正则表达式(Regular Expression, 简称RegEx)是一些用来匹配和处理文本的字符串,它是用正则表达式语言创建的,这种语言的用途主要是为了检索和替换某些文本。
本文只是《正则表达式必知必会》和传说中的三十分钟学会正则表达式的一个小总结,因此,不打算从头开始介绍正则表达式,只记录一些知识点。
1. 一些元字符
元字符 意义
. 除了换行符之外的所有字符。当要表达.本身意思的时候,要使用转义符。
\d 任何一个数字字符(等价于[0-9])
\D 任何一个非数字字符(等价于[^0-9])
\w 任何一个字母数字字符或下划线字符(等价于[a-zA-Z0-9_]),可以理解为与变量命名规则类似
\W 任何一个非字母数字字符或非下划线字符(等价于[^a-zA-Z0-9_])
\s 任何一个空白字符(等价于[\f\n\r\t\v])
\S 任何一个非空白字符(等价于[^\f\n\r\t\v])
\b 任何一个单词开头或结尾的地方
\B 任何一个非单词开头或结尾的地方
^ 放在正则表达式的最前面,表示以此开头
$ 放在正则表达式的最后面,表示以些结尾
2. 匹配一组字符
使用[],可以匹配多个字符中的一个,如[NC]BA可以匹配NBA,也可以匹配CBA;
也可以利用字符集合区间匹配一个范围,通过-连接,如[0-9a-zA-Z] 或 class[A-D],都是可以的。字符区间的首、尾字符可以是ASCII字符表里的所有字符,但在实际工作中,最常用的字符区间还是数字字符区间和字母字符区间。
当然,字符区间也可以取非,通过^字符放在前面即可,如[^0-5],匹配6,7,8,9. 要注意的是^的效果将作用于给定字符集合里的所有字符或字符区间,而不是仅限于紧跟^字符后面的那一个字符或字符区间。因此^,如果放在区间的最前面,表示的就是取非,如果想要取其原来的意思,则必须使用转义符。如果不是在区间最前面,则可以不使用转义符。
【举个栗子1】
如下示例-1,本意是想要匹配任何为a或^的字符(不要问为什么,就是有这样奇怪的要求)
1 String s = "a^"; 2 Pattern pattern = Pattern.compile("[^a]*"); 3 System.out.println(pattern.matcher(s).matches());
很明显这个表达式的意思是所有非a的字符,那么肯定是返回false了。
正确的写法应该是转义,或将^放在a后面。
1 String s = "a^"; 2 // String regex = "[a^]*"; 3 String regex = "[\\^a]*"; 4 Pattern pattern = Pattern.compile(regex); 5 System.out.println(pattern.matcher(s).matches());
表示范围的-,当前后没有字符的时候,不需要转义。
3. 重复多次
字符 意义
? 表示0或只有1个,可以参考三目运算符
+ 表示至少有1或更多
* 表示0或者有1或更多都可以
{n} 精确匹配n次
{n,} 至少匹配n次
{n,m} 至少匹配n次,至多匹配m次
However,这些都不是我要讲的重点。重点是,防止过度匹配。
来看下面的例子
【举个栗子2】
假如有一个html格式文件,你想要找出里面的
标签,你可能会酱紫写:
.*
。然而,结果却是错的。1 String s = "fuck
you
"; 2 String regex = ".*
"; 3 Pattern pattern = Pattern.compile(regex); 4 Matcher matcher = pattern.matcher(s); 5 6 while(matcher.find()) { 7 System.out.println(matcher.group()); 8 }
![]()
也就是说,一次就把它匹配出来了,但你的想法是想要把这两个标签分别匹配出来,即匹配两次。这,就是过度匹配。
为什么会酱紫?因为*和+都是所谓的“贪婪型”元字符,它们在进行匹配时的行为模式是尽可能地从一段文本的开头匹配到结尾,而不是从这段文本的开头匹配到碰到第一个匹配时为止。
那么就要使用元字符的懒惰版本。
字符 意义
*? 匹配零个或1个或更多,但尽可能地少匹配
+? 匹配1个或更多,但尽可能地少匹配
?? 匹配零个或1个,但尽可能地少匹配
{n,}? 匹配n个或更多,但尽可能地少匹配
{n,m}? 匹配至少n个,至多m个,但尽可能地少匹配
那么,上面的例子就只要把
.*
改为.*?
就可以了。
4.子表达式或分组
把一个表达式划分为一系列子表达的目的是为了把那些子表达式当作一个独立元素来使用,可以认为把重复部分抽象出来。
分组的另一个主要作用是回溯引用(也叫向后引用)。回溯引用指的是模式的后半部分引用在前半部分定义的子表达式。
【举个栗子3】
假如有一个html文件,里面有从h1到h6的标签,你想要匹配正确的标签。注意是正确的标签,也就意味着,像
fuckyou这样是不合法的。
待匹配的文本如下:
this is head
saysomething.
fuck you
actually its not valid
按照之前的学习,很容易写出如下代码:
1 String s = "this is head
saysomething.fuck you
actually its not valid"; 2 String regex = "<[hH][1-6]>.*?"; 3 Pattern pattern = Pattern.compile(regex); 4 Matcher matcher = pattern.matcher(s); 5 6 while(matcher.find()) { 7 System.out.println(matcher.group()); 8 }
然而结果是把最后一个非法的标签也取出来了。为什么该标签是非法的?因为闭合标签必须跟它对应的标签名一致,即当你匹配了h1,后面只能继续匹配h1而不是其他,也即是说,后半部分的模式需要用到前半部分定义的子表达式。
将正则表达式改为 <([hH][1-6])>.*? 就好了,在Java中字符串记得对\进行转义。
回溯引用通常从1开始计数(\1,\2等),在许多实现里第0个匹配整个正则表达式。
那么问题就来了,对于嵌套分组,是怎么计数的?
总的来说,就是从一个大的分组往更小的分组不断地计数,个人感觉有点像前序遍历一棵树。
来看下面的例子。
【举个栗子4】
1 String s = "ABCDEFHG"; 2 String regex = "(A)((B)(C))(D)((E(F(H)))(G))"; 3 Pattern pattern = Pattern.compile(regex); 4 Matcher matcher = pattern.matcher(s); 5 6 while(matcher.find()) { 7 System.out.println(matcher.group()); 8 for(int i = 1; i <= matcher.groupCount(); i++) { 9 System.out.println("group " + i + ": " + matcher.group(i)); 10 } 11 }
这正则表达式问你怕了没?
运行结果如下,自行分析吧。
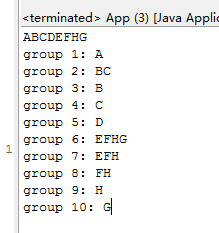
可以利用回溯引用来进行替换操作。
但是对于重复多次的分组,只能匹配到最近一次出现的分组,原因不明,请大神指教。下面的例子将结合这种情况进行替换操作。
【举个栗子5】
现在有个任务,需要将IP地址的第一部分替换掉。
你可以很容易地写出String regex = "((\\d|[1-9]\\d|1\\d{2}|2[0-4]\\d|25[0-5])\\.){3}(\\d|[1-9]\\d|1\\d{2}|2[0-4]\\d|25[0-5])"; 这样一个正则。然后根据刚才上面的分析,要进行替换,必然有以下的代码:
1 String s = "192.168.56.1"; 2 String regex = "((\\d|[1-9]\\d|1\\d{2}|2[0-4]\\d|25[0-5])\\.){3}(\\d|[1-9]\\d|1\\d{2}|2[0-4]\\d|25[0-5])"; 3 4 System.out.println(s.replaceAll(regex, "100.$3$5$7"));
然而结果是错的。
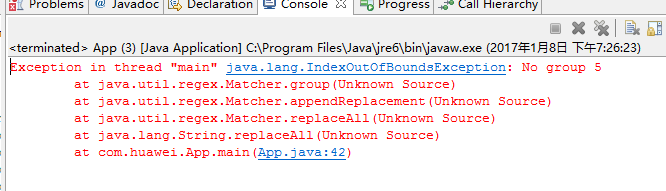
让我们来打印一下各个匹配到的分组都是什么。
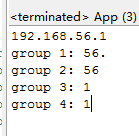
从结果来看,前面三组重复的分组,只获取到了最后一个分组。
上面的例子需要改成如下方可正常运行。
1 String s = "192.168.56.1"; 2 String regex = "((\\d|[1-9]\\d|1\\d{2}|2[0-4]\\d|25[0-5])\\.)((\\d|[1-9]\\d|1\\d{2}|2[0-4]\\d|25[0-5])\\.)((\\d|[1-9]\\d|1\\d{2}|2[0-4]\\d|25[0-5])\\.)(\\d|[1-9]\\d|1\\d{2}|2[0-4]\\d|25[0-5])"; 3 4 System.out.println(s.replaceAll(regex, "100.$3$5$7"));
在替换时有些语言是支持将字母改为大写或小写的。Java不支持。
元字符 意义
\l 把下一个字符转换成小写(lowercase)
\u 把下一个字符转换成大写(uppercase)
\L 把\L和\E之间所有的字符都转换成小写
\U 把\U和\E之间所有的字符都转换成大写
\E 用来结束\L或\U转换
使用\u
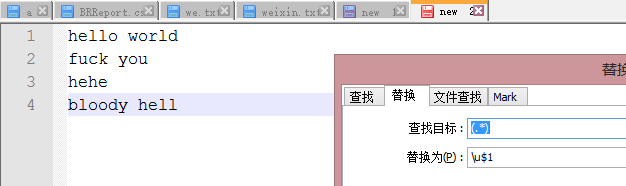
结果:
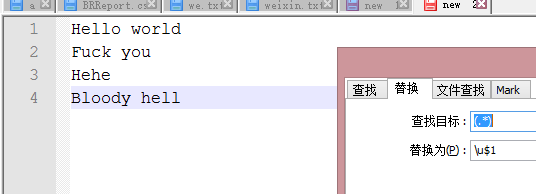
使用\U
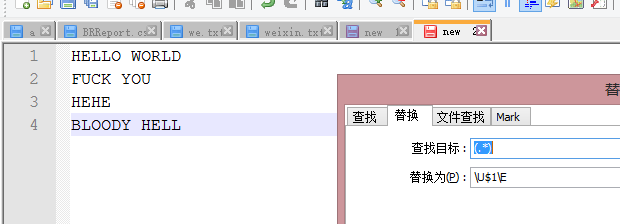
5.前后查找
最后一个知识点是关于前后查找的,该模式的作用是包含的匹配本身并不返回,而是用于确定正确的匹配位置,它并不是匹配结果的一部分。
想像一个场景,要把html文件里,某个标签之间的内容提取出来。或者在某个格式前面或后面把内容提取出来。
任何一个表达式都可以转换为一个向前查找表达式,只要给它加上一个?=前缀就可以了。同理向后查找,加上一个?<=前缀。
要注意的是,向前查找表达式,应放在模式的后面,而向向查找表达式,放在模式的前面。不能搞混了。
【举个栗子6】
假如有一批价格如下:
$5.00,$6.00,$7.00,
需要把价格提取出来计算,代码如下:
1 String s = "$5.00,$6.00,$7.00,"; 2 String regex = "(?<=\\$).*?(?=,)"; 3 4 Pattern pattern = Pattern.compile(regex); 5 Matcher matcher = pattern.matcher(s); 6 7 double total = 0; 8 while(matcher.find()) { 9 System.out.println(matcher.group()); 10 total += Double.parseDouble(matcher.group()); 11 } 12 13 System.out.println("total:" + total);
运行结果如下:
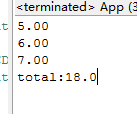
最后啰嗦一下,向前查找(和向后查找)匹配本身其实是有返回结果的,只是这个结果的字节长度永远是0而已。所以有时也被称为零宽度(zero-width)匹配操作,或者零宽断言。