小夕从7月份开始收到第一场面试邀请,到9月初基本结束了校招(面够了面够了T_T),深深的意识到今年的对话系统/chatbot方向是真的超级火呀。从微软主打情感计算的小冰,到百度主打智能家庭(与车联网?)的DuerOS和UNIT,到渗透在阿里许多产品的全能型智能客服小蜜,以及腾讯的小微和搜狗的汪仔,更不必说那些大佬坐镇的独角兽公司了,小夕深感以对话为主战场的NLP之风在工业界愈演愈烈,吓得小夕赶紧码了这篇文章。
1. 扫盲
对话的概念很大,从输入形式上分为文本和语音,本文当然只考虑文本。从对话目的上分为任务型对话与非任务型/闲聊型对话。顾名思义,任务型对话就是为了解决任务而进行的对话,比如你让Siri帮你定闹钟、发短信等,而闲聊型对话当然就是human-to-human的正常聊天啦。本文就不讨论任务型对话了,有兴趣的同学可以戳这里扫扫盲,本文聚焦在非任务型对话的多轮对话问题上。
要完成对话的建模,目前主要分为检索式、生成式以及检索与生成融合的方式。顾名思义,检索式就是通过检索与匹配的方式从已有的大量candidate responses中找出最合适的那个作为response;生成式则是事先通过训练来把对话知识塞进模型中,推理的时候首先模型的encoder部分去读历史对话,然后模型中的decoder/语言模型部分直接生成相应的回复;检索与生成相结合的方法则玩法很多了,比如用生成模型来做检索模型的reranker,用生成模型来作改写,用生成模型生成的response来作为检索模型的一条response等。限于篇幅,本文只讲纯检索式的,其他的以后再说(maybe不会太久╮( ̄▽ ̄"")╭)。
2. 检索式模型的套路
检索式对话的一般套路是首先构建一个由大量query-response pair构成的知识库(比如从豆瓣、贴吧等地方抽取),然后将对话中最后一次的回复作为query,通过经典的信息检索方式(倒排索引+TFIDF/BM25)作q-q匹配来召回若干相关的candidate responses。注意,这一步实在太粗糙了,完全没有考虑语义,所以直接使用检索分数来挑选最优response显然是太过简单粗暴不靠谱。所以我们还需要使用考虑语义的深度文本匹配模型来将历史对话与这些检索出来的candidate responses进行matching/reranking,从而挑选出一个更加合适的response。
那么怎么进行文本的深度匹配呢?
一个很简单的做法是直接把复述识别/自然语言推理/检索式问答这些相关领域的文本匹配模型直接拿来用,但是显然这样仅仅建模的是单轮对话,于是聊天机器人就变成了只有7秒记忆的金鱼╮(╯▽╰)╭,因此,建模多轮对话是非常有必要的。
不过了解一下文本匹配模型是很有帮助的。这方面今年COLING有一篇文章[6]总结的不错,把基于表示与基于交互的SOTA匹配模型都给详细总结对比了。
深度学习模型复现难?看看这篇句子对模型的复现论文这是 PaperDaily 的第82篇文章 本期推荐的论文笔记来自 PaperWeekly 社区用户@zhkun。本文是 COLING 2018 的 Best Reproduction Paper,文章对 sentence pair modeling 进行了比较全面的介绍,针对目前表现最好的几个模型进行了重现和对比,并且基本上实现了原文章中声明的效果,非常值得参考。 关于作者:张琨,中国科学技术大学博士生,研究方向为自然语言处理。 ■ 论文 | Neural Network Models for Paraphrase Identification, Semantic Textual Similarity, Natural Language Inference, and Question Answering ■ 链接 | https://www.paperweekly.site/papers/2042 ■ 作者 |Wuwei Lan / Wei Xu 论文介绍 这篇文章是 COLING 2018 的 Best Reproduction Paper,文章主要对现有的做句子对任务的最好的几个模型进行了重现,并且作者实现出来的效果和原文章声称的效果相差不多,这点还是很厉害的,而且作者对语义理解的集中任务也做了相关梳理,文章简单易读,还是很值得一看的。 任务 句子对建模是 NLP,NLU 中比较基础,并扮演着重要角色的任务,主要集中在语义理解,语义交互上,这也是我自己的一个研究方向,大致有这几类任务: 1. Semantic Textual Similarity (STS):判断两个句子的语义相似程度(measureing the degree of equivalence in the underlying semantics of paired snippets of text); 2. Natural Language Inference (NLI) :也叫 Recognizing Textual Entailment (RTE),判断两个句子在语义上是否存在推断关系,相对任务一更复杂一些,不仅仅是考虑相似,而且也考虑了推理; 3. Paraphrase Identification (PI):判断两个句子是否表达同样的意思(identifing whether two sentences express the same meaning); 4. Question Answering (QA):主要是指选择出来最符合问题的答案,是在给定的答案中进行选择,而不是生成; 5. Machine Comprehension (MC):判断一个句子和一个段落之间的关系,从大段落中找出存在答案的小段落,对比的两个内容更加复杂一些。 论文模型 有了任务,作者选取了集中目前情况下最好的模型,因为原文中每个模型可能只针对了某些任务进行了很多优化,那这些模型是否真的有效呢,作者考虑这些模型在所有的任务上进行比较,在介绍模型之前,作者首先介绍了句子对建模的一般框架: 一般框架 1. 输入层:适用预训练或者参与训练的词向量对输入中的每个词进行向量表示,比较有名的 Word2Vec,GloVe,也可以使用子序列的方法,例如 character-level embedding; 2. 情境编码层:将句子所处的情境信息编码表示,从而更好的理解目标句子的语义,常用的例如 CNN,HighWay Network 等,如果是句子语义表示的方法,一般到这里就结束了,接下来会根据具体的任务直接使用这一层得到语义表示; 3. 交互和注意力层:该层是可选的,句子语义表示有时候也会用到,但更多的是词匹配方法用到的,通过注意力机制建模两个句子在词层面的匹配对齐关系,从而在更细粒度上进行句子对建模,个人认为句子语义表示也会用到这些,只是句子语义表示最后会得到一个语义表示的向量,而词匹配的方法不一定得到句子语义的向量; 4. 输出分类层:根据不同的任务,使用 CNN,LSTM,MLP 等进行分类判断。 下图展示了一些句子语义表示的模型的基本框架:
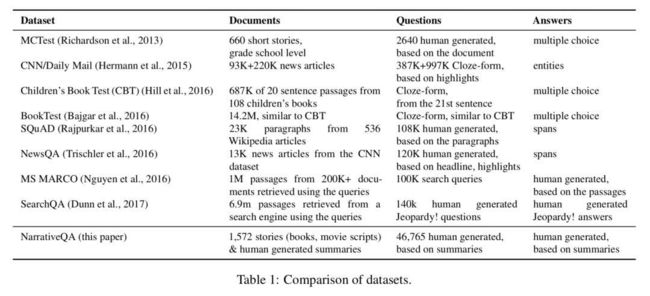
有了这个一般的框架,接下来作者选取了集中目前最好的模型进行重现。 模型选择 1. InferSent[1]:BiLSTM+max-pooling; 2. SSE[2]:如图 1,和 InferSent 比较类似; 3. DecAtt[3]:词匹配模型的代表,利用注意力机制得到句子 1 中的每个词和句子 2 中的所有词的紧密程度,然后用句子 2 中的所有词的隐层状态,做加权和表示句子 1 中的每个词; 4. ESIM[4]:考虑了一些词本身的特征信息,和 DecAtt 比较类似; 5. PWIM[5]:在得到每个词的隐层状态之后,通过不同的相似度计算方法得到词对之间相似关系,最后利用 CNN 进行分类。 数据 为了更好的展示每个数据的情况,在这里直接用下图展示作者使用到的数据集:

结果 直接上结果,上图是原文章中的结果,下图是作者重现的结果:

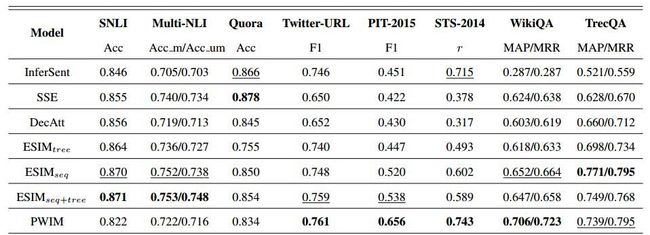
从结果上看,作者实现的效果还是很厉害的,基本上跟原文章声明的不相上下,当然由于不是针对特定任务进行特别优化,所有效果还是有一点点差的,但基本上可以认为是实现了原来的效果,而且作者也发现了一些有意思的现象,例如:表现最好的就是 ESIM,个人感觉这里面加入了很多次本身的一些信息,例如近义词,反义词,上下位信息等,这些信息其实对句子语义理解十分重要。 以上就是这篇文章的整体介绍,作者完整实现了这些方法,并在不同的数据集上进行验证,工作量还是很大的,而且对句子对建模进行了比较完整的介绍,还是很有意思的。 引用 [1]. A. Conneau, D. Kiela, H. Schwenk, L. Barrault, A. Bordes, Supervised Learning of Universal Sentence Representations from Natural Language Inference Data [2]. Shortcut-Stacked Sentence Encoders for Multi-Domain Inference, Yixin Nie and Mohit Bansal. [3]. A Decomposable Attention Model for Natural Language Inference, AnkurP.Parikh, Oscar Täckstöm, Dipanjan Das, Jakob Uszkoreit [4]. Enhanced LSTM for Natural Language Inference, Qian Chen, Xiaodan Zhu, Zhenhua Ling, Si Wei, Hui Jiang, Diana Inkpen [5]. Hua He and Jimmy Lin. Pairwise Word Interaction Modeling with Deep Neural Networks for Semantic Similarity Measurement
同媒体快讯相关快讯
|
|
|
NLP︱高级词向量表达(一)——GloVe(理论、相关测评结果、R&python实现、相关应用)
高级词向量三部曲:1、NLP︱高级词向量表达(一)——GloVe(理论、相关测评结果、R&python实现、相关应用) 一、理论简述1、word2vecword2vec:与一般的共现计数不同,word2vec主要来预测单词周边的单词,在嵌入空间里相似度的维度可以用向量的减法来进行类别测试。 弊端:
2、GloVe
GloVe综合了LSA、CBOW的优点,训练更快、对于大规模语料算法的扩展性也很好、在小语料或者小向量上性能表现也很好。 二、测评
. 1、词向量测评方法一直以来,如何测评词向量还是一件比较头疼的事情。
类比数据来源:https://code.google.com/p/word2vec/source/browse/trunk/questions-words.txt
以下语法和语义例子来源于:https://code.google.com/p/word2vec/source/browse/trunk/questions-words.txt
词向量类比:以下语法和语义例子来源于:https://code.google.com/p/word2vec/source/browse/trunk/questions-words.txt
2、测评结果
类比评测和超参数: 相关性评测结果:
命名实体识别(NER):找到人名,地名和机构名 . 3、利用词向量解决歧义问题也许你寄希望于一个词向量能捕获所有的语义信息(例如run即是动车也是名词),但是什么样的词向量都不能很好地进行凸显。 . 三、Glove实现&R&python1、Glove训练参数
. 2、用R&python实现python:python-glove(参考博客:glove入门实战) R:text2vec(参考博客:重磅︱R+NLP:text2vec包——New 文本分析生态系统 No.1(一,简介)) . 四、相关应用1、glove+LSTM:命名实体识别用(Keras)实现,glove词向量来源: http://nlp.stanford.edu/data/glove.6B.zip 一开始输入的是7类golve词向量。The model is an LSTM over a convolutional layer which itself trains over a sequence of seven glove embedding vectors (three previous words, word for the current label, three following words). CV categorical accuracy and weighted F1 is about 98.2%. To assess the test set performance we are ensembling the model outputs from each CV fold and average over the predictions. 来源于github:https://github.com/thomasjungblut/ner-sequencelearning 2、PAPER:词向量的擦除进行情感分类、错误稽查Understanding Neural Networks Through Representation Erasure(arXiv: 1612.08220) 提出了一种通用的方法分析和解释了神经网络模型的决策——这种方法通过擦除输入表示的某些部分,比如将输入词向量的某些维、隐藏层的一些神经元或者输入的一些词。我们提出了几种方法来分析这种擦除的影响,比如比较擦除前后模型的评估结果的差异,以及使用强化学习来选择要删除的最小输入词集合,使用于分类的神经网络模型的分类结果发生改变。 **分析揭示了 Word2Vec 和 Glove 产生的词向量之间存在一些明显的差异,同时也表明训练语料中的词频对产生的词的表达有很大的影响;
|
NLP︱高级词向量表达(二)——FastText(简述、学习笔记)
. 高级词向量三部曲:1、NLP︱高级词向量表达(一)——GloVe(理论、相关测评结果、R&python实现、相关应用) 如何在python 非常简单训练FastText,可见笔者博客:极简使用︱Gemsim-FastText 词向量训练以及OOV(out-of-word)问题有效解决 一、FastText架构
. 1、fastText 架构原理
fastText 模型输入一个词的序列(一段文本或者一句话),输出这个词序列属于不同类别的概率。 . |
|
| VDCNN
论文链接:Very Deep Convolutional Networks for Text Classification 代码:https://github.com/zonetrooper32/VDCNN
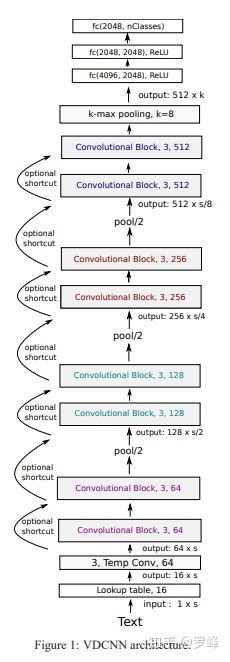
深度学习在NLP领域的应用基本被RNN/LSTM垄断,而且基本都是浅层网络(1层或2层),大家普遍认为加深网络深度并没有太大意义。而在图像和语音领域则正趋向于使用更深层次的卷积神经网络。本文作者试图探究深层的卷积网络在NLP领域的效果。作者认为卷积网络之所以能在图像领域取得较好的效果是因为卷积操作擅长提取图像像素之间的结构关系,而文本信息也有类似的结构关系:上下词语、短语、句子之间,难点在于如何有效的学习句子的深层表示。 本文提出了一种新的架构-VDCNN, 它基于字符级别(character level),只利用小尺度的卷积核池化操作,包含了29个卷积层,在文本分类任务中的多个数据集上取得了state of art 的效果。
整体架构如Figure1所示,句子长度为 ,首先会经过lookup层,每个字符映射为一个 维的向量,因此文本被表示为一个大小为 的tensor。在本文中 的长度固定为1024, 的大小固定为16。然后,网络会经过三次池化操作。每次池化之前是若干个"Convolutional Block"。滤波器数量遵循两个原则:
论文说这样可以减少内存占用,还没想明白是为什么。—— ??
三次池化操作,每次池化特征图的大小都会减半,所以滤波器的数量也会相应double。如Figure1所示,滤波器的数量有三个量级,分别是128,256,512。最终Convolutional Block的输出tensor大小为 ,其中 , 。在本文中 的大小固定为1024,因此 。而实际上 的长度可以是不固定的,尤其在使用Attention的时候。 Convolutional Block的输出会经过一个k-max pooling变成固定维度为 的tensor,然后经过三个全连接。本文中k的大小取值为8,全连接的神经元数量为2048。 这里的池化操作使用的 k-max pooling,一般的最大池化层是在提取的特征中只取最大的值作为保留值,其他值全部抛弃。CNN中采用Max Pooling操作有几个好处:首先,这个操作可以保证特征的位置与旋转不变性,因为不论这个强特征在哪个位置出现,都会不考虑其出现位置而能把它提出来。对于图像处理来说这种位置与旋转不变性是很好的特性,但是对于NLP来说,这个特性其实并不一定是好事,因为在很多NLP的应用场合,特征的出现位置信息是很重要的,比如主语出现位置一般在句子头,宾语一般出现在句子尾等等,而有些强特征又会多次出现这些位置,这些信息其实有时候对于分类任务来说还是很重要的,但是Max Pooling 基本把这些信息抛掉了。其次,位置信息在这一步完全丢失。 而 k-max pooling 的意思是:原先的Max Pooling Over Time从Convolution层一系列特征值中只取最强的那个值,那么我们思路可以扩展一下,k-max pooling可以取所有特征值中得分在Top –K的值,并保留这些特征值原始的先后顺序,就是说通过多保留一些特征信息供后续阶段使用。很明显,k-max pooling可以表达同一类特征出现多次的情形,即可以表达某类特征的强度;另外,因为这些Top k特征值的相对顺序得以保留,所以应该说其保留了部分位置信息。
Convolutional Block的结构如Figure2所示,每个Convolutional Block由两个卷积层构成,每个卷积层后接了一个Temporal Batch Normalization,以及一个ReLU激活层。滤波器的大小固定为3,数量则遵循上文提到的两个原则。加深网络深度就是通过添加Convolutional Block的方式达到的。 Temporal Batch Normalization的原理和Batch Normalization是一样的,都是做了归一化处理,好处是降低了网络对学习率的敏感度,可以使用大学习率,并且有泛化的能力,不用替代了dropout。Temporal Batch Normalization和Batch Normalization的不同在于:Batch Normalization是在空间位置上做归一化(对应特征图的每一个像素),Temporal Batch Normalization是在时序位置上做归一化(对应特征图的每一个时刻向量)。
作者在深度为9,17,29,49的情况下做了实验。实验结果如Table5所示。
|

NLP︱高级词向量表达(三)——WordRank(简述)
查询king关键词,WordRank 、 word2vec、fastText三者效果对比: . 1、wordRank,与 word2vec、fastText三者对比来源博客:《WordRank embedding: “crowned” is most similar to “king”, not word2vec’s “Canute”》 2、wordRank,与 word2vec、GloVe三者对比来源paper:WordRank: Learning Word Embeddings via Robust Ranking
左图使用数据:WS-353 word similarity benchmark
相似词的寻找方面极佳,词类比方面不同数据集有不同精度。 结论:
综上,WordRank更适合语义类比,FastText更适合不同语料库下所有词频的语法类比。 . 高级词向量三部曲:1、NLP︱高级词向量表达(一)——GloVe(理论、相关测评结果、R&python实现、相关应用) |
|
|
文本分类相关的知识,所以在此做一个总结。 介绍 定义
应用
方法
传统方法分类流程

文本预处理英文
中文
文本表示将文本转换成计算机可理解的方式。一篇文档表示成向量,整个语料库表示成矩阵
特征权重计算
TF:词频率 TF*IDF: 词频率乘以逆文本频率
特征选择特征选择是根据某个评价指标独立的对原始特征项(词项)进行评分排序,从中选择得分最高的一些特征项,过滤掉其余的特征项,从而达到降维的目的

分类器
深度学习方法利用词向量表示文本,将没歌词表达为nn维稠密,连续的实数向量。
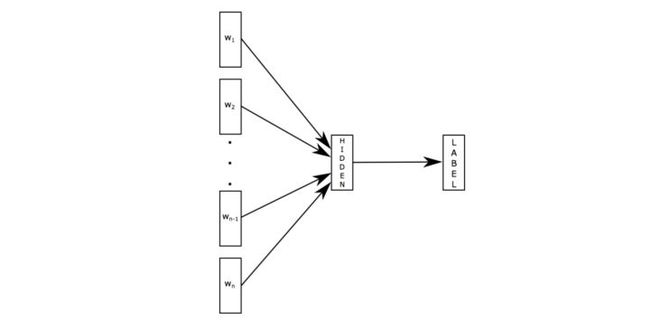
原理是把句子中所有的词进行lookup得到词向量之后,对向量进行平均(某种意义上可以理解为只有一个avg pooling特殊CNN),然后直接接 softmax 层预测label。在label比较多的时候,为了降低计算量,论文最后一层采用了层次softmax的方法,既根据label的频次建立哈夫曼树,每个label对应一个哈夫曼编码,每个哈夫曼树节点具有一个向量作为参数进行更新,预测的时候隐层输出与每个哈夫曼树节点向量做点乘,根据结果决定向左右哪个方向移动,最终落到某个label对应的节点上。

详细原理如下: 首先,对句子做padding或者截断,保证句子长度为固定值 ,单词embedding成 维度的向量,这样句子被表示为(s,d)(s,d)大小的矩阵(类比图像中的像素)。然后经过有 filter_size=(2,3,4) 的一维卷积层,每个filter_size 有两个输出 channel。第三层是一个1-max pooling层,这样不同长度句子经过pooling层之后都能变成定长的表示了,最后接一层全连接的 softmax 层,输出每个类别的概率。
利用前向和后向RNN得到每个词的前向和后向上下文的表示:
编辑于 2018-07-20
|
|
基础比较差的同学可以看这篇文章,从2013年的DSSM[9]开始入手,慢慢补。篇幅所限,加上这方面研究相对很充分了,小夕就不展开讲啦。所以话说回来,将多轮对话与候选回复进行匹配的正确方式是什么呢?
3. 论文串烧
一切还要从两年前的秋天说起,曾经,有一个少年。。。
算了算了,还是正经点吧,要不然没法写了╮( ̄▽ ̄"")╭总之,小夕从众多鱼龙混杂的检索式多轮对话的论文里精选出如下4篇进行串烧(按时间顺序,从经典到state-of-art),包括:
- EMNLP2016 百度自然语言处理部的xiangyang大佬
的Multi-view[1]pkpk
- ACL2017 MSRA
大佬的SMN[2]吴俣
- COLING2018 上交的DUA[3]
- ACL2018 百度自然语言处理部xiangyang大佬和lilu女神的DAM[4]
不过不要怕,小夕的论文分享总是浅显易懂还带点萌( ̄∇ ̄)
必须要提的:Multi-view model
想一下,怎么才能从单轮q-r的匹配扩展到多轮呢?一个最最最简单的想法就是直接把多轮对话首尾连接变成一个长长的单轮╮( ̄▽ ̄"")╭比如这种:
如上图,首先将各轮的对话连接起来(这里在连接处插入一个"__SOS__"的token),然后这里用RNN系网络取最后时刻隐态的方法分别得到query和response的向量表示,进而将这俩向量通过 的方法得到匹配分值(M为网络参数),进而通过 得到匹配概率(p为参数)。当然,其实这里本质上就是一个基于表示的文本匹配模型,所以完全可以用更复杂的表示方法和匹配函数(如SSE模型[8])来完成这个过程。
聪明的童鞋肯定可以想到,显然这种将长长的word embedding sequence直接塞进网络得到整个多轮对话的表示(context embedding)的做法未免太看得起神经网络对文本的表示能力了,因此作者提出,不仅要在这个word-level上进行匹配,而且还要在一个更高的level上进行匹配,这个level称为utterance-level(即把对话中的每条文本(utterance)看作word)。
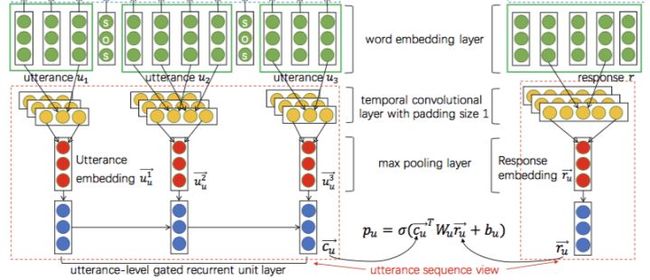
如上图的绿色->黄色->红色的部分,首先得到对话的每条文本(utterance)的向量表示(这里用的14年Kim提出的那个经典CNN),这样历史的多轮对话就变成了一个utterance embedding sequence。之后再通过一层Gated RNN(GRU、LSTM等)把无用的utterances中的噪声滤掉,进而取最后一个时刻的隐状态得到整个多轮对话(context)的context embedding啦。
拿到context embedding后,就可以跟之前word-level中的做法一样,得到对话与candidate response的匹配概率啦。最后,将word-level得到的匹配概率与utterance-level得到的匹配概率加起来就是最终的结果。
实验结果如下
可以看到utterance-level确实是明显比word-level work的,而且集成一下提升效果更显著。因此从这篇论文后的大部分论文也follow了这种对每条utterance分别进行处理(表示或交互),而后对utterance embedding sequence用Gated RNN进行过滤和得到context embedding的思路。
而到了2017年,文本匹配的研究明显变得更加成(花)熟(哨),各种花式attention带来了匹配效果的大幅度提升,这也标志着检索式多轮对话这方面的玩法也将变得丰(麻)富(烦)。
一次大大的进化:SMN model
如果说Multi-view模型在检索式多轮对话领域开了个好头,那么SMN则是将这个大框架往前推进了一大步。虽然表面上看Multi-view模型与SMN模型相去甚远,但是熟悉文本匹配的小伙伴应该有注意到,16年左右,基于交互的匹配模型开始代替基于表示的匹配模型成为主流[6],因此在Multi-view中内嵌的匹配模型是基于表示的,而到了17年的这个SMN模型则使用了前沿的基于交互的匹配方法。另外除了改变文本匹配的“派系”之外,SMN还有一个比较亮的操作是在做文本匹配的时候考虑了文本的不同粒度 (granularity) 之间的匹配,这个操作也成为了后续一些paper的follow的点。
对文本匹配比较熟悉的同学应该在AAAI2016看过这么一篇paper:
Text Matching as Image Recognition (参考文献[5])
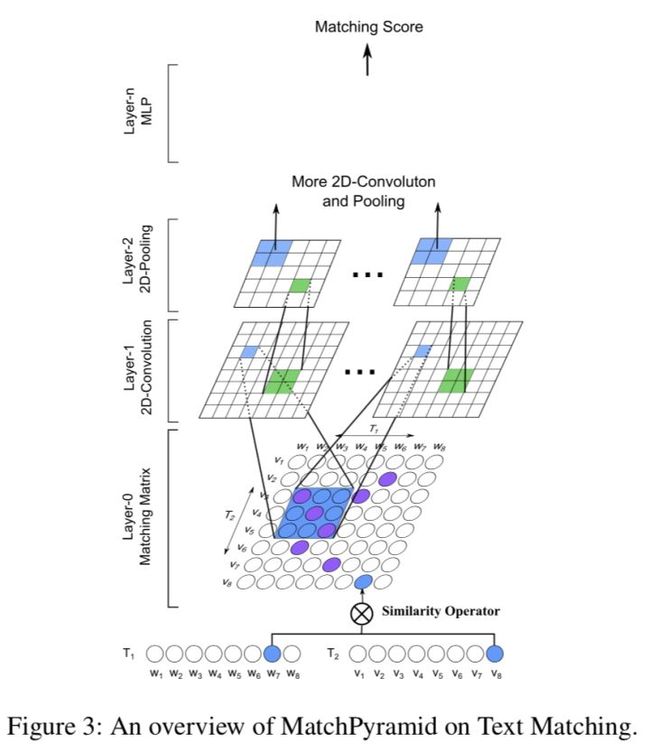
如图,基本思想就是,使用传统的attention来计算出两个文本的word-level对齐矩阵/相似度矩阵后,将该矩阵看成一个图像,然后使用图像分类模型(如CNN)来得到更高level的相似度特征表示(比如phrase level, segment level等),进而最终得到全局的相似度匹配特征。这也是最早的几个交互式文本匹配模型之一。
SMN这篇paper就是采用了这个思想。给定一个candidate response,在生成word-level的每个utterance的向量表示的时候,首先计算出历史上每个utterance跟该response的对齐矩阵,然后对每个对齐矩阵,均使用上面这种图像分类的思想生成high-level表征文本对相似度的特征向量作为该utterance的向量表示(utterance embedding)。
之后就是使用前面Multi-view中的做法,从这个utterance embedding sequence中得到整个对话的context embedding,最后将该context embedding和之前的word-level下得到的context embedding与response的向量去计算相似度了。
不过作者这里在计算对齐矩阵和得到context embedding的时候,用了更复杂一些的方法。如图
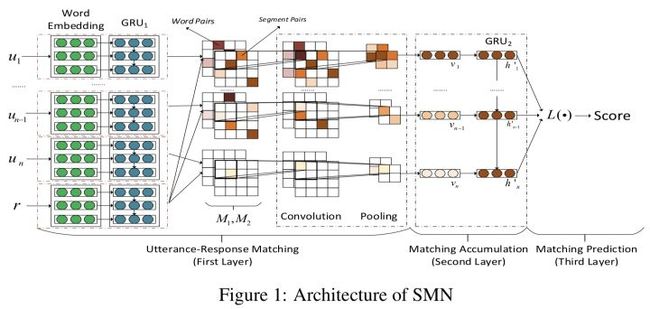
在计算对齐矩阵的时候,作者不仅用了原始的word embedding,而且同时用了RNN系模型对文本encoding之后的隐状态(即编码过上下文信息的word embedding,可以看作phrase-level的"word embedding"了),这样就生成了两份对齐矩阵,然后这样将两份对齐矩阵作为两个channel丢进“图像分类模型”,从而保证了即使图像分类模型很浅,也能抽取出比较high-level的特征,得到高质量的utterance embedding。
另外,作者这里在得到最终的context embedding的时候,除了使用RNN最后一个隐状态的传统做法(记为 )外,作者还额外实验了对顶层各个time step的隐状态进行加权求和(权重可训练)的方式( )以及更复杂的集成utterance自身表示的信息并使用self-attention的方式( ),实验结果表明,总的来看 的方式稍好一些(不过考虑到额外引入的计算和存储开销,一般不值得这样做)。有兴趣的同学可以去看原paper,这里就不展开讲啦。
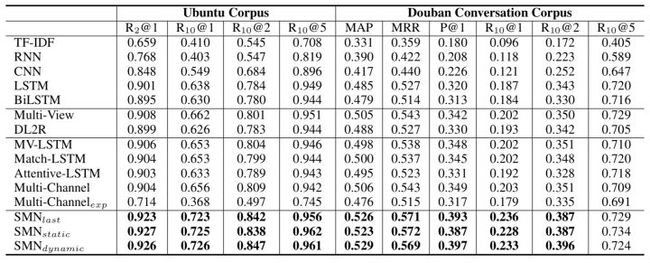
从实验效果来看,SMN相比较之前的Multi-view有很大的提升,这也说明了:
- 在q-r匹配上,基于交互的模型相比基于表示的模型有更大的优势,这一点与检索式问答和NLI任务中的实验表现一致;
- 对文本进行多粒度表示是很有必要的。
utterance也要深度encoding!DUA model
虽然看似SMN已经考虑很周到了,但是如果细想一下,其实SMN的建模方式还是跟现实中人们的聊天习惯存在不小的gap的。其中一个方面就是,Multi-view和SMN都没有重视utterances之间的语义关系,仅仅是通过一层Gated RNN进行了软过滤和简单encoding。然而其实很多时候建模utterances之间的关系是很有必要的,甚至对于过滤来说也是很重要的信息,这也是DUA的motivation。我们知道,其实聊天中很少从头到尾都是一个主题,比如下面的对话:
case1:
u1-> 路人甲:小夕,中秋节你去哪里玩儿啦?
u2-> 小夕:当然是去买买买呀~
u3-> 路人甲:你之前不是想去爬百望山嘛?没去嘛?
u4-> 小夕:想去呀,然鹅她们去玩儿都不带我(。 ́︿ ̀。)
u5-> 路人甲:你稍等下啊,我下楼取个快递
u6-> 小夕:去吧去吧,顺便帮我买个辣条!
u7-> 路人甲:好呀,要啥口味的?鸡肉味?
u8-> 小夕:这特喵的还分口味?
u9-> 路人甲:回来啦,对了,要不然下周我带你去吧?
u10-> 小夕:好呀好呀,喵喵喵~
这里如果把小夕看作是检索式chatbot,假如对话进行到第6步(u6),这时候最后一个utterance是u5,也就是“你稍等下啊,我下楼去取个快递”。显然,这时候其实相当于对话的话题发生了剧烈偏移,如果这时候小夕去跟一堆candidate responses做匹配的时候还去考虑u1-u4这些爬山相关的utterances的话,显然就容易召回跟u5很不相关的回复。同样的道理,如果对话进行到u8,其实这时候真正有用的historical utterances是u6-u7;对话进行到u10的时候,有用的utterances又变成了u1-u4。
除此之外,对话中还容易夹杂一些类似于停用词的噪声,比如
case2:
u1-> 路人乙:小夕,明天约约约?
u2-> 小夕:。。。
u3-> 路人甲:哈哈
u4-> 小夕:应该木有时间
这里的u2和u3就是类似于停用词的“停用utterance”,所以对于这一类utterance,最好的办法就是忽略掉而不是让它们参与匹配。
怎么解决上述这两类问题呢?那就直接上这个让人看着灰常懵逼的DUA的模型图吧:
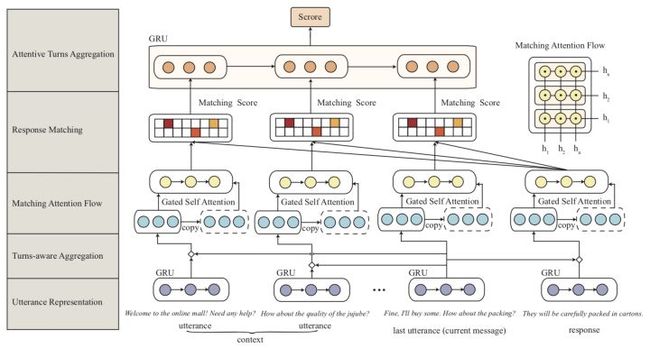
如图,这个图乍一看有点乱(其实画的确实不怎么样(作者应该不会看我的文章吧2333))
啊啊啊作者竟然真的看我文章了QAQ论文作者在评论区出现的那一刻我的心情是复杂的!
论文里的公式标记也用的乱乱的(尤其第3.3节凭空冒出来的n弄得我懵逼了好久,到底是不是3.1节的n,是的话这里貌似就不对了,如果不是,这里又代表啥);一些细节也没交代清楚(比如3.1的S到底是个矩阵还是向量,如果是向量,那么怎么得到的这个向量?是矩阵的话3.2节的聚合又不对了)。
超级感谢论文作者的耐心解惑,一下子清楚多啦。如下:NowOrNever
首先,3.3节的n与3.1节的n是相同的指代,如果作者觉得指代相同的时候有什么问题的话,欢迎进一步交流。同时,非常抱歉我们在3.1里把3.2中定义的东西用了进来,其中3.1节的S_k指的是3.2节中的S的每一个组成部分,即,S_1, S_2,...,S_t,S_r。如果还有相关问题,欢迎随时来交流!
不过,其实这里的思想很明确,就是说,以前的paper呀,得到utterance embedding后就直接拿去RNN了,都没有像处理word embedding那样去好好做encoding,所以我们这里对utterance embedding也同样要做深度的encoding!
那么怎么做这个encoding呢?通过观察上面的俩cases可以发现,很多时候对话中是有hole的(比如上面case1中的u9的上一句话是u4,所以u5-u8形成了一个空洞),甚至可能很多个hole,所以这里做encoding的时候最合适的是使用self-attention而不是RNN更不是CNN。所以作者在这里先用了一层(加性)self-attention来把上下文编码进每个utterance embedding:
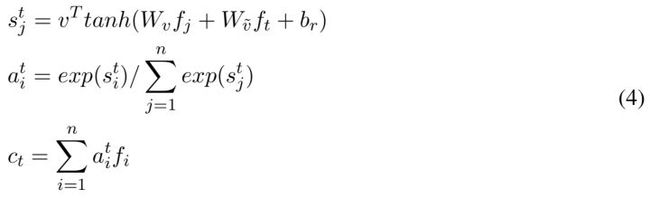
这里 是t时刻的utterance embedding(就是前面聚合操作之后的那个向量表示), 是其上下文(即全部时刻的utterance embedding,一共n个)。 通过这个encoding操作,一下子每个时刻的utterance都能跨越时间和空洞把自己的那一群小伙伴聚在一起啦。
然鹅显然self-attention丢失了utterance的顺序信息,因此作者这里又把encoding后的utterance embedding跟encoding前的utterance embedding拼接起来又过了一层Gated RNN:
Gated RNN(GRU、LSTM等)一方面可以按照时序进一步encoding,另一方面里面的输入门也起到了filter的作用,正好可以在加强encoding的同时把无用的信息过滤掉。看,这样就完成了当时的motivation,最后的这个utterance embedding可以说干净合理的多了。整个模型的其他部分则跟SMN基本没区别。

从实验结果来看,DUA的性能确实比SMN有了进一步明显的提升。
state-of-the-art:DAM model
这篇是多轮对话领域难得的好paper,可能xiangyang大佬太忙,都木有打打广告什么的╮( ̄▽ ̄"")╭。作者这里抛弃了之前的建模utterance embedding sequence的思路,而是把NLP很多领域的前沿操作优雅干净的整合为一个全新的框架来建模多轮对话问题,不仅模型非常work,实验章节也对模型各个component的特点和有效性进行了充分的探索和论证,是继Multi-view和SMN以来多轮对话领域又一个不得不提的经典模型。
另外,遇到一张清晰漂亮的模型图不容易哇,就直接上图吧
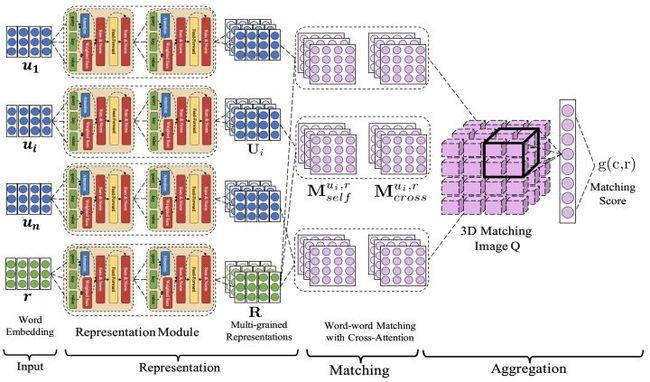
ps:这张图这么少女心,我猜是lilu女神画的。
还记得前面说的SMN的一个亮点是做了两级粒度的文本表示嘛?那么很自然的就有了一个问题:两级就够了嘛?有没有必要设置更多级呢?如果有必要的话,那么怎么去表示和学习这更多级粒度的语义表示呢?
首先答案当然是肯定的,17年的SSE文本匹配模型和今年特别火的ELMo[10]都说明了对文本的深层表示可以学习到更加高level的语义单元,然而我们知道像SSE和ELMo这种堆多层RNN的做法会极大的增加模型的推理代价,这极大的限制了它们在工业界的应用。而堆多层CNN在文本里又不容易调work,需要精细的设计网络并借助一些tricks,因此很自然的做法就是使用Transformer[11] encoder来得到文本的多级表示啦(没看过transformer那篇paper的赶紧去补啦,做NLP哪能不知道transformer)。
所以如图,DAM首先就用transformer的encoder来得到了每个utterance和response的多粒度文本表示(即图中的Representation部分),之后作者对每个utterance-response pair的每个粒度下的表示分别计算两个对齐矩阵(即图中的Matching部分)。
等下,怎么是俩对齐矩阵?除了传统的计算对齐矩阵的方式,还有新的玩法啦?
这里作者提出了一种更加深(隐)层(晦)的匹配方法,操作不难,但是为什么会work还是挺难以理解透彻的(虽然作者在5.2节已经有很努力的讲了)。总之,先来简单提一下传统的attention计算对齐矩阵的方式。
传统的方法无非就是把文本1中的word embedding sequence和文本2中的word embedding sequence进行词-词比较,这里的比较分为加性方法和乘性方法,基础差的同学可以看下面这段复习一下。
注:词-词比较的方式分为加性和乘性,加性就是将要比较的两个word embedding进行相加(相加前可以先过一个线性变换甚至MLP)然后激活后跟一个虚拟的向量做内积(其实这个虚拟向量就是个可训练的同维度向量,我理解的它存在的意义就是对每个维度的加法比较+激活后的结果进行scaling,毕竟维度不同方差也可能不同嘛),内积的结果就是对齐程度啦。乘性则容易理解一些,就是将两个word embedding直接进行相乘(准确说是内积)或中间夹一个可训练方阵(即 的形式),内积的结果就是对齐的程度啦。不过要记得当维度很高时,乘性方式最好对结果做个归一化以免进入softmax饱和区(参考Transformer)。

如上式,作者这里使用的是乘性的方式,这里的l就是指的第l级粒度, 是指的第i个utterance, 有 个词,response有 个词。这里就是说,对于每级语义粒度的每个utterance,都是将其中的每个词k去跟response中该粒度下的每个词t去算内积,从而得到一个 的对齐矩阵。
对于传统的attention,如果两个词在semantic或syntactic上离得近,就容易得到比较大的匹配值(如run和runs, do和what)。然而对于一些比较深层和隐晦的语义关系就很难直接匹配了(我们不能强求前面的网络把各级粒度的语义单元的embedding都学的那么完美呀对吧),所以作者这里提出了一个更加间接和隐晦的attention方式,如下
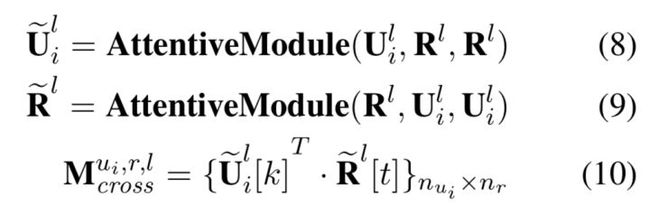
这里的AttentiveModule的3个参数依次为attention的Query、Key和Value,不熟悉的同学去复习Transformer,这里就不赘述啦。首先看公式8和9,这里先通过传统的attention来把utterance和response中的每个词用对面文本的词加权表示,得到新的utterance的word embeding sequence表示和新的response的word embedding sequence表示,之后再用一层传统的attention来计算出一个对齐矩阵来作为第二个对齐矩阵。
显然这种方式将utterance中的词和response中的词之间的依赖关系(dependency information)也作为词的表示加入了对齐矩阵的计算,所以说是建模了更加深(复)层(杂)的语义关系。不过,作者在论文5.2节有提到这两种attention方式匹配文本的操作其实是互补的,并且给出了一个case解释,然而小夕功力有限,努力理解了一下还是没理解
╮( ̄▽ ̄"")╭希望有看懂的小伙伴给小夕讲讲或者贴到评论区~
经过这么深层的匹配后,每个utterance中的每个词位都包含了2(L+1)维的匹配信息(L为Transformer encoder的层数,1为原始的word embedding,2为对齐矩阵的数量),作者这里又把utterances堆叠到一起,就形成了这个漂亮的3D粉色大立方体

所以这个大立方体的三个维度分别代表对话上下文中的每个utterance、utterance中的每个词(位)、response中的每个词(位)。
之后,再通过一个两层的3D的卷积神经网络来从这个大立方体中抽取特征,得到匹配层的特征,最后的最后通过一个单层感知机得到该candidate response的匹配概率。
说了这么多,来看看实验结果吧~

可以看到实验结果非常漂亮(当前的state-of-art),尤其是 这种比较有实际意义的指标(从10个candidates里召回top1)。而且DAM没有像DUA那样对utterance embedding sequence做深层encoding(这里直接用的3D conv抽特征了),但是实验结果明显比DUA好,可以说网络设计的很棒棒啦。
另外,作者这里也给出了去掉各个component后的性能情况:

比如对比DAM与倒数第二行可以看到,去掉那个复杂的深度注意力机制后,网络性能出现了明显的下降,说明论文中提出的这个“间接”的注意力机制确实能捕获到一些神奇的模式。
总结
最后小夕非常主观的总结一下这四个模型的亮点:
- Multi-view提出了将utterance建模为一个语义单元来建模多轮对话问题;
- SMN使用基于交互的匹配模型代替基于表示的匹配模型,并对文本进行多粒度表示;
- DUA对utterance embedding进行深度的encoding来建模utterances之间的依赖关系;
- DAM一方面对文本对进行多粒度表示并提出了一种深度attention的方法,另一方面抛弃了之前建模utterance embedding sequence的思路,提出了一种将word-level和utterance-level的信息整合到一起,构建一个多通道的3D Image(其实把utterance看成单帧的图像,那这个大方块更像是一个视频),进而通过3D Image分类器完成匹配的新思路。
参考文献
[1] Multi-view Response Selection for Human-Computer Conversation, EMNLP2016
[2] Sequential Matching Network- A New Architecture for Multi-turn Response Selection in Retrieval-Based Chatbots, ACL2017
[3] Modeling Multi-turn Conversation with Deep Utterance Aggregation, COLING2018
[4] Multi-Turn Response Selection for Chatbots with Deep Attention Matching Network, 2018ACL
[5] Text Matching as Image Recognition, AAAI2016
[6] Neural Network Models for Paraphrase Identification, Semantic Textual Similarity, Natural Language Inference, and Question Answering, COLING2018
[7] Enhanced LSTM for Natural Language Inference, ACL2017
[8] Shortcut-Stacked Sentence Encoders for Multi-Domain Inference, Proceedings of the 2nd Workshop on Evaluating Vector Space Representations for NLP. 2017
[9] Learning Deep Structured Semantic Models for Web Search using Clickthrough Data, CIKM2013
[10] Deep contextualized word representations, NAACL2018
[11] Attention Is All You Need, NIPS2017
填槽与多轮对话 | AI产品经理需要了解的AI技术概念
前言:本文作者@我偏笑,是我们“AI产品经理大本营”成员,也是“AI研习小分队”的分享嘉宾之一(每4周分享一篇AI产品经理相关的学习心得总结);欢迎更多有兴趣“主动输出”的朋友们一起加入、共同进步:)

序言
以一周前的这条微博作为开始——

一周前我讲:相对的,自然语言解析技术已经逐渐不再成为各家广义智能助理产品的核心竞争力,识别用户意图之后所提供的服务开始成为对话机器人差异化的核心。

对于一个对话系统而言,我微博中所指的『后续服务』,就是上图中的 DST(对话状态维护)以及 Policy(动作候选排序),或者统一的称其为 DM(Dialogue Mannagement,对话管理)。也即,当接收到 NLU 模块的输出、其他场景及用户特征信息之后,判断系统应该跳转到什么状态,以及执行什么样的动作。
产品角度,DM 是对话机器人封闭域多轮对话体验的核心,正是一次次 DST + Policy 形成了人机间的多轮对话体验。(注:我个人倾向于将“识别用户意图之后,为了获取必要信息,与用户进行的有目的的多轮对话”称为封闭域多轮对话,区别于识别用户意图之前,为了利用上文信息,所采用的『上下文替换』、『主体补全』等技术,也即开放域多轮对话。下文提到的『多轮对话』,均指封闭域多轮对话。)
既然多轮对话在对话机器人类产品体验中扮演着如此重要的角色,我便开始思考:一个架构完备的多轮对话体系应该是什么样的。也即,多轮对话系统中,至少需要包含哪些模块,才能为用户提供一种与人人对话相去不远的人机对话体验。
一、多轮对话
多轮对话定义
我有个习惯,就是在构造一个复杂系统之前,先从纷繁的细节之中跳出,尝试抽象的描述整个系统,及系统中的各个模块,也即为它们『下定义』。这能帮助你在多种可行方案中做出选择,也即帮你明确:什么该做,什么不该做,什么该谁做。
基于以上思想,我尝试先给出几个我个人对于多轮对话体系定义问题的回答——
基本定义:什么是多轮对话? (封闭域)多轮对话是一种,在人机对话中,初步明确用户意图之后,获取必要信息以最终得到明确用户指令的方式。多轮对话与一件事情的处理相对应。
补充说明1:所谓『必要信息』一定要通过与用户的对话获取吗? 不一定,即便是人与人之间的交流,对话本身所包含的信息也只占总传递信息量的小部分,更多信息来源于说话人的身份、当前的时间/地点等一系列场景信息。所以多轮对话的信息获取方式,也不应当只局限于用户所说的话。
补充说明2:多轮对话一定在形式上表现为与用户的多次对话交互吗? 不一定,如果用户的话语中已经提供了充足的信息,或者其它来源的补充信息已足够将用户的初步意图转化为一条明确的用户指令,那就不会存在与用户的多次对话交互。
以上,是针对多轮对话整体定义问题的回答,每个模块的相关定义会在下文尝试给出。
二、槽
1、槽(slot)
基本定义:什么是槽? 槽是多轮对话过程中将初步用户意图转化为明确用户指令所需要补全的信息。一个槽与一件事情的处理中所需要获取的一种信息相对应。
补充说明:多轮对话中的所有的槽位都需要被填充完整吗? 不一定,以如下对话为例——
我:『去萧山机场多少钱』
出租车司机:『70』
对话中的『70』,应当被理解为70元人民币,而不必再去追问:『你说的是人民币、美元、日元还是港币?』。这类信息应当以默认值的形式存在,也即槽有必填与非必填之分,与上文所说的『信息未必需要通过与用户的对话获取』相对应。
2、词槽与接口槽
上文反复的提到,对话内容并不是获取信息的唯一方式,用户身份以及当前场景也包含着大量值得被利用的隐含信息。所以,与此相对的,一个完备的多轮对话体系应当同时具备从用户话里以及话外获取信息的能力。
我个人将“利用用户话中关键词填写的槽”叫做词槽,“利用用户画像以及其他场景信息填写的槽”叫做接口槽。
举个例子,我讲『我明天要坐火车去上海』。其中,分别将『明天』、『上海』填入名为『出发时间』、『目的地』的词槽中,而我当前所在的位置,则填入到了名为『出发地』的接口槽中。
3、槽组与槽位
我个人将“利用用户话中关键词填写的槽”叫做词槽,“利用用户画像以及其他场景信息填写的槽”叫做接口槽。
举个例子,我讲『我后天要坐火车去上海』。其中,分别将『后天』、『上海』填入名为『出发时间』、『目的地』的词槽中,而我当前所在的位置,则填入到了名为『出发地』的接口槽中。
不知道上文错的如此离谱的结论,有没有引起你的注意:)
仔细读一遍上面举的例子,就会发现一个很严重的矛盾点:难道『出发地』这个槽不能由用户指定?用户完全可以说『我后天要坐火车从北京去上海』,那它是词槽还是接口槽?而且更进一步的,难道只能用『我当前所在的位置』来填入『出发地』这个槽中?比如,如果能读到我的日程表,发现我明天会去杭州,那是不是就应该用『杭州』而不是『我现在所在的位置』来填『出发地』这个槽了?
从中我们能发现什么呢?同一个槽,可能会存在多种填槽方式。
我将可能包含多种填槽方式的槽称为槽组,槽组下面可能存在任意多个槽位,也即任意多种填槽方式,而每个槽位又都对应着『词槽』与『接口槽』两种槽位类型之一。
本质上来讲,槽组(也即上文中提到的『槽』),对应着一种信息,而几乎不会有哪种信息的获取方式只有一种。所以一个『槽』会同时对应多种填槽方式也就是自然而然的了。
依照上文,同一种信息会有多种获取方式,也即同一个槽组会对应多种填槽方式(槽位)。那不同填槽方式之间必然会存在优先级的概念。
就如同上文『订票』的例子,『出发地』槽包含三种填写方式,一种词槽、两种接口槽,自然的,词槽的优先级最高,『日程表中隐含的出发地』次之,『我当前所在的位置』再次。
如果将其与前文提到过的必填/非必填结合起来,其填槽过程应当遵循以下步骤:
-
尝试填写词槽
-
若失败,尝试填写第一接口槽『用户日程表中隐含的出发地』
-
若失败,尝试填写第二接口槽『用户当前所在位置』
-
若失败,判断是否该槽必填
-
若必填,反问用户,重填词槽 *若非必填,则针对该槽组的填槽过程结束
我们需要知道,必填/非必填在逻辑上与槽组而不是槽位平级,只有信息才会分为必要/非必要,填槽方式不做这种区分。而且是否必填实际上与接口槽无关,只取决于是否需要与用户进行交互。
4、澄清话术
与槽组(也即与一种信息)平级的概念还有一个,叫做澄清话术。
澄清话术是对话机器人希望获取某种信息时所使用的问句。比如『目的地』对应的澄清话术就是『您想从哪出发呢?』,『出发时间』对应的澄清话术就是『您想什么时间出发呢?』。
显而易见的,澄清话术与槽组而不是槽位平级。
5、槽的填写
上文讲到,一个槽组可能会有多个槽位,槽位存在词槽与接口槽之分。
先说词槽。
词槽信息的抽取其实还是有些麻烦的,不过这属于解析的问题,不在本文探讨的范围内,这里只是简单提一下,举两个例子:
-
用户表达『不』,可能会有『不行』、『不是』、『算了』、『没有』等一系列说法。
-
用户话中有多个符合条件的关键词,我们整套多轮对话中有多个槽,每个槽填一个还是多个值?哪个槽与哪个词对应?
同义词典、规则、双向LSTM+CRF,各有各的方法。
再说接口槽。
接口槽与词槽相比,额外存在一个问题,就是:接口返回的结果就是用户需要的结果吗?
这里需要分成两种情况来讨论,一种是:我们明确知道接口的返回值可以直接填入槽位(不是槽/槽组)中,不需要向用户确认。
特别的,这里还要明确一点,即便是上述情况,也并不意味着当前槽/槽组只有该特定接口槽这一个槽位。有两种情况存在:一种是该槽组下只有这一个槽位,该接口的返回值直接填入槽位中,也相当于填入了槽/槽组中;或者该槽位下有多个槽位,接口槽的填入值并不一定最终作为槽/槽组的填入值。
另一种是:我们知道接口的返回值只能作为参考,需要用户的协助才能进行槽位的填写。
这种情况下,需要提供选项,让用户最终决定该槽位的填入值,与词槽一样,这里同样需要处理单值/多值的问题。单值/多值在逻辑上与槽组平级。
此外,这里还要注意一个否认选项的问题,比如我对阿里小蜜说,我忘记密码了,它会通过接口拿到我的当前账号,然后将其提供选项给我,问『你是忘记了哪个账号的密码?』,不过,除了我当前账号之外,还有一个选项也被提供出来了,就是『不,不是这个账号』。
这代表了一类问题的存在,用户的意图并不一定包含在接口的全部返回值之中。所以就必然会有这样一种类似『不要/不是/不』的选项,我将其叫做否认选项。
用户选择否认选项后,即意味着该槽位的填写失败了,需要填入一个特殊值代表失败。用户选择否认选项的失败,可以与接口调用失败等其它意外情况合并处理,因为这都意味着该槽位填写失败,意味着该种信息获取方式未能成功获取信息。
如果该槽组下只有这一个槽位,这个特殊的失败表征值就应当作为整个槽组的填入值,如果还有其他槽位值,则根据槽位间优先级最终确定槽组填入值。
6、平级槽和依赖槽
上面说到底都在讲一个槽组的填写,也即一种信息的获取,但多轮对话的目的是将初步用户意图转化为明确用户指令,这其中所需要的信息通常都不只有一种。
谈完了槽组与槽位之间的关系,接下来谈一下槽组与槽组之间的关系,也即信息与信息之间的关系。
为了便于理解,我先举两个例子来代表两种多轮对话中所包含的极端情况。
第一种:订车票,你需要知道用户出发的时间、地点、目的地、座位种类。这四个槽组之间,没有任何依赖关系。换言之,你只需要确定好这四个槽组中必填槽组之间的澄清顺序,接收到用户问句后,对还未填充完成的必填槽组依次进行澄清即可。我将这四个槽组之间的关系称为平级槽关系。
另一种,不知道读者玩没玩过橙光,或者其它多结局的剧情类游戏。它们的特点是什么呢?每一个选择都会有影响到后续剧情发展也即 每个槽组的填写结果会影响其它槽组的填写。换言之,部分槽组依赖前序槽组的填写结果,在其依赖的前序槽组填写完成之前,该槽组都无法进行填写。我将槽组间的这种关系称为依赖槽关系。
这种情况下,整个多轮对话过程就形成了一棵树,极端情况下,这棵树是满的。树上的每个节点放置着一个会对后续对话走向产生影响的槽组。
槽关系的选择要根据实际业务场景来确定。
如果错将平级槽采用依赖槽关系来管理,就会出现信息的丢失。比如 A、B、C,三者本为平级槽关系,但却将其用 A->B->C 的依赖槽关系来管理,那即便用户问句中包含填写 B、C 槽组的信息,也可能会由于 A 槽组的未填写而造成 B、C 槽组的填写失败。
如果错将依赖槽采用平级槽的关系来管理,就会出现信息的冗余,比如 A、B、C三者的关系为 A、A1->B、A2->C,那即便用户将值 A1 填入槽组 A 后,却仍然需要向用户询问本不需要的 C 槽组的填写信息。
上述两种情况属于全平级槽关系与全依赖槽关系的特殊情况,在实际的业务场景中,这两种关系会是同时存在的,不同槽组间,既有平级槽关系,又有依赖槽关系。
实际业务场景中,完整的多轮对话过程通常会以树的形式存在,每个节点存在一个或多个槽组,用于获取一种或多种信息,节点间的槽组为依赖关系,节点内的槽组为平级关系。
上文将多轮对话定义为一件事情的处理,槽组/槽定义为一种信息的获取,槽位定义为信息的一种获取方式。这里我倾向于将多轮对话树结构中的一个节点定义为处理事情的一个步骤。
一件事情的处理包含多个步骤,每个步骤中需要补全一种或多种信息,每种信息存在一种或多种获取方式。
上述定义和组里算法大佬的定义有些分歧,不过谁让这是我的文章呢:)就按我的来。
7、填槽意义
结合上文,我们需要了解到,填槽的意义有两个:作条件分支多轮对话、作信息补全用户意图。换言之,填槽不仅是补全用户意图的方式,而且前序槽位的填写还会起到指导后续信息补全走向的作用。

8、准入条件
上文我们讲到,完整的多轮对话过程通常会以树的形式存在,树中包含多个节点,代表处理这件事情的一个步骤。
而每个节点,都应当有其特别的准入条件。树的根节点往往需要限制 NLU 模块的输出,也即明确什么样的用户意图将会由该棵多轮对话树来处理;树的中间及叶子节点往往需要根据前序槽组的填槽结果以及其他背景信息进行条件限制。(如果将所有信息,比如 NLU 模块输出,或是其他背景信息都看做前序槽组的填写结果,那就能得到统一的槽组-条件-槽组-条件······形式,槽组用于获取信息,条件用于信息限制)
我尝试从两个角度来描述一套完备的准入条件体系。
一个是多条件的组织形式,准入条件在逻辑上应该支持条件间的与或非,百度的 UNIT 平台提供了一种相对成熟的组织形式,将准入条件整体划分为条件和条件组,条件包含在条件组中,组内条件间是且关系,条件组之间是或关系(当然这里的且与或可以根据自身业务情况对调),条件本身支持非关系。
一个是单条件的限制能力,准入条件应当同时支持对前序槽组填写值、填写方式、填写状态进行限制。也即需要有针对值的条件、针对类型的条件和针对状态的条件。简单的讲,状态就是『填了吗』,类型就是『谁填的』,值就是『填了什么』。
不同业务场景下我们会需要不同角度的限制条件。比如,上文中提到填槽的意义包含两种:作条件分支多轮对话、作信息补全用户意图,如果仅仅作信息,那我们通常就只关心『填了吗』,只要填写完成就进行后续步骤,并不关系『谁填的』以及『填了什么』;但是如果槽组内的填入值会影响后续多轮对话走向,那我们就倾向于通过槽组的填入方式或填入值来作多轮对话的分支。

三、答案系统、话题切换和状态切换
1)答案系统
先明确一个观点,多轮对话树的节点属于对话节点而不是答案节点,同一份答案可能会出现在多个对话节点中。
答案系统和多轮过程应当是解耦的,答案系统中的每份答案都应当设置好自己的触发条件。举个例子,若存在 ABC 三个槽,A=A1、B=B3、C=C1 提供答案一,A=A2、B=B1、C=C2 或 A=A3、B=B2、C=C1 提供答案二。
另外,答案的种类也不应仅局限于文本,富文本、接口、话题切换,都可以视为合理的答案形式。
2)话题切换
话题切换指用户与用户的对话从一个多轮过程切换至另一个多轮过程,话题切换有主动切换和被动切换之分。
上文提到的作为答案的话题切换,就可以理解为主动的话题切换。
被动的话题切换是指,系统发现无法从用户的问句中抽取信息以继续当前的多轮对话,只好将其作为一条全新的问句重新进行解析和话题识别。
话题切换,尤其是主动的话题切换会涉及到一个新问题:槽继承。举个例子——
我:『我明天要坐高铁从杭州到北京』
我:『算了,还是坐飞机吧』
这种情况下,机器人不应当重复询问『出发地』、『出发时间』和『目的地』。
除了槽继承,还有一个与之相对的问题叫做槽记忆,这通常适用在被动式的话题切换中。由于解析失误,或者其他原因,使得用户跳出了原话题,当用户在一定时间内重新回到原话题时,不应让用户重复进行填槽,该技术已被用于阿里小蜜,不过他们似乎称之为『多轮状态记忆』。
举个例子——
我:帮我订张从杭州到北京的机票。
VPA:请问您希望哪天出发呢?
我:明天杭州下雨吗?
VPA:明天杭州有雷阵雨。
我:后天呢?
VPA:后天杭州天气晴。
我:机票订后天的。
VPA:好的,已帮你预定后天从杭州到北京的机票。
3、状态切换
我们还需要思考这样一个问题,既然话题可以切换,也即一个多轮过程可以切换到另一个多轮过程,那多轮过程中的对话状态是否可以切换?
我举两个例子——
第一个:
我:帮我订张机票,从杭州出发。
VPA:请问你想去哪呢?
我:(发现明天杭州有雷阵雨)换出发地。
VPA:请问你想从哪出发呢?
我:上海。
多轮对话应当允许回到前序节点。
第二个:
我:我想买个杯子。
VPA:以下是为您推荐的杯子。(展示结果一)
我:换一换。
VPA:以下是为您推荐的杯子。(展示结果二)
多轮对话应当允许重复进入同一节点。
结语
就先这么多吧:)
注,饭团“AI产品经理大本营” ,是黄钊hanniman建立的、行业内第一个“AI产品经理成长交流社区”,通过每天干货分享、每月线下交流、每季职位内推等方式,帮助大家完成“AI产品经理成长的实操路径”。
---------------------
作者:黄钊hanniman,图灵机器人-人才战略官,前腾讯产品经理,5年AI实战经验,8年互联网背景,微信公众号/知乎/在行ID“hanniman”,饭团“AI产品经理大本营”,分享人工智能相关原创干货,200页PPT《人工智能产品经理的新起点》被业内广泛好评,下载量1万+。