Kotlin 源代码编译过程分析
正式上架:《Kotlin极简教程》Official on shelves: Kotlin Programming minimalist tutorial
京东JD:https://item.jd.com/12181725.html
天猫Tmall:https://detail.tmall.com/item.htm?id=558540170670
我们知道,Kotlin基于Java虚拟机(JVM),通过Kotlin编译器生成的JVM字节码与Java编译的字节码基本相同,也因此与Java可以完全兼容,并且语法更加简洁,让我对Kotlin的编译过程甚是好奇。一通Google之后,毫无收获,Kotlin作为一门新语言,绝大多数的资料都局限于它的用法和特性相关。幸好Kotlin所有源码都已开源,遂决定生啃之。
Kotlin源码传送门:https://github.com/JetBrains/kotlin
在具体讲Kotlin编译过程之前,我们先来看一张图。
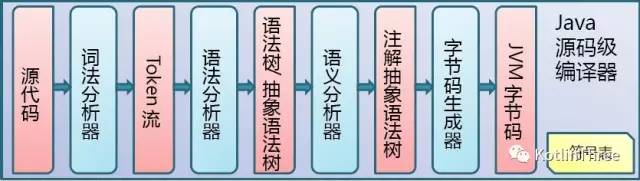
上图是Java编译器的编译过程,正如它们俩完全兼容的特性一样,等分析完Kotlin的编译过程,你会发现,Kotlin和Java的编译过程也是很相似的。
- 编译入口
整个Kotlin工程代码达到200多MB,面对如此巨大的项目,我们需要找一个入口来进行逐步深入。所以,我们从最简单直观的入手,来看一下Kotlin的编译命令:
kotlinc Hello.kt
打开kotlinc
脚本文件看执行了什么,代码如下:
$ cat /Users/jack/soft/kotlinc/bin/kotlinc
#!/usr/bin/env bash
#
##############################################################################
# Copyright 2002-2011, LAMP/EPFL
# Copyright 2011-2015, JetBrains
#
# This is free software; see the distribution for copying conditions.
# There is NO warranty; not even for MERCHANTABILITY or FITNESS FOR A
# PARTICULAR PURPOSE.
##############################################################################
cygwin=false;
case "`uname`" in
CYGWIN*) cygwin=true ;;
esac
# Based on findScalaHome() from scalac script
findKotlinHome() {
local source="${BASH_SOURCE[0]}"
while [ -h "$source" ] ; do
local linked="$(readlink "$source")"
local dir="$(cd -P $(dirname "$source") && cd -P $(dirname "$linked") && pwd)"
source="$dir/$(basename "$linked")"
done
(cd -P "$(dirname "$source")/.." && pwd)
}
KOTLIN_HOME="$(findKotlinHome)"
if $cygwin; then
# Remove spaces from KOTLIN_HOME on windows
KOTLIN_HOME=`cygpath --windows --short-name "$KOTLIN_HOME"`
fi
[ -n "$JAVA_OPTS" ] || JAVA_OPTS="-Xmx256M -Xms32M"
declare -a java_args
declare -a kotlin_args
while [ $# -gt 0 ]; do
case "$1" in
-D*)
java_args=("${java_args[@]}" "$1")
shift
;;
-J*)
java_args=("${java_args[@]}" "${1:2}")
shift
;;
*)
kotlin_args=("${kotlin_args[@]}" "$1")
shift
;;
esac
done
if [ -z "$JAVACMD" -a -n "$JAVA_HOME" -a -x "$JAVA_HOME/bin/java" ]; then
JAVACMD="$JAVA_HOME/bin/java"
fi
declare -a kotlin_app
if [ -n "$KOTLIN_RUNNER" ];
then
java_args=("${java_args[@]}" "-Dkotlin.home=${KOTLIN_HOME}")
kotlin_app=("${KOTLIN_HOME}/lib/kotlin-runner.jar" "org.jetbrains.kotlin.runner.Main")
else
[ -n "$KOTLIN_COMPILER" ] || KOTLIN_COMPILER=org.jetbrains.kotlin.cli.jvm.K2JVMCompiler
java_args=("${java_args[@]}" "-noverify")
kotlin_app=("${KOTLIN_HOME}/lib/kotlin-preloader.jar" "org.jetbrains.kotlin.preloading.Preloader" "-cp" "${KOTLIN_HOME}/lib/kotlin-compiler.jar" $KOTLIN_COMPILER)
fi
"${JAVACMD:=java}" $JAVA_OPTS "${java_args[@]}" -cp "${kotlin_app[@]}" "${kotlin_args[@]}"
从代码中找到了疑似编译部分的入口代码
declare -a kotlin_app
if [ -n "$KOTLIN_RUNNER" ];
then
java_args=("${java_args[@]}" "-Dkotlin.home=${KOTLIN_HOME}")
kotlin_app=("${KOTLIN_HOME}/lib/kotlin-runner.jar" "org.jetbrains.kotlin.runner.Main")
else
[ -n "$KOTLIN_COMPILER" ] || KOTLIN_COMPILER=org.jetbrains.kotlin.cli.jvm.K2JVMCompiler
java_args=("${java_args[@]}" "-noverify")
kotlin_app=("${KOTLIN_HOME}/lib/kotlin-preloader.jar" "org.jetbrains.kotlin.preloading.Preloader" "-cp" "${KOTLIN_HOME}/lib/kotlin-compiler.jar" $KOTLIN_COMPILER)
fi
"${JAVACMD:=java}" $JAVA_OPTS "${java_args[@]}" -cp "${kotlin_app[@]}" "${kotlin_args[@]}"
紧跟跳转,到CLICompiler.doMain()方法中。
我们可以看到,编译器执行完编译过程以后,会返回一个退出码,返回OK即为编译成功,否则直接退出编译过程。好,知道了这些,我们继续往下看。跟着代码的跳转,跳转,又跳转,看到了关键的编译入口代码,泪流满面。
词法、语法分析、语义分析、目标代码生成等过程
找到运行主类
写入文件
- 编译过程
Kotlin的整个编译过程大致有以下环节: - 词法分析2. 语法分析3. 语义分析及中间代码生成4. 目标代码生成
其中,我们把词法分析、语法分析、语义分析及中间代码生成称之为编译器前段,将源程序翻译成中间代码;目标代码生成称之为编译器后端,负责将中间代码转换生成目标代码,与目标语言有关的细节尽可能放在了后端。
2.1 词法分析
词法分析是将源程序读入的字符序列,按照一定的规则转换成词法单元(Token)序列的过程。词法单元是语言中具有独立意义的最小单元,包括关键字、标识符、常数、运算符、界符等等。
来看看Kotlin中划分的Token。
//org.jetbrains.kotlin.lexer.KtTokenspublic interface KtTokens { //关键字的token KtKeywordToken PACKAGE_KEYWORD = KtKeywordToken.keyword("package"); KtKeywordToken AS_KEYWORD = KtKeywordToken.keyword("as"); KtKeywordToken TYPE_ALIAS_KEYWORD = KtKeywordToken.keyword("typealias"); KtKeywordToken CLASS_KEYWORD = KtKeywordToken.keyword("class"); KtKeywordToken THIS_KEYWORD = KtKeywordToken.keyword("this"); KtKeywordToken SUPER_KEYWORD = KtKeywordToken.keyword("super"); KtKeywordToken VAL_KEYWORD = KtKeywordToken.keyword("val"); KtKeywordToken VAR_KEYWORD = KtKeywordToken.keyword("var"); KtKeywordToken FUN_KEYWORD = KtKeywordToken.keyword("fun"); KtKeywordToken FOR_KEYWORD = KtKeywordToken.keyword("for"); KtKeywordToken NULL_KEYWORD = KtKeywordToken.keyword("null"); ... //标识符、运算符token KtSingleValueToken LBRACKET = new KtSingleValueToken("LBRACKET", "["); KtSingleValueToken RBRACKET = new KtSingleValueToken("RBRACKET", "]"); KtSingleValueToken LBRACE = new KtSingleValueToken("LBRACE", "{"); KtSingleValueToken RBRACE = new KtSingleValueToken("RBRACE", "}"); KtSingleValueToken LPAR = new KtSingleValueToken("LPAR", "("); KtSingleValueToken RPAR = new KtSingleValueToken("RPAR", ")"); KtSingleValueToken DOT = new KtSingleValueToken("DOT", "."); ... //修饰符token KtModifierKeywordToken ABSTRACT_KEYWORD = KtModifierKeywordToken.softKeywordModifier("abstract"); KtModifierKeywordToken ENUM_KEYWORD = KtModifierKeywordToken.softKeywordModifier("enum"); KtModifierKeywordToken OPEN_KEYWORD = KtModifierKeywordToken.softKeywordModifier("open"); KtModifierKeywordToken INNER_KEYWORD = KtModifierKeywordToken.softKeywordModifier("inner"); KtModifierKeywordToken OVERRIDE_KEYWORD = KtModifierKeywordToken.softKeywordModifier("override"); KtModifierKeywordToken PRIVATE_KEYWORD = KtModifierKeywordToken.softKeywordModifier("private"); KtModifierKeywordToken PUBLIC_KEYWORD = KtModifierKeywordToken.softKeywordModifier("public"); ...}
Kotlin中将所有Token按照进行了分类,同时进行了Token分组。
//关键字 KtModifierKeywordToken[] MODIFIER_KEYWORDS_ARRAY = new KtModifierKeywordToken[] { ABSTRACT_KEYWORD, ENUM_KEYWORD, OPEN_KEYWORD, INNER_KEYWORD, OVERRIDE_KEYWORD, PRIVATE_KEYWORD, PUBLIC_KEYWORD, INTERNAL_KEYWORD, PROTECTED_KEYWORD, OUT_KEYWORD, IN_KEYWORD, FINAL_KEYWORD, VARARG_KEYWORD, REIFIED_KEYWORD, COMPANION_KEYWORD, SEALED_KEYWORD, LATEINIT_KEYWORD, DATA_KEYWORD, INLINE_KEYWORD, NOINLINE_KEYWORD, TAILREC_KEYWORD, EXTERNAL_KEYWORD, ANNOTATION_KEYWORD, CROSSINLINE_KEYWORD, CONST_KEYWORD, OPERATOR_KEYWORD, INFIX_KEYWORD, SUSPEND_KEYWORD, HEADER_KEYWORD, IMPL_KEYWORD }; //访问权限修饰符 TokenSet VISIBILITY_MODIFIERS = TokenSet.create(PRIVATE_KEYWORD, PUBLIC_KEYWORD, INTERNAL_KEYWORD, PROTECTED_KEYWORD); //操作符 TokenSet OPERATIONS = TokenSet.create(AS_KEYWORD, AS_SAFE, IS_KEYWORD, IN_KEYWORD, DOT, PLUSPLUS, MINUSMINUS, EXCLEXCL, MUL, PLUS, MINUS, EXCL, DIV, PERC, LT, GT, LTEQ, GTEQ, EQEQEQ, EXCLEQEQEQ, EQEQ, EXCLEQ, ANDAND, OROR, SAFE_ACCESS, ELVIS, RANGE, EQ, MULTEQ, DIVEQ, PERCEQ, PLUSEQ, MINUSEQ, NOT_IN, NOT_IS, IDENTIFIER);...
将所有的Kotlin词法单元一一枚举出来并分组以后,就要进行词法分析了。Kotlin使用了第三方开源的JFlex作为词法分析器,并没有自己实现(当然,重复造轮子就是一件很愚蠢的事情了:))。
2.1.1 定义JFlex词法分析配置文件Kotlin.flex
配置文件分为三个部分:
- 用户代码:
- 选项与声明:用来定制词法分析器,包括类名、父类、权限修饰符等等,以%开头作为标记
- 词法规则:包括一组正则表达式和动作行为,也就是当正则表达式匹配成功后要执行的代码。
具体可看Kotlin.flex详细配置文件。
2.1.2 词法分析器_JetLexer
JFlex会读取配置文件并生成一个词法分析器(扫描器),在Kotlin编译器中对应_JetLexer(http://www.jflex.de/)
上述的方法以“yy”为前缀,表示它们是由JFlex自动生成的,避免与复制到这个类中的用户代码名字有冲突。
关于如法匹配输入流:
当对输入流进行词法分析时,词法分析器依据最长匹配规则来选择输入流的正规式,即所选择的正规式能最长的匹配当前输入流。如果同时有多个满足最长匹配的正规式,则生成的词法分析器将从中选择最先出现在词法规则描述中的正规式。在确定了起作用的正规式之后,将执行贵正规式所关联的动作。如果没有匹配的正规式,词法分析器将终止对输入流的分析并给出错误消息。
最后,KotlinLexer调用_JetLexer进行词法分析。
2.2 语法分析
语法分析的任务是在词法分析的基础上将单词序列组合成各类语法短语,如“程序”,“语句”,“表达式”等等,语法分析器将判断源程序在结构上是否正确。在语法分析过程中,会生成语法树(ST)/抽象语法树(AST)。
Kotlin中定义了AST的数据结构
//AST抽象语法树节点
public interface ASTNode extends UserDataHolder {
//节点类型
IElementType getElementType();
//节点文本
String getText();
//父节点
ASTNode getTreeParent();
//第一孩子节点
ASTNode getFirstChildNode();
//最后孩子节点
ASTNode getLastChildNode();
//所有孩子
ASTNode[] getChildren(@Nullable TokenSet filter);
//移除孩子
void removeChild(@NotNull ASTNode child); ...}
Kotlin的语法分析使用了InteliJ平台的开发者项目,语法分析器继承使用了PsiParser。
然后通过提供的PsiParser实现KotlinParser。
PSI,即程序结构接口,定义了程序的结构。
PSI文件(PSI File)则能够将源代码文件内容表示为特定编程语言元素的层次结构。说的通俗一点,PSI文件可以把Java、XML等语言代码表示为层次结构(树)的形式。例如,在IntelliJ开源的项目来看,PsiJavaFile可表示为Java文件,XmlFile表示为XML文件。通过PSI文件,我们能够遍历迭代文件中的元素,从而生成AST,正也正是语法分析中所需要的。
KotlinParser语法分析器调用KotParsing进行语法分析,并生成AST抽象语法树。
关于如何生成一个简单表达式的AST树,可以参考下图:

2.3 语义分析及中间代码生成
语义分析的任务是检查抽象语法树AST的上下文相关属性,即检查源代码是否符合该编程语言的规范,比如变量类型定义是否正确,运算符是否匹配等等。
在Kotlin编译器中,语义分析的工作位于org.jetbrains.kotlin.resolve模块下。

该模块包含了所有的的上下文相关属性的检查,包括对表达式语句、常量、智能转换等上下文相关属性检查。
语义分析器进行了上下文相关属性的检查之后,会生成中间代码,位于org.jetbrains.kotlin.ir模块中。
2.4 目标代码生成
目标代码生成的任务,顾名思义,是将中间代码转换为目标代码,即JVM字节码,位于org.jetbrains.kotlin.codegen模块中。
目标代码生成入口:KotlinCodegenFacade.
在代码类生成的过程中,又包括生成类名、类体、字段、函数方法等环节,相关的生成类有 ClassBodyCodegen、ClassFunctionCodegen、MemberCodegen、ExpressionCodegen、PropertyCodegen等。
Kotlin与Java不同的编译过程主要在于目标代码生成环节,Kotlin做了更多的工作。举个例子:
在Kotlin中,如果我们定义如下代码:
var a: Int = 1;
会等价于Java中
public Int a = 1;
public Int getA(){ return a;}
public void setA(int a) { this.a = a;}
那么,在Kotlin中是怎么实现的呢,关于属性的生成部分,在PropertyCodegen中。
public class PropertyCodegen {
private void gen(
@Nullable KtProperty declaration, // 属性声明
@NotNull PropertyDescriptor descriptor, //描述,包括权限修饰符、注解、类型等。
@Nullable KtPropertyAccessor getter, // 决定是否生成getter
@Nullable KtPropertyAccessor setter //决定是否生成setter ) {
assert kind == OwnerKind.PACKAGE || kind == OwnerKind.IMPLEMENTATION || kind == OwnerKind.DEFAULT_IMPLS
: "Generating property with a wrong kind (" + kind + "): " + descriptor; //生成注解信息
genBackingFieldAndAnnotations(declaration, descriptor, false);
//根据注解和权限修饰符等信息判断是否自动生成Getter代码
if (isAccessorNeeded(declaration, descriptor, getter)) {
generateGetter(declaration, descriptor, getter);
}
//根据注解和权限修饰符等信息判断是否自动生成Setter代码
if (isAccessorNeeded(declaration, descriptor, setter)) {
generateSetter(declaration, descriptor, setter);
}
}
}
可以看到,Kotlin在目标代码生成环节做了更多的处理,在该环节实现了自动生成Getter、Setter的代码。
总结
Kotlin的编译过程分析完了,当然很多细节的东西并没有深入研究,并且内容太大,不是一篇文章可以说的详尽的。
那么,分析了这么多,我们得到了什么有用的信息?
Kotlin编译器在编译前端(即词法分析、语法分析、语义分析、中间代码生成)并没有做让人感到惊讶的事情,和Java是基本一致的。与Java相比,所与众不同,也最重要的细节在编译后端(目标代码生成)环节。Kotlin编译器在目标代码生成环节做了很多类似于Java封装的事情,比如自动生成Getter/Setter代码的生成、Companion转变成静态类、修改类属性为final不可继承等等工作。可以说,大部分Kotlin的特性都在这个环节处理产生。可以这么说,Kotlin将我们本来在代码层做的一些封装工作转移到了编译后端阶段,以使得我们可以更加简洁的使用Kotlin语言。
国内第一Kotlin 开发者社区公众号,主要分享、交流 Kotlin 编程语言、Spring Boot、Android、React.js/Node.js、函数式编程、编程思想等相关主题。
快快拿出手机,扫一扫关注吧~

参考资料:
http://mp.weixin.qq.com/s/lEFRH523W7aNWUO1QE6ULQ