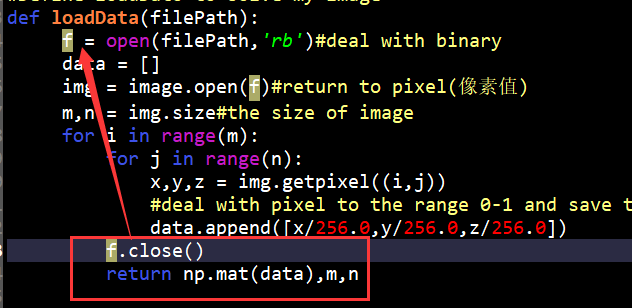
”“”K-Means to realize Image segmentation “”“ import numpy as np import PIL.Image as image from sklearn.cluster import KMeans #Define loadDato to solve my image def loadData(filePath): f = open(filePath,'rb')#deal with binary data = [] img = image.open(f)#return to pixel(像素值) m,n = img.size#the size of image for i in range(m): for j in range(n): x,y,z = img.getpixel((i,j)) #deal with pixel to the range 0-1 and save to data data.append([x/256.0,y/256.0,z/256.0]) f.close() return np.mat(data),m,n imgData,row,col = loadData("./picture/apple.png") #setting clusers(聚类中心) is 3 label = KMeans(n_clusters=3).fit_predict(imgData) #get the label of each pixel label = label.reshape([row,col]) #create a new image to save the result of K-Means pic_new = image.new("L",(row,col)) #according to the label to add the pixel for i in range(row): for j in range(col): pic_new.putpixel((i,j),int(256/(label[i][j]+1))) pic_new.save("./picture/km.jpg","JPEG")
K-Means算法:
我们常说的K-Means算法属于无监督分类(训练样本的标记信息是未知的,目标是通过对无标记训练样本的学习来揭示数据的内在性质和规律,为进一步的数据分析提供基础),它通过按照一定的方式度量样本之间的相似度,通过迭代更新聚类中心,当聚类中心不再移动或移动差值小于阈值时,则就样本分为不同的类别。聚类试图将数据集中的样本划分为若干个通常是不相交的子集,每个子集称为一个”簇“,通过这样的划分,每个簇可能对应于一些潜在的类别。
算法实现步骤:
- 随机选取聚类中心
- 根据当前聚类中心,利用选定的度量方式,分类所有样本点
- 计算当前每一类的样本点的均值,作为下一次迭代的聚类中心
- 计算下一次迭代的聚类中心与当前聚类中心的差距,若差距小于迭代阈值时,迭代结束。
算法伪代码:

其中,D为样本集,聚类所得簇划分为C
图像分割实验:利用图像的灰度、颜色、纹理、形状等特征,把图像分成若 干个互不重叠的区域,并使这些特征在同一区域内呈现相似性,在不同的区 域之间存在明显的差异性。然后就可以将分割的图像中具有独特性质的区域 提取出来用于不同的研究。本次实验我们将apple聚类中心设置n_clusters=3,cat聚类中心设置为2
1、实验步骤
- 建立kms.py工程并导入所需python包
- 加载本地图片进行预处理
- K-Means聚类算法实现
- 聚类像素点并保存输出
2、实验数据
测试image:


3、实验结果


3、实验总结
在本次实验中,我们通过设置不同的聚类中心,从而得到不同的聚类结果。如果想要得到预想的效果,必须多次尝试,这使得K值具有不确定性,不利于我们操作。
在进行本次实验时,遇到如下问题:
(1)IndentationError: unindent does not match any outer indentation level
(2)ValueError: cannot reshape array of size 500 into shape (500,500)
问题解决:
这两个问题出现的原因均是对其python格式对齐出现问题,f的打开和f的关闭应该对齐,而报错的原因也恰在这里。一般(2)的报错原因最多可能是数据格式有问题,但在考虑数据格式有问题的时候,首先查看代码格式是否正确。