场景:
某大型电商网站基于微服务架构,服务模块有几十个。
某天,测试人员报告该网站响应速度过慢。排除了网络问题之后,发现很难进一步去排除故障。
那么:如何对微服务的链路进行监控呢?
Sleuth:
一般的,一个分布式服务跟踪系统,主要有三部分:数据收集、数据存储和数据展示。
根据系统大小不同,每一部分的结构又有一定变化。
譬如,对于大规模分布式系统,数据存储可分为实时数据和全量数据两部分.
实时数据用于故障排查(troubleshooting):全量数据用于系统优化
数据收集除了支持平台无关和开发语言无关系统的数据收集,还包括异步数据收集(需要跟踪队列中的消息,保证调用的连贯性)
以及确保更小的侵入性;数据展示又涉及到数据挖掘和分析。
虽然每一部分都可能变得很复杂,但基本原理都类似。
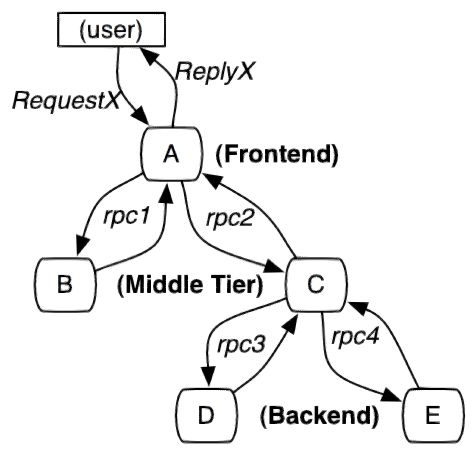
服务追踪的追踪单元是从客户发起请求(request)抵达被追踪系统的边界开始
到被追踪系统向客户返回响应(response)为止的过程,称为一个“trace”。
每个 trace 中会调用若干个服务,为了记录调用了哪些服务,以及每次调用的消耗时间等信息,在每次调用服务时,埋入一个调用记录,称为一个“span”。
这样,若干个有序的 span 就组成了一个 trace。
在系统向外界提供服务的过程中,会不断地有请求和响应发生,也就会不断生成 trace。
把这些带有span 的 trace 记录下来,就可以描绘出一幅系统的服务拓扑图。
附带上 span 中的响应时间,以及请求成功与否等信息,就可以在发生问题的时候,找到异常的服务。
根据历史数据,还可以从系统整体层面分析出哪里性能差,定位性能优化的目标。
Spring Cloud Sleuth为服务之间调用提供链路追踪。
通过Sleuth可以很清楚的了解到一个服务请求经过了哪些服务,每个服务处理花费了多长。
从而让我们可以很方便的理清各微服务间的调用关系。
此外Sleuth可以帮助我们:
- 耗时分析: 通过Sleuth可以很方便的了解到每个采样请求的耗时,从而分析出哪些服务调用比较耗时;
- 可视化错误: 对于程序未捕捉的异常,可以通过集成Zipkin服务界面上看到;
- 链路优化: 对于调用比较频繁的服务,可以针对这些服务实施一些优化措施。
spring cloud sleuth可以结合zipkin,将信息发送到zipkin,利用zipkin的存储来存储信息,利用zipkin ui来展示数据。
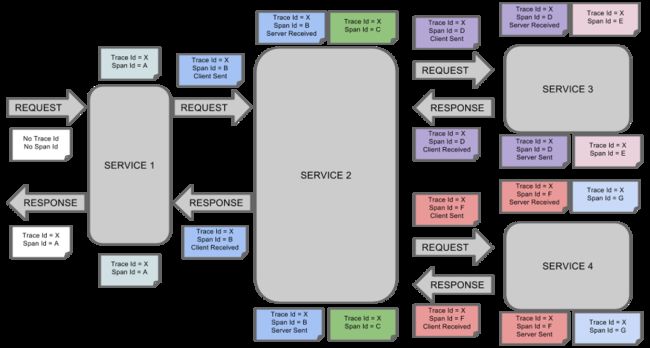
这是Spring Cloud Sleuth的概念图:
Sleuth的简单使用:
加入依赖
<dependency> <groupId>org.springframework.cloudgroupId> <artifactId>spring-cloud-starter-sleuthartifactId> dependency>
启动项目,发现会打印下面这些信息:
[order-service,86028f5d0762bee1,d08375022720d818,false]
第一个参数:项目的名称,服务模块的名称:spring.application.name
第二个参数:TraceID:用来标识请求的一整条链路,一条链路只有一个TraceID
第三个参数:SpanID:基本的工作元,获取元数据
第四个参数:是否要把该信息输出到Zipkin服务中来收集和展示
ZipKin
Zipkin 是一个开放源代码分布式的跟踪系统,由Twitter公司开源。
它致力于收集服务的定时数据,以解决微服务架构中的延迟问题,包括数据的收集、存储、查找和展现。
每个服务向zipkin报告计时数据,zipkin会根据调用关系通过Zipkin UI生成依赖关系图。
显示了多少跟踪请求通过每个服务,该系统让开发者可通过一个 Web 前端轻松的收集和分析数据
例如用户每次请求服务的处理时间等,可方便的监测系统中存在的瓶颈。
Zipkin提供了可插拔数据存储方式:In-Memory、MySql、Cassandra以及Elasticsearch。接下来的测试为方便直接采用In-Memory方式进行存储,生产推荐Elasticsearch。
快速上手
创建zipkin-server项目
项目依赖
org.springframework.cloud spring-cloud-starter-eureka io.zipkin.java zipkin-server io.zipkin.java zipkin-autoconfigure-ui
启动类
@SpringBootApplication
@EnableEurekaClient
@EnableZipkinServer
public class ZipkinApplication {
public static void main(String[] args) {
SpringApplication.run(ZipkinApplication.class, args);
}
}
使用了@EnableZipkinServer注解,启用Zipkin服务。
配置文件
eureka:
client:
serviceUrl:
defaultZone: http://localhost:8761/eureka/
server:
port: 9000
spring:
application:
name: zipkin-server
配置完成后依次启动示例项目:spring-cloud-eureka、zipkin-server项目。刚问地址:http://localhost:9000/zipkin/可以看到Zipkin后台页面
我采用了更方便快捷的方式:Docker
1、Docker 要求 CentOS 系统的内核版本高于 3.10 ,查看本页面的前提条件来验证你的CentOS 版本是否支持 Docker 。
通过 uname -r 命令查看你当前的内核版本
$ uname -r
2、使用 root 权限登录 Centos。确保 yum 包更新到最新。
$ sudo yum update
3、卸载旧版本(如果安装过旧版本的话)
$ sudo yum remove docker docker-common docker-selinux docker-engine
4、安装需要的软件包, yum-util 提供yum-config-manager功能,另外两个是devicemapper驱动依赖的
$ sudo yum install -y yum-utils device-mapper-persistent-data lvm2
5、设置yum源
$ sudo yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo

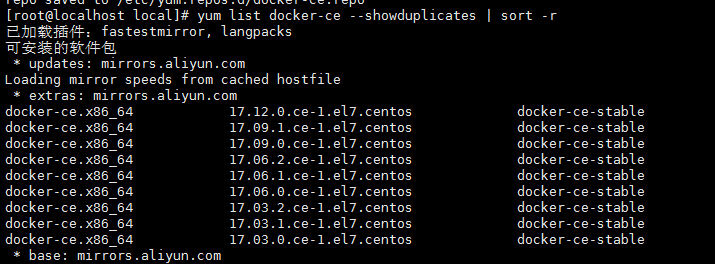
6、可以查看所有仓库中所有docker版本,并选择特定版本安装
$ yum list docker-ce --showduplicates | sort -r
7、安装docker
$ sudo yum install docker-ce #由于repo中默认只开启stable仓库,故这里安装的是最新稳定版17.12.0 $ sudo yum install# 例如:sudo yum install docker-ce-17.12.0.ce

8、启动并加入开机启动
$ sudo systemctl start docker $ sudo systemctl enable docker
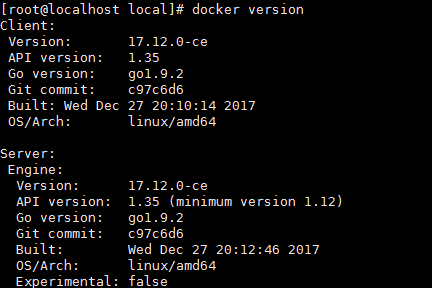
9、验证安装是否成功(有client和service两部分表示docker安装启动都成功了)
$ docker version
Zipkin安装
执行命令:
docker run -d -p 9411:9411 openzipkin/zipkin
然后访问http://[Docker机器的IP]:9411进入Zipkin可视Web界面
整合:
加入依赖
<dependency> <groupId>org.springframework.cloudgroupId> <artifactId>spring-cloud-starter-zipkinartifactId> dependency>
另外,Zipkin依赖包括了Sleuth依赖,可以删除上边引入的Sleuth依赖
配置Zipkin Server和该服务采样百分比(1为最大,生产环境不建议设置为1):
spring.zipkin.base-url=http://[0.0.0.0]:9411/
spring.sleuth.sampler.probability=1
访问Zipkin Server,刷新几次就会出现之前配置过的服务:
访问几次服务的接口,然后就可以针对某个服务进行链路分析
具体Zipkin界面的使用,不多做介绍了,中文界面操作不难
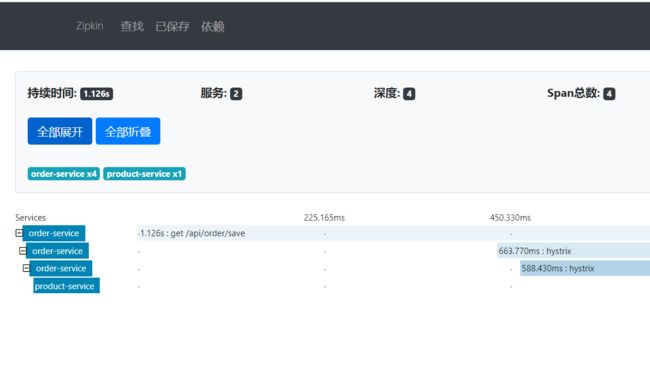
对请求链路进行追踪,就可以确定服务的哪一个模块更耗时,进而可以进行优化或者排BUG
因此,在开发环境中,部署Sleuth和Zipkin是比较重要的
以上部分内容参考博客:
http://www.cnblogs.com/jianliang-Wu/p/8945890.html
https://www.cnblogs.com/yufeng218/p/8370670.html