Alexnet(2012)
Abstract
Alexnet是一个大规模的深度卷积神经网络,用于对ImageNet中的LSVRC-2010 contest(120万256*256的高分辨率图片)进行1000分类。其中用到的技术包括非饱和神经元,用于卷积运算的高效GPU,dropout正则化技术。同时,本文也给出了这一模型的一个变体。
Introduction
在此之前,提高性能的方法一般是扩大数据集,同时使用一些技巧防止过拟合。而直到近期(指2012),一些复杂的数据集如ImageNet, LabelMe(fully-segmented images)。
为处理上百万的复杂图像,我们需要一个具有更大学习容量的网络,同时,也需要大量的先验知识以弥补数据的不足。因此,CNN被提出,相比于普通神经网络,CNN具有连接层少(参数少),易训练,符合对图片数据的一些基本假设,尽管它的理论最佳性能比普通神经网络要次一些。
GPU和诸如ImageNet的数据集的提出,也促进了CNN的发展。
本文提出了一个超大规模的CNN,一个高度优化的用于执行2D卷积的GPU和一些防过拟合的手段。
本文提出的神经网络主要受到内存空间和训练时间的限制,它花费约5-6天时间跑在2个GTX 580 3GB GPU上。更快的GPU和更大的数据集可以使得训练结果得到进一步提升。
DataSet
1.ImageNet:
15million labeled high-resolution images belonging to roughly 22,000 categories
2.ILSVRC(the ImageNet Large-Scale Visual Recognition Challenge):
a subset of ImageNet, roughly 1000 images in 1000 categories, roughly 1.2million training images and 50,000 validation images and 150,000 testing images
3.top-1 and top-5 error rate:
the fraction of test images for which the correct label is not among the first/five labels considered most probable by the model
Architecture

上图是AlexNet的框架,其中上下部分分别使用2块GPU进行训练,共有5层卷积层和3层全连接层。以下是一些与先前不同的处理技巧(由于本文较早,很多技巧已变得普遍甚至过时)
ReLU
使用ReLu函数代替先前的tanh或sigmoid,使得网络训练的更快(事实上,使用传统激活函数训练该网络用时将严重超过可接受时间)
Training on Multiple GPUs
两块GPU并行,并只在特定的层交会
Local Response Normalization
ReLU函数本身并不需要normalization来防止saturating,但实验结果表面normalization仍然有助于generalization。
泛化函数为$ b_{x,y}^{i}=\dfrac {a_{x,y}^{i}} {(k+\alpha \sum_{j=max(0,i-n/2)}^{min(N-1,i+n/2)} (\alpha_{x,y}^{i})^2)^\beta} $, 其中k,α,β,n为超参,N为核的数量。核的排序是任意的。这一正则化来源于真实神经元中的外侧抑制 lateral inhibition
Overlapping Pooling
实验发现使用这种池化方式能够减缓过拟合
Overall Architecture
第一层卷积采用了stride=4
this is the distance between the receptive field centers of neighboring neurons in a kernel map (这句话我没有看懂)
各层的结构可参加前面那张图,在此略过。
Reducing Overfitting
Data Augmentation
- image translations and horizontal reflections
extracting random 224$\times $224 patches(and their horizontal reflections) from 256*256 images(实际中使用了位于4个角和中间的patch及其水平反射后的镜像,并对这10张图softmax层产生的预言做平均)
2.altering the intensities of the RGB channels
使用PCA方法
Dropout
以概率0.5将hidden neuron的输出设为0,在测试阶段,我们使用所有神经元,并将他们的输出乘0.5。AlexNet在前两层全连接层使用dropout
Learning Details
- optimizer
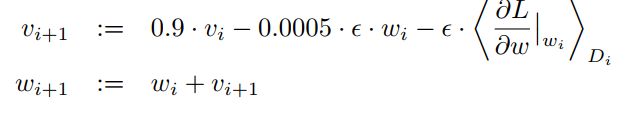
使用方差为0.01的正态分布初始化权重,同时在第2,4,5,6,7,8层用常数1初始化bias使得ReLus获得一个正数输入以加快最初的训练过程
- 每一层使用相同的学习率,并在训练过程中手动调节(每当validation error停止减少时将lr除以10)
共训练了约90个cycle