到目前为止,我们已经讨论了ZooKeeper服务的基础知识,并详细了解了数据模型及其属性。 我们也熟悉了ZooKeeper 监视(watch)的概念,监视就是在ZooKeeper命名空间中的znode发生任何变化时完成的事件机制。 我们通过公开一组与znodes相关联的ACL来读取身份验证和基本安全模型。
在本节中,我们将通过介绍ZooKeeper session的概念来讨论和了解客户端与ZooKeeper服务交互的生命周期。 我们还将详细阅读ZooKeeper如何在内部描述协议。 了解以及深入理解内部工作原理非常重要,这有助于使用ZooKeeper设计分布式应用程序,并了解与之相关的错综复杂的事情。
我们先来看看客户端如何与ZooKeeper服务进行交互。 为了使分布式应用程序能够使用ZooKeeper服务,他们必须通过客户端类库来使用API。 ZooKeeper客户端库对几乎所有流行的编程语言都有语言绑定。 客户端库类库负责应用程序与ZooKeeper服务的交互。
下图显示了应用程序与ZooKeeper服务的交互过程:
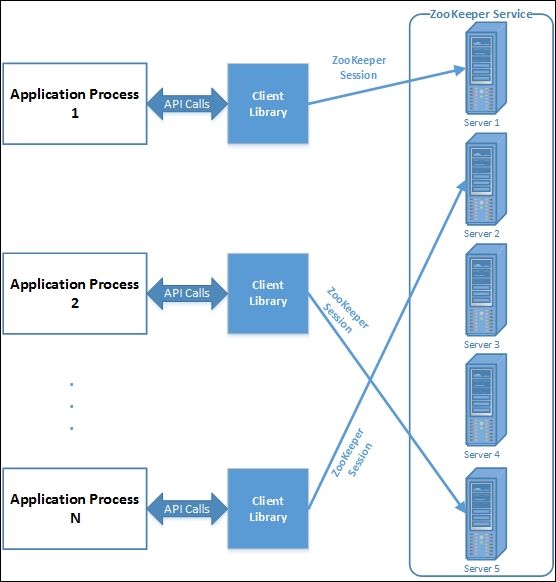
ZooKeeper服务可以以两种模式运行:独立(standalone)模式和仲裁(quorum)模式。 在独立模式下,有一个ZooKeeper服务器。 另一方面,quorum模式意味着ZooKeeper以复制模式运行在一组机器上,也称为ensemble。
Note
独立模式仅用于评估和测试应用程序代码,但不能在生产中使用,因为这是潜在的单点故障。 在仲裁模式下,ZooKeeper通过复制实现高可用性,只要ensemble中大部分机器启动,都可以提供服务。
一 quorum模式
ZooKeeper quorum构成了复制节点的大部分,这些复制节点将ZooKeeper服务的最新状态存储在ensemble中的所有服务器中。 这基本上是必须启动并运行的服务器节点的最小数量,并且可用于客户端请求。 客户端对ZooKeeper树进行的任何更新都必须永久存储在此quorum的节点中,以便事务成功完成。
例如,在一个五个节点ensemble中,任何两台机器都可能失败,并且我们可以拥有三台服务器的quorum,ZooKeeper服务仍然可以工作。 稍后,如果其他两个失败节点出现,则可以通过从现有quorum中获取最新状态来同步ZooKeeper服务状态。
Tips
调整ZooKeeper服务中服务器节点的数量对于ZooKeeper正确运行非常重要。 由于所有的事务提交都依赖于多数共识的概念,所以建议ZooKeeper集合中应该有奇数个机器。
让我们来看一个例子,看看为什么这是有道理的。 假设我们有一个由五台服务器组成的ZooKeeper ensemble。 如果任何两台服务器发生故障,ensemble仍然可以运行,因为可以在其余三个节点之外形成quorum。 因此,五节点ZooKeeper ensemble可以容忍多达两个节点的故障。
现在,对于六节点ensemble,ZooKeeper服务可以容忍最多只有两个节点的故障。 这是因为有三个节点失败,无法形成quorum。 在那里不能达到多数的共识。 同样,ZooKeeper quorum必须保证任何成功承认客户端的事务都应该是持久的,并在形成quorum的节点上可见。
如果ZooKeeper quorum不是由ensemble中的大多数节点组成的,ZooKeeper命名空间的状态可能会有不一致,从而导致错误的结果。 除了节点故障之外,集合中节点之间的网络分区可能会导致不一致的操作,因为quorum成员之间将无法传递更新。 这导致在分布式群集中出现的共同问题,称为脑裂(split-brain)。
脑裂是ensemble中的两个服务器子集独立运作的场景。 这会导致整个ZooKeeper服务中的状态不一致,并且不同的客户端根据相同的请求获得不同的结果,具体取决于它们所连接的服务器。 通过使用奇数个节点运行ZooKeeper集群,我们可以将此类错误的概率降至概率最小。
二 客户端与ZooKeeper服务建立session会话
连接到ZooKeeper的客户端可以配置一个构成ZooKeeper ensemble的服务器列表。 客户端尝试通过从列表中选择一个随机服务器来连接到列表中的服务器。 如果连接失败,则尝试连接到下一个服务器,依此类推。 此过程直到列表中的所有服务器都被尝试或建立了成功的连接。
一旦客户端和ZooKeeper服务器之间建立连接,就在客户端和服务器之间建立一个会话(session),表示为分配给客户端的64位数字。 会话的概念对于ZooKeeper的运行非常重要。 会话与客户在ZooKeeper服务中执行的每个操作相关联。
会话在ZooKeeper中扮演着非常重要的角色。 例如,ephemeral节点的整个概念是基于客户端和ZooKeeper服务器之间会话的概念。 ephemeral znode在客户端和ZooKeeper之间有会话的生命周期; 当这个会话结束时,这些节点将被ZooKeeper服务自动删除。
会话有一个超时期限,在连接到ZooKeeper服务时由应用程序或客户端指定。 客户端发送一个请求的超时作为创建连接调用中的参数来创建一个以毫秒为单位指定的ZooKeeper。 如果连接保持空闲超过超时时间,则会话可能会过期。 会话到期由ZooKeeper集群本身管理,而不是由客户端管理。 当前的实现要求超时至少是tickTime的两倍,最多为tickTime的20倍。
指定正确的会话超时取决于各种因素,如网络拥塞,应用程序逻辑的复杂性,甚至ZooKeeper ensemble的大小。 例如,在一个非常繁忙和拥挤的网络中,如果延迟很高,那么会话超时会非常低,会导致会话过期。 同样,如果你的ensemble很大,建议有一个更大的超时时间。 此外,如果应用程序看到频繁的连接丢失,增加会话超时可能会有用。 然而,另一个警告是它不应该对应用程序的核心逻辑产生不经意的影响。
客户端通过向ZooKeeper服务发送ping请求(心跳)来保持活动。 这些心跳是由客户端类库自动发送的,因此,应用程序员不必担心会话保持活跃状态。 客户端和ZooKeeper服务器之间的会话使用TCP连接进行维护。 两个连续的心跳之间的间隔应该保持低,这样客户端和ZooKeeper服务器之间的连接失败可以很早被检测到,并且可以进行重新连接尝试。 重新连接到另一个ZooKeeper服务器通常由客户端类库以透明方式完成。 当重新连接到同一个ensemble的不同服务器时,客户端创建的现有会话和关联的ephemeral znode仍然有效。 对于在客户端和服务器之间维护的单个会话,ZooKeeper保证通常按照FIFO顺序的排序。
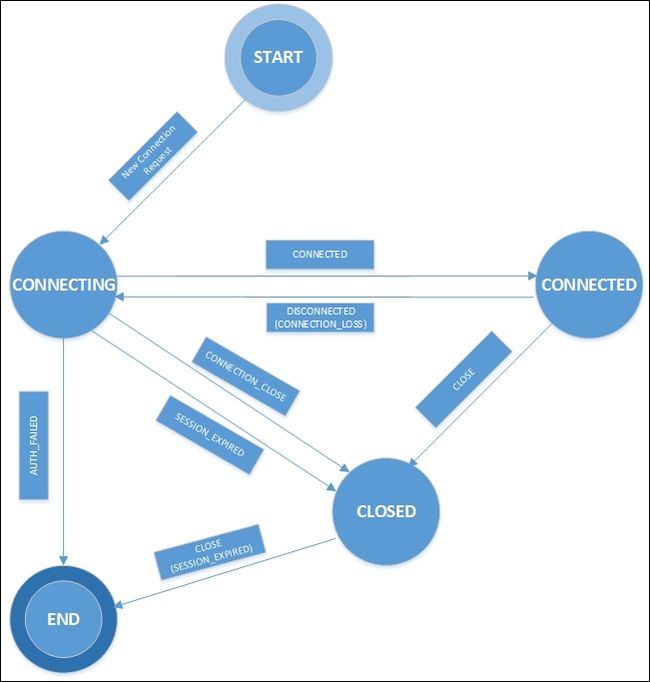
如前一节所述,应用程序使用客户端类库与ZooKeeper服务建立会话。 表示连接对象的句柄由ZooKeeper客户端API返回给应用程序。 这个ZooKeeper连接对象在其创建和结束之间的时间内通过不同的状态转换。 连接对象会持续到客户端程序的连接正常关闭或会话由于超时而终止。
一旦连接对象被创建,它就从CONNECTING状态开始,客户端库尝试连接到ZooKeeper ensemble中的一个服务器。 当连接到ZooKeeper服务时,对象转换到CONNECTED状态。 由于事件(如会话到期和身份验证失败),或者应用程序正常关闭使用库调用的连接,对象的状态将转到CLOSED状态。
下图显示了ZooKeeper客户端会话的状态转换:
三 ZooKeeper事务的实现
在前面的章节中,我们看到了ZooKeeper如何在服务器上运行,以及客户端如何连接到这些服务器,建立会话并在ZooKeeper服务中执行操作。 在服务器ensemble中,服务器被选为领导者,剩下的所有服务器都成为追随者。 领导处理所有更改ZooKeeper服务的请求。 追随者收到领导者的更新,并通过多数共识机制,在整个ensemble中保持一致的状态。 ZooKeeper服务负责替换失败的领导者,并将跟随者与领导者同步,整个过程对于客户端应用程序是完全透明的。
该服务依靠复制机制来确保所有更新在构成ensemble的所有服务器中都是永久的。 每个服务器都维护着一个核心数据库,它代表了ZooKeeper命名空间的整个状态。 为了确保更新是持久的,并在服务器崩溃时可以恢复,更新记录到本地磁盘。 此外,写入操作在序列化到磁盘之后才会应用到内存数据库。
ZooKeeper使用一个称为 ZooKeeper Atomic Broadcast (ZAB)的特定原子消息广播协议。 该协议确保ensemble中的本地副本永不分离。 此外,ZAB协议是原子的,所以协议保证更新要不全部成功,或者全部失败。
复制的数据库、ZAB协议与领导者选举机制一起构成了ZooKeeper服务实现的核心。 ZooKeeper服务名称空间中的更新或写入以及读取操作由这些核心组件处理,如下图所示,也可以在http://zookeeper.apache.org/doc/r3.4.6/zookeeperOver.html#fg_zkComponents中找到:

在ZooKeeper实现中,读取请求(如exists,getData和getChildren)由客户端连接的ZooKeeper服务器本地处理。 这使得ZooKeeper中的读操作非常快。 写入或更新请求,例如create,delete和setData被转发给ensemble中的领导者。 领导者执行客户请求作为一个事务。 这个事务类似于数据库管理系统中事务的概念。
ZooKeeper事务也包含成功执行请求所需的所有步骤作为单个工作单元,并且以原子方式应用更新。 此外,事务满足隔离性,这意味着任何事务都不会受到任何其他事务的干扰。 ZooKeeper服务中的事务是幂等的。 事务通过一个事务标识符(zxid)来标识,它是一个64位整数,分为两部分:纪元和计数器,每个部分都是32位。
事务处理包括ZooKeeper的两个步骤:领导选举和原子消息广播协议。 这类似于两阶段提交协议,也包括领导者选举和原子消息广播协议。
四 第一阶段——领导者选举
ensemble中的服务器经过一个选举主服务器的过程,称为领导者。 ensemble中的其他服务器被称为追随者。
参与领导选举算法的每个服务器都有一个名为“LOOKING”的状态。如果一个领导者已经存在于整个系统中,那么对等服务器将通知新的参与者服务器关于现有的领导者。在了解领导者后,新的服务器与领导者保持同步状态。
一个领导者不存在于ensemble中时,ZooKeeper在服务器ensemble中运行领导者选举算法。 在这种情况下,首先,所有服务器都处于LOOKING状态。 该算法指示服务器交换消息以选举领导者。 当参与者服务器汇聚在一个特定服务器的共同选择上时,该算法就会停止,这个服务器就成为领导者。 赢得这次选举的服务器进入LEADING状态,而ensemble中的其他服务器进入FOLLOWING状态。
参与者服务器与他们的对等服务器交换的消息,包含服务器的标识符(sid)和它所执行的最近事务ID(zxid)。每个参与服务器在接收到对等服务器的消息后,将自己的sid和zxid与它所接收的消息进行比较。如果接收到的zxid大于服务器所持有的zxid,则服务器接受接收到的zxid,否则,它将自己的zxid设置并将其自己的zxid设置为ensemble中的对等服务器。
在这个算法的最后,拥有最近事务ID(zxid)的服务器赢得了领导选举算法。在算法完成之后,追随者服务器将其状态与所选出的领导者同步。
领导者选举的下一步是领导者激活。 新当选的领导者提出了NEW_LEADER建议,并且只有在NEW_LEADER提案被ensemble中的大多数服务器(quorum)确认之后,领导才会被激活。在新领导人的NEW_LEADER提议被提交之前,新领导人不会接受新提议。
五 第二阶段——原子消息广播协议
ZooKeeper中的所有写入请求都被转发给领导者。 领导者向ensemble的追随者广播其更新。 只有在大多数追随者承认他们坚持这个变化之后,领导者才会进行更新。 ZooKeeper使用ZAB协议来实现共识,这被设计为原子的。 因此,更新成功或失败。 在领导失败时,ensemble中的其他服务器进入领导者选举算法,以选出其中的新领导者。
Tips
ZAB: High-performance broadcast for primary-backup systems by Junqueira, F.P; Reed, > B.C; Serafini. M(LADIS 2008, in: Proceedings of the 2nd Workshop on Large-Scale Distributed Systems > and Middleware)
可以通过以下链接访问IEEE Xplore上的ZAB文章:http://bit.ly/1v3N1NN
ZAB保证了在递送事务和提交事务时的严格顺序。通过原子消息处理事务可以如下图所示:
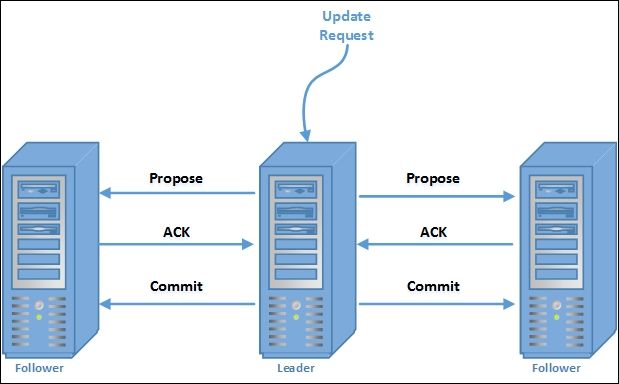
两阶段提交保证了事务的顺序。 在协议中,一旦quorum确认一个事务,领导者就提交,而追随者将其确认记录在磁盘上。
Tips
除了领导者和追随者之外,ZooKeeper ensemble中的服务器还有第三个特征,称为观察者。 观察者和追随者在概念上是相似的,因为他们都承诺领导者的建议。 然而,与追随者不同,观察者不参与两阶段提交过程的投票过程。 观察者有助于ZooKeeper服务中读取请求的可伸缩性,并有助于在跨越多个数据中心的ZooKeeper集成中传播更新。
六 本地存储和快照
ZooKeeper服务器使用本地存储来保存事务。 事务记录到事务日志中,类似于在数据库系统中使用的顺序附加日志文件的方法。 ZooKeeper服务器使用预先分配的文件将事务刷新到磁盘介质上。 在ZooKeeper事务处理的两阶段协议中,只有在强制将事务写入事务日志后,服务器才会确认提议。 由于ZooKeeper事务日志的写入速度很快,所以在一个与服务器的引导设备分开的磁盘中配置事务日志是非常重要的。
ZooKeeper服务中的服务器还保存ZooKeeper树或命名空间的时间点副本或快照到本地文件系统。 服务器不需要与ensemble的其他成员协调来保存这些快照。 此外,快照处理与ZooKeeper服务器的正常运行进行异步操作。
ZooKeeper快照文件和事务日志能够在发生灾难性故障或用户错误时恢复数据。 数据目录由ZooKeeper配置文件中的dataDir参数指定,数据日志目录由dataLogDir参数指定。