「日常感谢 Andrew Ng 的视频 ! 部分截图来自 udacity 深度学习课程」
第一周-循环神经网络
1.1 序列数据
音频播放的声音是随着时间生成的,所以很自然的被表示为一维时间序列,这样的数据称为序列数据。语言中的单词也是逐个出现的,这样的数据也是序列数据,它们都包含时间的概念。对于这样的序列数据(sequential data)就要用到
RNN(循环神经网络)来处理。
(此部分摘自 Andrew Ng 的第一课--神经网络与深度学习)
1.2 序列模型中的符号表示
在课程中 Andrew 拿识别名字主体的应用来举例,即输入一个句子,能够识别出这个句子中的主体是谁。比如输入的是这样一句话:
Harry Pooter and Hermione Granger invented a new spell.
输入的这个句子作为x,它包含 9 个单词,每个单词可以用x<1>,x<2>,x<3> ... x
还有,要用 Tx 表示输入序列的长度,用 Ty 表示输出序列的长度。这个例子中输入和输出的长度是一样的,都是9。在其他的一些应用中,输入和输出长度会不相同。
总结一下,在多序列训练样本集中,用x(i)
上面讲了序列模型中的符号表示,接下来要讲解单个单词的表示方法以及x
首先要创建词汇表(Vocabulary)或者字典(Dictionary)来存放一系列的单词,每个单词对应一个索引值。之后用one hot 编码来具体表示每个单词。比如,Harry这个单词在字典中存储的位置是4075,对应的x<1>就是一个one hot数组,这个数组的长度就是对应字典或词汇表的长度,其中4075的位置上是1,其余均为0。以此类推,其余单词都可以这么表示。
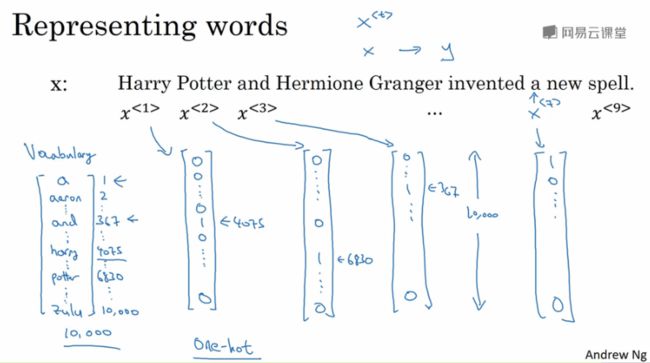
如果有的单词没有出现在字典中,可以创建一个新的token或者用一个假单词(比如:UKN)来表示。
1.3 循环神经网络模型
-
不用SNN(标准神经网络)的原因
1.在自然语言处理的领域中,输入和输出的长度是不一定相等的。不同的例子会有不同的输入输出长度。而SNN对于处理这样的问题有局限性。
2.从文本的不同位置中学到的特征不能共享。这一点在CNN中就有体会。
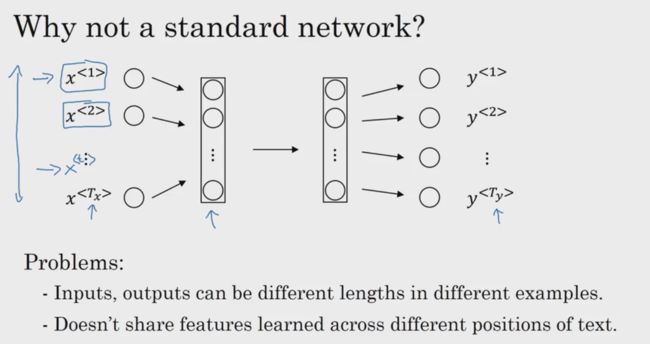
-
RNN结构
对于第一个单词的预测就是将x<1>送进网络,然后输出预测值ŷ<1>;对于第二个单词的预测,不仅接收x<2>,还接收来自第一个时间步长(time step,前面提到语言都是逐个生成的,包含时间的概念,所以会引入time step这个概念,也可以理解成:为逐个生成的单词都盖上专属的时间戳)的激活函数值a<1>或者称为隐藏信息,后面以此类推。这样做能够避免SNN中参数不能共享的缺点,从而对于处理一整句话这种前后关联性很强的数据样本有很强的优势。
整个模型的结构如下图左边所示,通常会在结构的最前面加上第0个时间步长的激活函数值a<0>,作为一个假数据,初始化为全0的向量。在其他一些论文或课程中也有出现右边所示的单个时间步长的结构,这样的结构称为“折叠模型”(Folded model)。所以左边的模型称为“展开模型”(unfolded model)
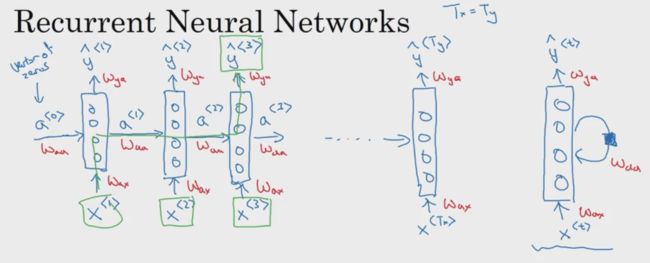
网络中的一些参数:- Wax:表示在每个时间步长中从输入层到隐藏层之间的权重参数
- Waa:表示在每个时间步长中从前往后共享信息之间的权重参数
- Wya:表示在每个时间步长中从隐藏层到输出层之间的权重参数
对于这个结构的缺点就是:
共享的参数是单向传递的(图中所示是从左往右),这样就只能利用句子中前面的信息往后来进行预测而不能利用后面的信息往前作出预测。例如,Teddy不仅可以作为人名,还有泰迪熊的意思,如果不利用后面的信息往前进行预测(获取该序列完整的信息),就无法判断Teddy是人还是玩具。对于这个缺点,提出了双向RNN(BRNN)的结构,在后面的课程中会讲解。 -
RNN中的前向传播
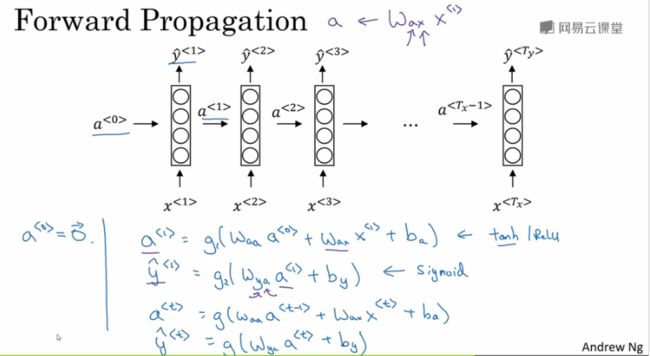
在前面提到过a<0>是个假参数,表示第0个时间步长的激活值,初始化为全0的向量。
对于第一个元素的预测有:
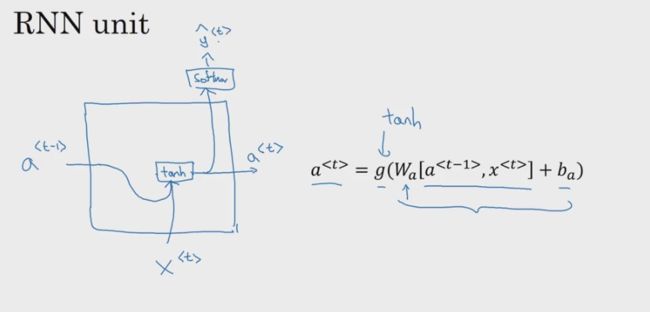
a<1> = g1(waaa<0> + waxx<1> + ba)
ŷ<1> = g2(wyaa<1> + by)
推广至t个元素:
a= g(waaa + waxx + ba)
ŷ= g(wyaa + by)
再简化一点可以表示为:
a= g(wa [a ,x ] + ba),wa为:[waa | wax]
ŷ= g(wy a + ba)
-
RNN中的反向传播
虽然现在的框架提供了很多方便,能够自动计算反向传播,但了解背后的实现原理还是很有必要的。
在计算反向传播之前需要定义损失函数:- 单样本上的损失函数:
L(ŷ , y ) = -y log(ŷ ) - (1-y )log(1-ŷ )
运用这个公式,就可以在每个时间步长上计算单个样本上的损失。 - 全样本上的成本函数:
L(ŷ,y) = ∑(L(ŷ , y ))
计算完单个样本上的损失,再相加得到全样本上的损失总和。

- 单样本上的损失函数:
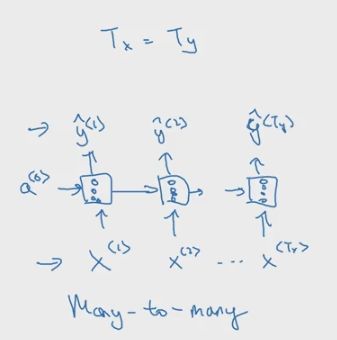
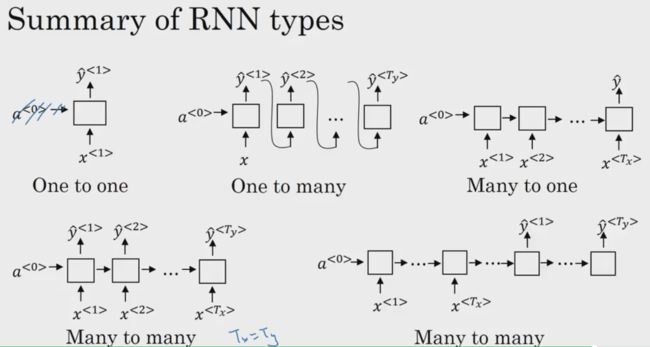
1.4 不同类型的RNN
- many-to-many 模型
之前提到的名字主体识别的应用就是 many-to-many 模型的一个例子,它的输入输出长度是一样的。
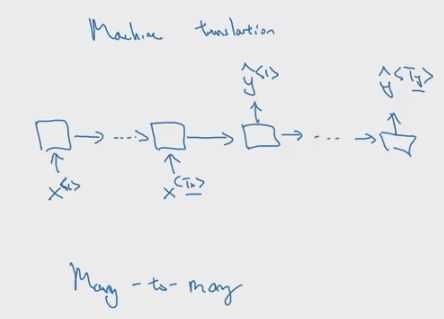
但还有输入和输出长度不一致的情况,比如在机器翻译领域中,将中文翻译成英文,这时候因为语言的差异,输入输出的序列长度就会不一致。
-
many-to-one 模型
情感分类系统就是many-to-one模型,在网上完成一句或者一段话的评论,该系统就会根据输入的内容进行分类,输出一个0-5之间的整数评分。
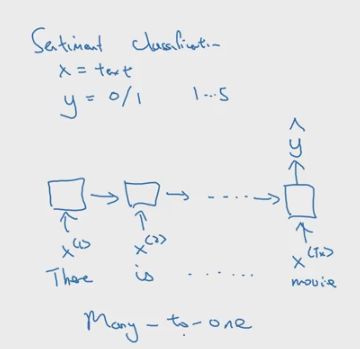
-
one-to-many 模型
音乐生成采用的就是one-to-many模型,比如输入一个整数,模型会根据这个整数输出一段音乐,但前一个输出的预测值也会被用于下一个预测中。
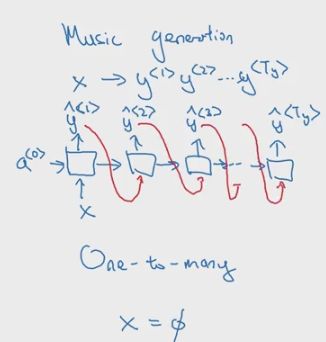
-
汇总
1.5 语言模型和序列生成
- 什么是语言模型
在语音识别中,对于输入两个相似发音的句子,通常会用语言模型来分别判断输出这两个句子的概率,概率高的句子就会被输出。所以语言模型的基本工作就是对于输入的任何句子(一系列的序列)进行概率判断。 - 构建一个语言模型
首先要准备数据集:大量的英文文本(或者其他语言的文本)的语料库corpus(是NLP自然语言处理领域的专业术语)
其次要做的就是对文本进行Tokenize令牌化,即在创建的字典或词汇表中,对每个单词分别进行one hot 处理(1.2节中提到的方法)。还有一点常规的做法是在句末添加一个额外的EOS(End Of Sentence)token,表示一个句子的结束。在进行Tokenize的时候,也要考虑是否将句号等标点符号也作为一个token。对于没有出现在字典或词汇表中的单词,则添加UKN作为token。
-
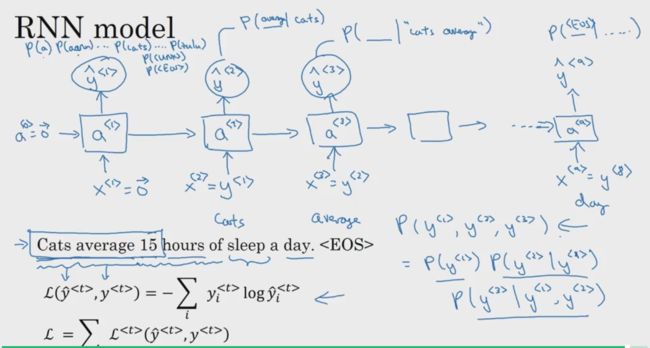
然后构建基本的RNN模型
下面构建的RNN中,单个序列的输入为:x= y
对于第一个输入x<1>,将其初始化为全0的向量,a<0>也做同样的初始化,在输出层添加softmax激活函数,计算存储在字典中的单词的概率,并分清最有可能出现的第一个单词。如果字典中存储了10000个单词,这个softmax函数的输出的维度就有10000。
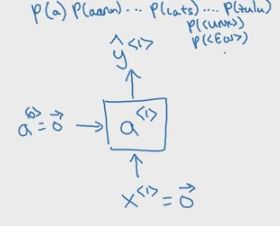
对于第二个输入x<2> = y<1>,y表示实际值(理论值),拿图片上的例子说明就是'cats'这个正确的单词。计算预测值ŷ<2>就是在已知第一个单词是‘cats’的条件下计算其他单词出现的概率。后面的过程以此类推。计算完预测值,再计算损失,并用之来训练网络。
根据上面的过程,可知RNN学会的是从前往后依次地预测单词出现的情况。
1.6 抽样新的序列
- 从已训练的RNN中采样生成新序列
从已训练的RNN中采样,就是把前一个时间步长产生的预测值当成下一个时间步长开始的输入值。操作流程如下图所示: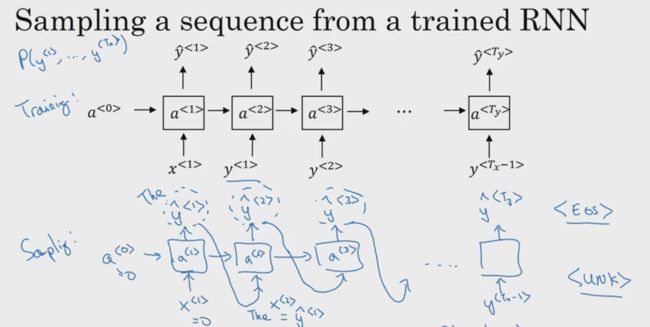
-
字符级语言模型
前面讲到的都是词级语言模型(word-level language model),现在引入字符级语言模型的概念(character-level language model)。字符级语言模型不再是创建包含单词的字典而是创建包含大小写字母,标点,空格等元素的字典。又因为每个单词都是由字母组成的,这时候就无需像词级语言模型一样另外为字典中不包含的单词和标点创建Token。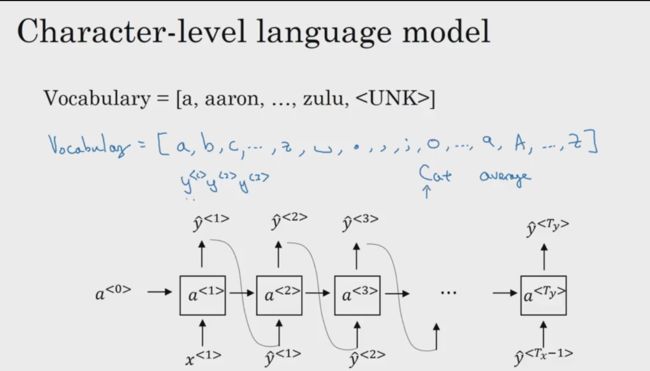
但是字符级序列的模型的主要缺点是:
组建的序列往往会很长,比如一个句子只由十几个单词组成,却会包含许多的字符。所以这会造成字符级语言模型在获取长范围的句子前后依赖关系上比不上词级语言模型,并且在训练时会很耗费计算。
1.7 RNN的梯度消失
RNN在训练时,也会遇到和训练深层神经网络时一样的问题--会出现梯度消失或者梯度爆炸。对于梯度爆炸比较容易解决,对模型重新进行梯度修剪就能避免问题,下图是梯度修剪实施的过程。但对于解决梯度消失问题比较困难。下面提到的GRU和LSTM是能有效解决梯度消失的方法。实施过程有点复杂。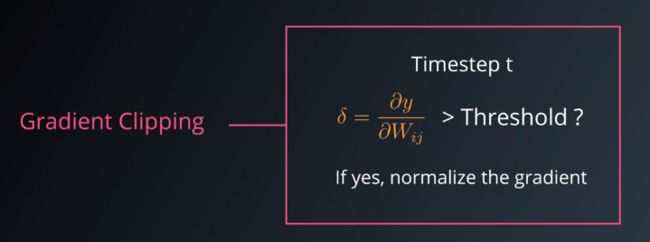
1.8 门循环单元(GRU)
GRU(Gated Recurrent Units)门循环单元是组成RNN隐藏层的部分,不仅能够帮助RNN更好地捕获长范围的连接关系,还对梯度消失问题有帮助。
-
GRU的简略版
在GRU中,提出memory cell(记忆细胞)的概念,用c来表示。记忆细胞的作用就是记住一些需要记忆的信息。
在GRU的概念中,c= a ,即记忆细胞的值是和激活函数的输出值相等的。但在后面的LSTM概念中,两者是有区别的。
在每个时间步长中,我们重新定义一个候选项:˜c= tanh(wc[c , x ] + bc)
接着有:Γu (0<Γu<1)= σ(wu[c, x ] + bu),这是在GRU中一个很重要的概念--更新门update gate,下标u表示update的意思,有时也用Gu表示。因为Γu 取0到1的范围,所以用上sigmoid激活函数来使计算结果在0到1的范围内。 在具体操作中,用˜c
来更新c ,用Γu来决定是否要更新c 或者什么时候更新c 。即用下面这个公式ct = Γu * ˜c + (1-Γu) * c ,当Γu=1时,c 更新为备选项˜c ;当Γu=0时,c = c
更新门可以控制过去的信息在当前时刻的重要性。如果更新门一直近似1,过去的信息将一直通过时间保存并传递至当前时刻。GRU的这个设计可以应对RNN中的梯度衰减问题,并且更好地捕获长范围内前后信息的依赖关系。 -
RNN单元和GRU单元的可视化
- RNN:
- GRU:

- RNN:
-
GRU的完整版
在上面简略版的基础上再加入一个gate--Γr(r表示relevance),表示前后信息的关联性。˜c
= tanh(wc[ Γr * c , x ] + bc)
Γu = σ(wu[ c, x ] + bu)
Γr = σ(wr[ c, x ] + bu)
c= Γu * ˜c + (1-Γu) * c
a= c 候选项˜c
的公式中包含Γr * c ,说明这个门控制了上一时刻传递的信息的流入。如果Γr近似为0,c 将被丢弃,即上一时刻传递的信息会被抛弃。
(因为这个操作,Amazon的动手学深度学习课程中也称这个门为重置门(reset gate))。
因此,Γr门提供了丢弃与未来无关的过去信息的机制。对门控循环单元的设计稍作总结:
Γr门有助于捕捉序列数据中短期的依赖关系。
Γu门有助于捕捉序列数据中长期的依赖关系。
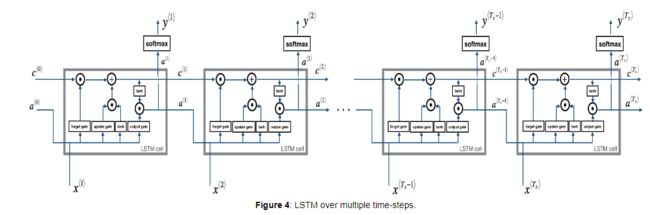
1.9 长短时记忆(LSTM)
LSTM比GRU复杂,它使用了三个gate。且在LSTM(Long Short Term Memory)中,c
候选细胞:
˜c
update gate(更新门):
Γu = σ(wu[ a
forget gate(遗忘门)::
Γf = σ(wf[ a
output gate(输出门):;
Γo = σ(wo[ a
记忆细胞:
c
从此式子上可以看出计算当前记忆细胞结合了上一时刻记忆细胞和当前时刻候选记忆细胞的信息,并通过遗忘门Γf 和更新门Γu 来控制信息的流动。当Γf 近似1而Γu 近似0时,过去时刻的信息一直通过时间保存下来,而当前信息则被丢弃遗忘。
传入下一时刻的激活值(或者称为隐藏信息):
a
从此式子上可以看出,隐藏信息的流动取决于输出门Γo ,当Γo 近似为1时,信息被传递到下一时刻;当Γo 近似为0时,细胞信息自己保留。
实现步骤如下图所示:
LSTM的工作机制如下图所示:

1.10 双向RNN
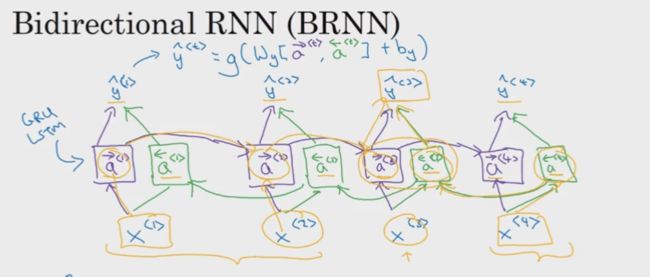
双向RNN是在单向RNN的基础上,添加一个反向循环层,如下图绿色线所表示。
正向层是从左往右,从x<1>往x
虽然BRNN解决了RNN的缺点,但它同时也带有需要知道全部信息才能反向向前预测的缺点。
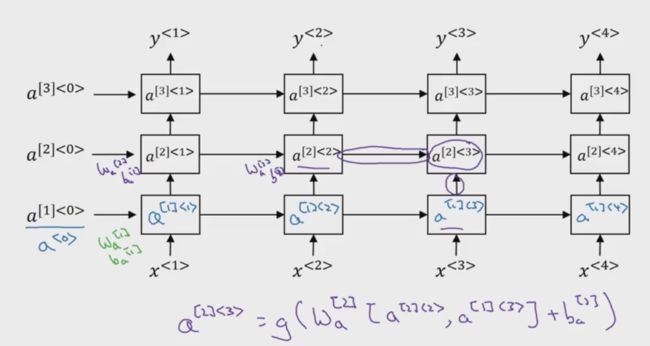
1.11 深层RNN
第二周-自然语言处理与词嵌入
2.1 介绍词嵌入
2.1.1 词汇表示
one-hot 表达的不足
第一周的课程中,用 one-hot 向量来表示字典中的每个单词,但这样做会把每个单词当成一个独立的事件看待。并且不能把同类单词的关系联系起来,造成很难找到一个算法对交叉词汇进行一般化。-
特征化表示:词嵌入(word embedding)
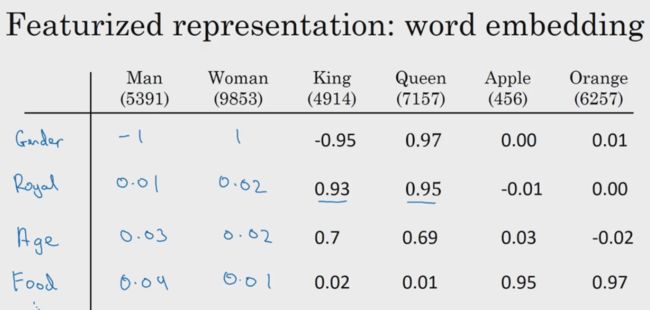
为了解决上述 one-hot 向量表达的缺点,提出了特征化表达,即词嵌入的概念。具体做法就是,列出一系列的特征,对应单词符合该特征就给予(正负)高概率,不符合该特征就给予(正负)低概率。根据这么多的特征,一个单词就会对应有很多的概率,就用这些概率把单词表示成向量,如果该单词在字典中的排列位子是5391,该单词就表示为 e5391。按照这样的特征化表示方法,可以发现同类词,对应的向量取值大致相同。这样算法也就能够把它们归为一个事件。
-
词嵌入的可视化
将上面的特征化表示方法中的多维向量嵌入到二维的平面内,可以使用 t-SNE。在这个二维平面中,同类的单词会集聚在一起,不同的单词会相隔较远。
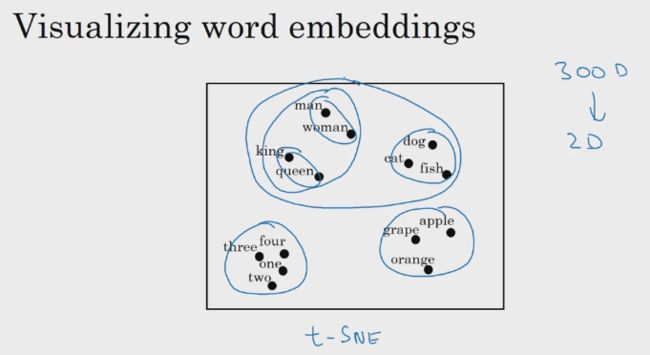
把表示单词的高维度向量表示成二维平面或者三维立体面上的一个个点,这也是 word embedding 名字的由来。
Is "embedding" an action or a thing? Both. People talk about embedding words in a vector space (action) and about producing word embeddings (things). Common to both is the notion of embedding as a mapping from discrete objects to vectors. Creating or applying that mapping is an action, but the mapping itself is a thing.
From - TensorFlow embedding
2.1.2 词嵌入的特性
-
类比推理(analogy reasoning)
类比推理能够帮助我们理解词嵌入在做的是什么以及词嵌入能够做什么。在下面这张图中,man和woman是一对相反词,那么如何类比出king和queen也是一对相反词呢?做法就是将man和woman的向量相减,将king和queen的向量也相减,得到的值是近似的,就可以认为king和queen也是一对相反词。利用这个原理可以将eman - ewoman ≈ eking - e?,已知左边的值就可以推理出king的相反词是什么。

-
用词向量来类比
已知eman - ewoman ≈ eking - e?,要找出e?代表什么向量。首先需要求解出相似的词向量,然后将其最大化。
简略表示就是:argmax sim(e?,eking - eman + ewoman)

-
余弦相似cosine similarity
上面sim方法就是采用余弦相似方法,求解原理如下所示。

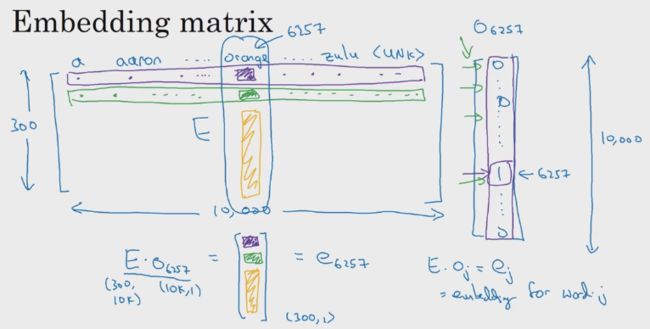
2.1.3 嵌入矩阵
所谓的嵌入矩阵,就是横轴对应的是字典中的单词,竖轴对应的是每个单词的词嵌入向量。每个单词的词嵌入向量可以用嵌入矩阵E和该单词对应的one-hot向量进行矩阵相乘求解,即E·oj = ej
(但在实际实践中,由于one-hot向量是高维度的向量且包含大量的0元素,上面这样的做法并不高效。所以会采用专门的函数来寻找词嵌入向量。)
2. 2 学习词嵌入:Word2Vec&GloVe
2.2.1 学习word embeddings
- Neural language model
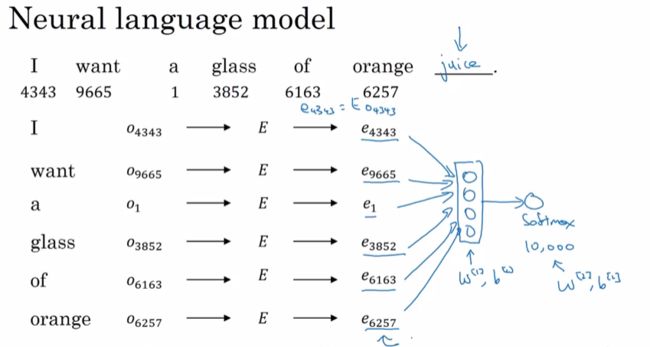
首先来讲用神经网络来建立语言模型,在训练的时候,希望神经网络能够根据输入的语句来预测后面的的单词。比如,输入下面的这句话:I want a glass of orange ▁▁▁▁ . 神经网络能够根据前面的输入,预测出空格的单词。
要得到每个单词对应的词嵌入向量,就需要把上面句子中的每个单词的one-hot向量和参数嵌入矩阵E进行矩阵乘积。得到每个单词的词嵌入向量后,把这些向量送入神经网络,接着送入softmax层输出预测。(softmax层输出的数据的维数和设定的词汇表的维度是一样的)
实际上更普遍的做法是设定一个固定来历的窗口(fixed historical window),继续拿上面的例子来讲,就是给出空格前的四个单词进行预测。这里给定的四个单词是算法的超参数,所以可以调整为或长或短的序列,或者决定总是取空格前的四个单词。接着只用表示出这四个单词的词嵌入向量,然后送入网络进行训练。使用固定的来历,就意味着你可以解决任意长的句子,因为输入的大小总是固定的。这是在学习词嵌入中早期的一个比较成功的算法。不限于前四个单词,还可用取前后分别四个单词或者前一个单词或者邻近的一个单词。
skip-grams模型就是上面所述的一种学习词嵌入的方法,下面会继续对这个模型进行讲解。
2.2.2 word2vec的两种模型
word2vec是Google团队在2013年发表的一个工具。word2vec主要包含两个模型,一个是跳字模型(skip-gram model),还有一个是连续词袋模型(continuous bag of words,简称CBOW)。在实际实践中主要运用skip-gram模型,因为其效果比 CBOW模型要好。在这里也主要针对skip-gram模型进行讲述。
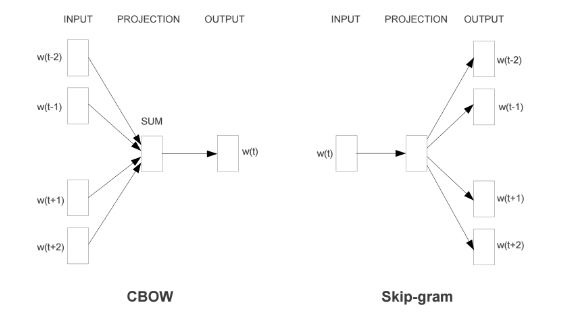
- Skip-gram model
在skip-gram模型中,我们用一个词来预测文本序列中它周围的词。例如,给定文本序列”i”, “want”, “a”, “glass”, “of”, “orange”和”juice”,skip-gram模型所关心的是,给定”orange”一词,生成它邻近词“i”, “want”, “a”, “galss”,“of”和”juice”的概率分别是多少。- 数据
在讲skip-gram的网络模型前,先讲讲它的输入数据。为了训练skip-gram模型,我们建立监督学习问题,从训练集中寻找单词对(word pairs)喂入模型。寻找单词对的时候会设置一个skip window,这是我们将要寻找的选定单词前后位置的单词数量。拿下面这句话来举个例子:I want a glass of orange juice . 设置window_size =2 。当input word为 I 时,会选出[I, want, a],训练样本为(I, want)和(I, a);当input word为 want 时,会选出[I, want, a, galss],训练样本为(want, i),(want, a)和(want, glass);当input word为 a 时,会选出[I, want, a, galss, of],训练样本为(a, i),(a, want),(a, galss),(a, of)。 - 模型
skip-gram模型实际上是非常简单的。如下图绿框线所示,先把one-hot向量oc和嵌入矩阵E矩阵相乘得到词嵌入向量ec,然后送入softmax层输出预测ŷ。
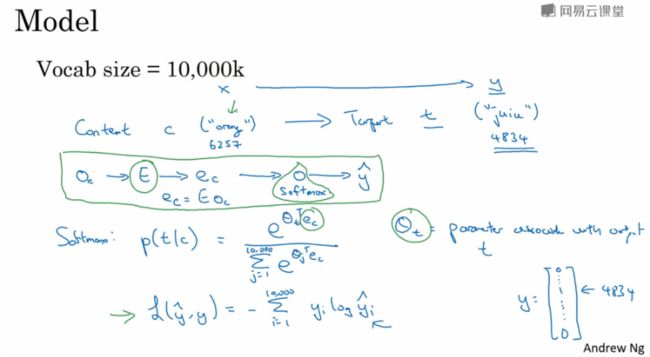
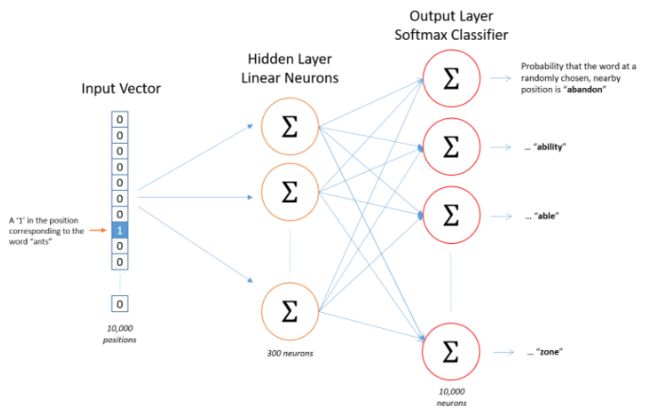
更直观的理解在下图,把之前的one-hot向量和嵌入矩阵E相乘的的过程当成是把one-hot向量输入到隐藏层,隐藏层表示的权重矩阵就是词嵌入矩阵E。把一个one-hot向量输入隐藏层得到一个词嵌入向量。所以隐藏层所起的作用就是一个寻找表(lookup table)。经过隐藏层得到每个词的词向量后,送入softmax层输出预测的概率。
- 数据
- CBOW model
CBOW模型与skip-gram模型最大的不同是,CBOW模型中是用一个中心词周围的邻近词来预测该中心词。例如,给定文本序列”i”, “want”, “a”, “galss”, “of”和”juice”,CBOW模型所关心的是,邻近词“i”, “want”, “a”, “galss”,“of”和”juice”一起生成中心词”orange”的概率。
2.2.3 负采样
前面提到的skip-gram模型存在一个缺点就是softmax计算起来很慢。而负采样是一种新的和skip-gram类似的但比较高效的模型。
- 数据
跟skip-gram模型一样,从训练集中选取一系列的单词对(word pairs)喂入模型。但不同的是,如下图所示,会给选取的 target words 添加labels,且会把真正的 target word 放在首行(首位),称为正样本,其label为1。其余的候选的 target words 和选取的中心词(图中为orange)构成负样本, label为0。这里会引入一个参数k,表示负采样k次,在小数据集上采用5-20范围内的数;在大数据集上则采用2-5范围内的数字。即数据集越小,k选值越大。(来自Mikolov等人的推荐)

如何采集负样本:
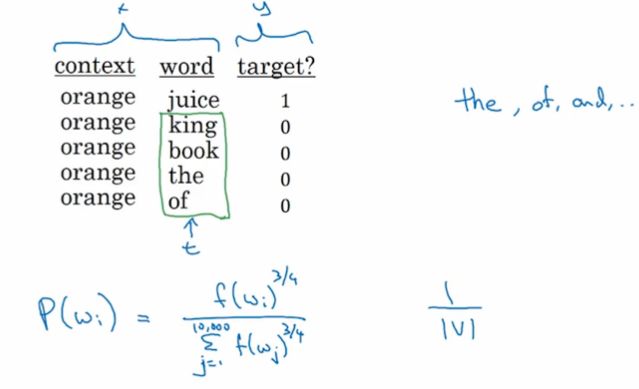
- 第一种方法是采用经验概率:即通过词出现的概率对其进行采样。但这种方法会存在弊端,因为会存在the,of,and等这些高频无用词。
(对于高频无用词的处理方法是进行subsampling,这也是论文作者Mikolov等人提出的方法。我记录在这篇笔记里) - 第二种方法是采用均匀分布:即用1/|vocab_size|,均匀且随机的抽取负样本。但这对于英文单词的分布是非常没有代表性的。
- 第一种方法是采用经验概率:即通过词出现的概率对其进行采样。但这种方法会存在弊端,因为会存在the,of,and等这些高频无用词。
所以在这两个极端中,Mikolov等人根据经验提出了一个效果非常好的方法,即对词频 f(wi) 计算其 3/4 次方,再除以整体的值:
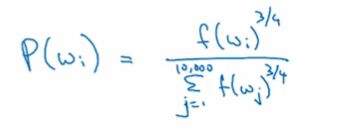
-
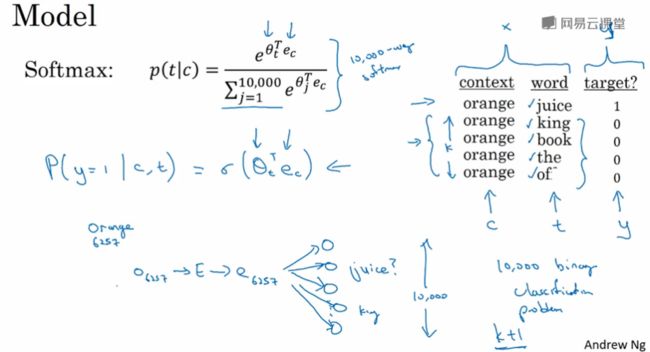
模型
在数据集中,我们把选定的context记为c,target words记为t,label记为y。模型所要做的就是根据提供的 c 和 t ,来求 y = 1 的概率。此处运用sigmoid函数,所以搭建的模型类似logistic回归分类模型。搭建的具体模型如下图所示,先输入一个词的one-hot向量,输入隐藏层求出对应的词嵌入向量,最后送入输出层运用sigmoid激活函数进行logistic回归分类。假如词汇表中有10000个单词,最后一层的分类器也有10000个,但每次训练迭代的时候只用输入采用的正负样本就可以,图中所示只用输入5个单词训练即可,这样大大的减少了计算量。所以负采样模型所做的就是,把softmax计算10000维的问题,转换为10000个二元分类问题,且每一个的计算都十分简单。
2.2.4 GloVe(Gloabal vectors for words representation)
2.3 应用词嵌入
2.3.1 情感分类
2.3.2 消除偏见
在word embedding的应用中,可以类比出相似或同类的词。但在用文本训练模型的过程中,会出现很多非预期类型的偏见,比如性别歧视,种族歧视,年龄歧视等等。在生活中,很多地方会应用机器学习的方法来做决策,比如学生录取,银行贷款,司法系统考试等等。如果在其中存在各种偏见的话,会对结果产生很大的不良影响。所以修改学习算法使其尽可能减小或者理想化消除这些偏见是十分重要的事情。

拿性别歧视来举例,怎么解决偏见问题,这个方法在其他的偏见中都是通用的。

详细内容参见 这篇paper
第三周-序列模型和注意力机制
3.1 sequence to sequence 结构
3.1.1 基础模型
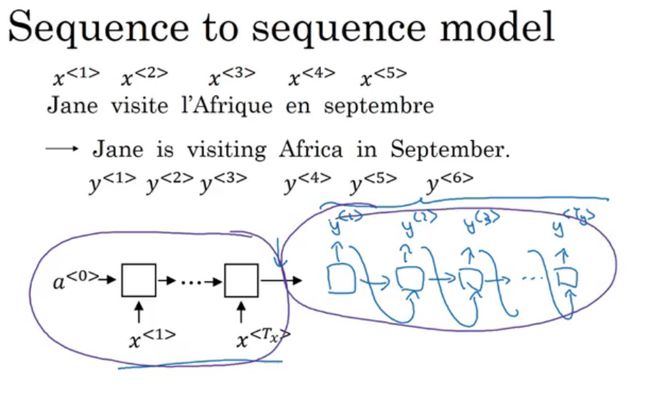
基础的模型结构如下所示。课程中以一个例子来说明这个模型。这个例子是一个语言翻译的例子。输入一句法语,模型会输出英文的翻译。我们对输入的 5 个法语序列,分别标以 x<1>,x<2>...x<5>;对应的输出序列为 y<1>,y<2>.....y<6>。对输入序列构建一个由 RNN 构成的编码器(Encoder)网络。每次向模型喂入一个法语单词,然后模型通过理解输入序列的内容,会输出一个向量来表示输入序列。在此之后,建立一个解码器(Decoder)网络。输入序列经过网络模型的训练,按一次一个单词的顺序,将翻译结果输出。图中的方块对应的 GRU 或者 LSTM 单元。
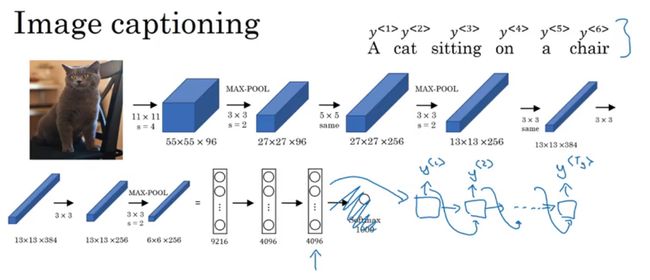
这个由编码器和解码器构成的模型也通常用于图片标注,如下图所示,通过识别图片,然后输出对应图片的文字描述。这个模型借鉴了经典的 AlexNet 模型,将最后的 softmax 层去掉,连接上一个由 RNN 构成的解码器网络。因为前面的 CNN 模型最后输出了一个 4096 维的特征向量,其为图片的编码表示 。也就相当于是前面的 CNN 模型部分就相当于是一个编码器网络。该模型在输出文字不长时,表现还算良好。
上面就是基本的 seq2seq 模型。但这样的模型与语言模型合成文本来说还是有很大区别的。关键在于这个基本模型输出的可能是一个随机序列或者一个随机的图片描述。
3.1.2 选择最可能的句子
- 机器翻译
我们可以把机器翻译当成是一个有条件的语言模型。在下面的图片中,可以发现机器翻译的模型和语言模型很相似,绿色整个编码器的部分可以看做是语言模型的输入,后面解码器的构造和语言模型的构造一模一样。所以,这也就是可以把机器翻译当成是一个有条件的语言模型。写作概率形式就是 p(y1,y2,y3....|x1,x2,x3...),表示输入法语的句子,输出为英语翻译的概率。
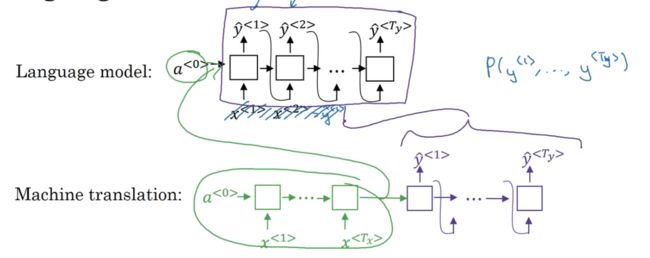
- 贪婪算法
如果要把上述的机器翻译模型应用到现实中去,可能会得到很多的随机的翻译结果,然而并不能使用全部的翻译结果,所以这时候就会求助于贪婪算法来选取最优的翻译结果来输出一个结果。
3.1.3 Beam Search 算法
Beam Search 就是帮助机器翻译选取最优结果的一种算法,该算法同样适用与语音翻译。
3.1.4 优化 Beam Search
3.1.5 Beam Search 中的误差分析
3.1.6 Bleu Score
3.1.7 Attention Model 的直观理解
3.1.8 Attention Model
3.2 语音识别 - 音频数据
3.2.1 语音识别
3.2.2 触发词检测
扩展阅读:
1.动手学深度学习 - by gluon.ai
2.Understanding LSTM Networks - by colah
3.Exploring LSTMs的中文翻译版详解LSTM:神经网络的记忆机制是这样炼成的
4.Word2Vec Tutorial - The Skip-Gram Model - by Chris McCormick
5.Word2Vec (Part 1):(Skip-gram) - by Thushan Ganegedara
6.Word2Vec paper - by Google