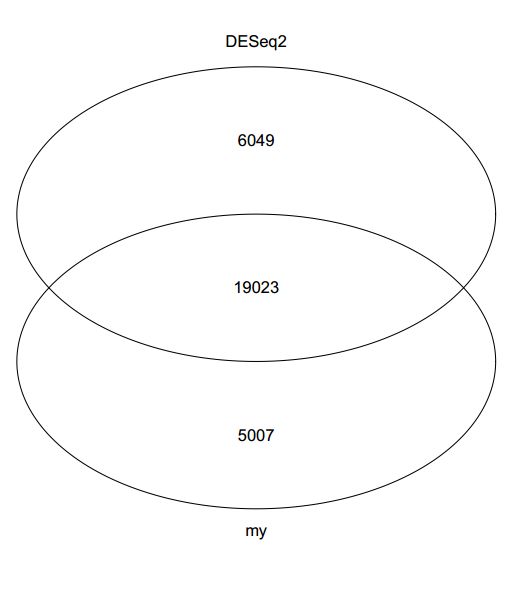
但是通常情况下,我们会更去关注一些变化比较大且p值显著的基因,用这些基因去做下游的富集分析。所以,下一步就是看看后面富集分析结果两者有什么区别。
我们用Y叔的clusterProfiler,去分析倍数变化4倍,矫正p值小于0.01的基因
# 提取基因
library(clusterProfiler)
library(org.Hs.eg.db)
org <- org.Hs.eg.db
diffgene1 <- row.names(expr_mt)[p.adj < 0.01 & abs(logFC) > 2]
diffgene1 <- substr(diffgene1, 1, 15)
diffgene2 <- row.names(deseq2_result)[deseq2_result$padj < 0.01 &
! is.na(deseq2_result$padj) &
abs(deseq2_result$log2FoldChange) > 2]
diffgene2 <- substr(diffgene2, 1, 15)
GO富集分析
library(clusterProfiler)
library(org.Hs.eg.db)
org <- org.Hs.eg.db
diffgene1 <- row.names(expr_mt)[p.adj < 0.01 & abs(logFC) > 2]
diffgene1 <- substr(diffgene1, 1, 15)
diffgene2 <- row.names(deseq2_result)[deseq2_result$padj < 0.01 &
! is.na(deseq2_result$padj) &
abs(deseq2_result$log2FoldChange) > 2]
diffgene2 <- substr(diffgene2, 1, 15)
ego1 <- enrichGO(diffgene1,
OrgDb = org,
keyType = "ENSEMBL",
ont = "BP"
)
ego2 <- enrichGO(diffgene2,
OrgDb = org,
keyType = "ENSEMBL",
ont = "BP"
)
merge_result <- merge_result(list(wilcox=ego1,DESeq2=ego2))
dotplot(merge_result,showCategory= 20 )
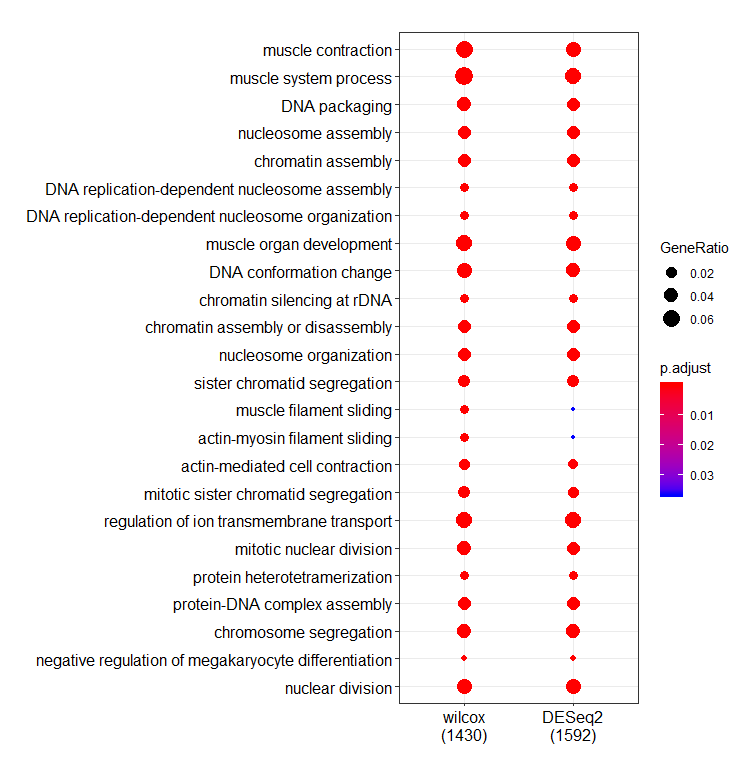
从点图中,你可以认为这两个分析结果是一致。
综上,当你在样本量足够多(两组都不少于10吧),其实没有去用DESeq2这些复杂的工具,用基础的统计学检验方法就能得到很好的结果了。
在样本量比较小的时候,用复杂的模型是无奈之举,它有很多假设成分在,尤其是你还想从无重复的实验设计中算p值。当你样本量够多的时候,用最简单的模型其实就会有很好的结果。
本文还可在http://xuzhougeng.top/阅读
版权声明:本博客所有文章除特别声明外,均采用 知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议 (CC BY-NC-ND 4.0) 进行许可。
