刘小泽写于19.9.22
之前学习过单细胞数据细胞周期推断,就是用cyclone函数(https://www.jianshu.com/p/46d597d21a16)
这次增加一些内容,来自:Cancer Research UK Cambridge Institute的作者Aaron
这里根据Scialdone et al. (2015) 提供的预测方法,简而言之就是利用一个做好的训练数据集和已知表达矩阵基因表达量变化进行分类。在训练数据集中,已经计算好了两两基因的差异(基因对,pair of genes),并且将属于不同细胞周期(它规定了3种量化水平:G1、S、G2M)且存在差异的基因对作为一个marker pair。然后就在已知表达矩阵中对每个细胞测试这些marker pairs与训练数据集中的相似程度,每个细胞最后都得到了在G1、S、G2/M水平的分值,最后根据分值将细胞归类。
主要利用了scran包中的cyclone函数
cyclone函数主要需要三个元素:一个是sce单细胞对象,一个是pairs参数,还有就是gene.names参数。第一个已准备好,第二个参数的意思可以看帮助文档,第三个参数要求是Ensembl ID

# scran包安装好后,会在exdata文件夹中找到附件文件
library(org.Mm.eg.db)
# syste,.file会列出文件所在的路径,下图就是exdata文件夹下的文件,看到除了小鼠还有人的相关的RDS数据。这个RDS其实和平常看到的Rdata差不多,只不过Rdata是针对多个对象,Rds是针对一个对象进行存储和读取
mm.pairs <- readRDS(system.file("exdata", "mouse_cycle_markers.rds",
package="scran"))
# 举个例子
> head(mm.pairs$G1)
first second
1 ENSMUSG00000000001 ENSMUSG00000001785
2 ENSMUSG00000000001 ENSMUSG00000005470
3 ENSMUSG00000000001 ENSMUSG00000012443
4 ENSMUSG00000000001 ENSMUSG00000015120
5 ENSMUSG00000000001 ENSMUSG00000022033
6 ENSMUSG00000000001 ENSMUSG00000023015
注意:这里小鼠的训练数据集是利用胚胎干细胞数据得到的,但对于其他细胞类型也是准确的 (Scialdone et al. 2015),可能是由于细胞周期相关转录的保守性 (Bertoli, Skotheim, and Bruin 2013; Conboy et al. 2007)。
具体的使用就很简单:
system.time(assignments <- cyclone(sce, mm.pairs,
gene.names=rowData(sce)$ENSEMBL))
## user system elapsed
## 21.740 0.376 26.856
save(sce,assignments,file = '416B_cell_cycle.Rdata')
这个结果并不是说某个细胞一定就处于哪个细胞周期,它也是根据大样本量背景进行概率估计,然后计算一个分值,分值越高,说明某个细胞更有可能属于哪个细胞周期,给我们一定的参考。
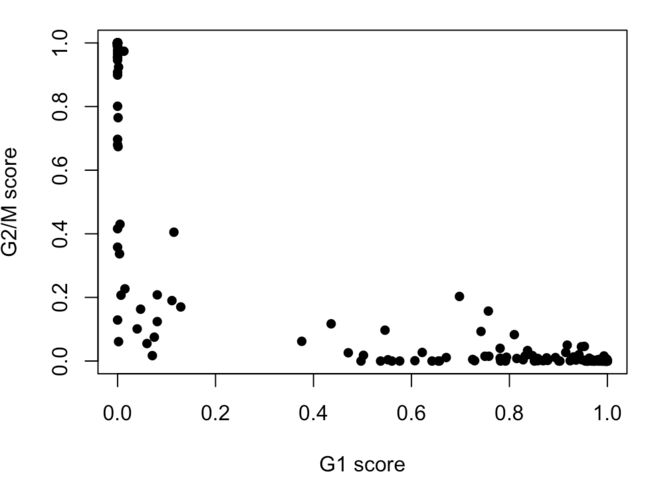
例如,看一下G1和G2/M的分值情况,其中每个点代表一个细胞:
plot(assignments$score$G1, assignments$score$G2M,
xlab="G1 score", ylab="G2/M score", pch=16)
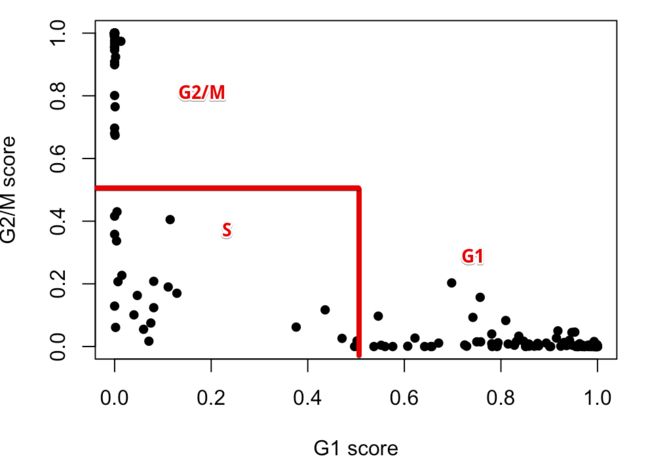
计算完细胞分值,就该划分细胞类型了
具体规则是:如果一个细胞在G1中得分大于0.5,并且它高于G2/M的得分,那么这个细胞就被划分到G1期;如果细胞在G2/M中得分大于0.5,并且高于G1的得分,那么它就划为G2/M期;如果细胞的G1、G2/M得分都不大于0.5,那么它就划为S期。于是上面的结果就可以被划分成:
这里只是说明一下原理, 其实函数已经为我们划分好,存到了结果中:
sce$phases <- assignments$phases
table(sce$phases)
##
## G1 G2M S
## 98 62 23
作者的建议
- 为了去掉细胞周期带来的影响,我们一般只要某一群特定周期的细胞(一般是G1期)进行下游分析。当然如果其他时期的细胞数量不会造成明显的影响,我们也可以带着它们,到下游分析时直接将
assignments$phases作为一个批次效应因素考虑即可,这样既避免了其他周期细胞的干扰,又能避免丢失部分信息。 - 训练数据集虽然说对多种细胞类型都支持,如果本身的数据与训练数据相差太大(比如使用了不同的方法得到的数据),那么我们可以根据自己的数据去DIY一个分类器。使用
sandbag函数即可,同样如果研究其他的物种没有给定的分类器,我们就可以这样操作 - 在使用
cyclone之前不要过滤低丰度转录本。即使一个基因在任何一个细胞都不表达,但在周期推断环节这个基因名还是有作用的。因为这一步做的是一个基因对比较,所以它依然可以提供信息。
欢迎关注我们的公众号~_~
我们是两个农转生信的小硕,打造生信星球,想让它成为一个不拽术语、通俗易懂的生信知识平台。需要帮助或提出意见请后台留言或发送邮件到[email protected]
