Github链接
PSP表格
| PSP | Personal Software Process Stages | 预计耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 40 | 50 |
| Estimate | 估计这个任务需要多少时间 | 60 | 50 |
| Development | 开发 | 300 | 400 |
| Analysis | 需求分析 (包括学习新技术) | 300 | 390 |
| Design Spec | 生成设计文档 | 30 | 20 |
| Design Review | 设计复审 | 30 | 30 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 20 | 30 |
| Design | 具体设计 | 30 | 30 |
| Coding | 具体编码 | 420 | 500 |
| Code Review | 代码复审 | 40 | 30 |
| Test | 测试(自我测试,修改代码,提交修改) | 120 | 150 |
| Reporting | 报告 | 30 | 20 |
| Test Report | 测试报告 | 20 | 30 |
| Size Measurement | 计算工作量 | 30 | 30 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 40 | 50 |
| Total | 合计 | 1510 | 1810 |
计算模块与接口的设计与实现
分析题意后,容易想到先把姓名、手机和难度提取出来,剩下的就是对地址的操作。根据不同的难度将地址分为五级或或级。由于前面的四级地址相对比较固定,可以考虑从百度一个存有四级地址的表。这样处理前四级的地址就可以从这个表中进行查找。如果leval == 1就把剩下的归为第五级地址,否则就判断地址中是否含有该级地址的关键字直到第七级。
考虑到代码实现的困难程度,决定使用Python实现。
主要用到的函数有:
getNums(cur_addr): 获取手机号码
delNums(cur_addr): 删除手机号码
getLvx(cur_addr, cur_path): 获取第x级的地址
首先读入四级地址的.json文件。通过json.load()转换成字典。
获取x(x<=4)级地址时通过在当前地址中查找是否含有第x级地址的某个地址来判断该级地址是否缺失。直辖市,自治区需要特殊判断。
处理手机号和5-7级地址时主要用正则表达式匹配

计算模块接口部分的性能改进
测试8组数据用时40ms,绝大部分时间都花在json.load()上,处理数据量比较小的时候效率较低,可以考虑对输入输出进行优化(速成的Python,现在还不会)。数据规模巨大的时候对地址hash处理?好像能行,但是好像挺麻烦


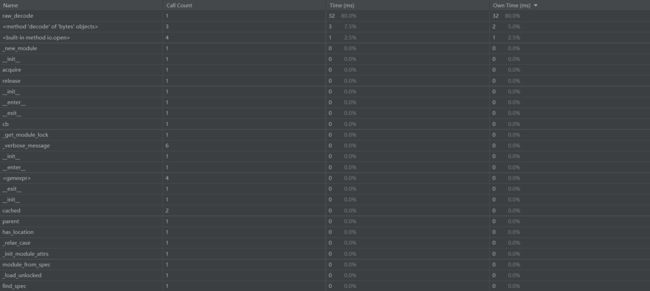
计算模块部分单元测试展示
输入:
2!李四,福建省福州13756899511市鼓楼区鼓西街道湖滨路110号湖滨大厦一层.
1!张三,福建福州闽13599622362侯县上街镇福州大学10#111.
2!王五,福建省福州市鼓楼18960221533区五一北路123号福州鼓楼医院.
3!小美,北京市东15822153326城区交道口东大街1号北京市东城区人民法院.
1!小陈,广东省东莞市凤岗13965231525镇凤平路13号.
2!高旦,14755894363甘肃兰州榆中县甘草店镇三墩营村卫生所.
1!司寇俱,湖北14736332425省随州市随县高城镇东华街6号高城镇人民政府.
1!幸懒雪,天津市河东区向阳楼街道阳安里4号楼15688316875.
1!弓诚,四川15370708858省涪城区城南街道跃进村村务监督委员会.
输出:
{"姓名": "李四", "手机": "13756899511", "地址": ["福建省", "福州市", "鼓楼区", "鼓西街道", "湖滨路", "110号", "湖滨大厦一层"]}
{"姓名": "张三", "手机": "13599622362", "地址": ["福建省", "福州市", "闽侯县", "上街镇", "福州大学10#111"]}
{"姓名": "王五", "手机": "18960221533", "地址": ["福建省", "福州市", "鼓楼区", "", "五一北路", "123号", "福州鼓楼医院"]}
{"姓名": "小美", "手机": "15822153326", "地址": ["北京", "北京市", "东城区", "交道口", "东大街", "1号", "北京市东城区人民法院"]}
{"姓名": "小陈", "手机": "13965231525", "地址": ["广东省", "东莞市", "", "市凤岗镇", "凤平路13号"]}
{"姓名": "高旦", "手机": "14755894363", "地址": ["甘肃省", "兰州市", "榆中县", "甘草店镇", "", "", "三墩营村卫生所"]}
{"姓名": "司寇俱", "手机": "14736332425", "地址": ["湖北省", "随州市", "随县", "高城镇", "东华街6号高城镇人民政府"]}
{"姓名": "幸懒雪", "手机": "15688316875", "地址": ["天津", "天津市", "河东区", "向阳楼街道", "阳安里4号楼"]}
{"姓名": "弓诚", "手机": "15370708858", "地址": ["四川省", "", "", "涪城区城南街道", "跃进村村务监督委员会"]}
前四级地址的确定是从字典中匹配完成的,而为了查找效率字典中四级地址是按照每一级来存储的,就比如查找福建省福州市...首先在第一级字典中查找福建,找到后在进入以福建为第一级地址的二级字典,以此类推找到前四级地址。这样比单纯从第x级暴力查找的效率高一些。对于前三级地址未缺失的地址都能比较正确地处理。但是对于前三级地址存在某一级地址缺失的情况下,由于不能在字典中找到相应的地址,就无法进入下一级的字典,造成后面的地址都为空。对于这个问题我并没有很好的解决QAQ。就比如最后一条弓诚的地址信息,由于缺少第二级地址导致第三级地址也为空(实际应该是培城区)导致错误。
计算模块部分异常处理
每次处理的时候加入try, except有异常就忽略或者直接返回。。。