AlwaysOn是一种集合了高可用和灾难恢复两种功能的技术,它支持一个或多个数据库整体的发生故障转移,它实现了一定程度上的负载均衡,减轻了主服务器的压力,是目前最好的一种选择。那么当极端情况发生时,集群大多数节点都挂掉了,数据库所在的主节点Server也挂掉了。即当Windows 集群 Fail 时,如何快速从尚且存活的少数节点中,挑选一个来承接数据库服务。
1:测试目的
Windows Failover Cluster若因故障server节点太多, 会使整个Cluster fail, 此时其他残存server节点上的DB数据库都会变成Recovery Pending状态, 无法使用。下面的测试就是顽强还活着的节点中,挑一个使数据库快速恢复可用状态。
2:测试环境
| Node1 | Node1 | Node1 | ClusterIP | ListenerIP |
| 172.XXX.XXX.112 | 172.XXX.XXX.113 | 172.XXX.XXX.114 | 172.XXX.XXX.115 | 172.XXX.XXX.117 |
| ALWAYSONTEST01 | ALWAYSONTEST02 |
ALWAYSONTEST03 | ||
| Primary;Synchronous Commit | Secondary;Synchronous Commit |
Secondary;Asynchronous Commit |
登录 此时的主节点,查看如下:
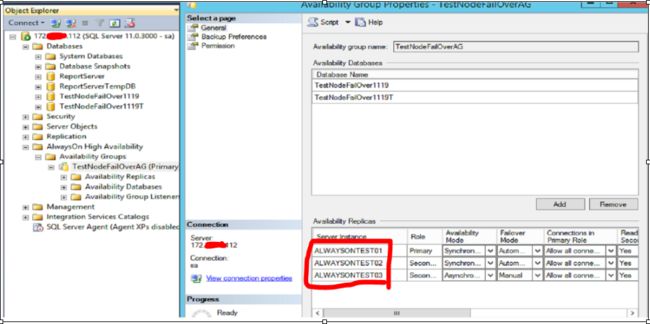
各节点运行正常。
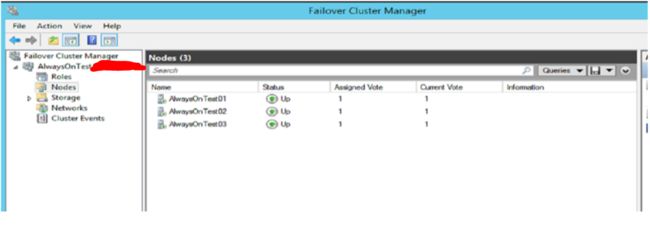
3:测试步骤
Step 1:关闭2个节点(XXX.112;XXX.113)使 Windows Cluster Fail,Ping Cluster IP 显示超时。
----剩余172.XXX.XXX.114 保留非同步的副本。

Step 2:登入唯一的存活的节点172.XXX XXX.114,SQL 显示错误如下:
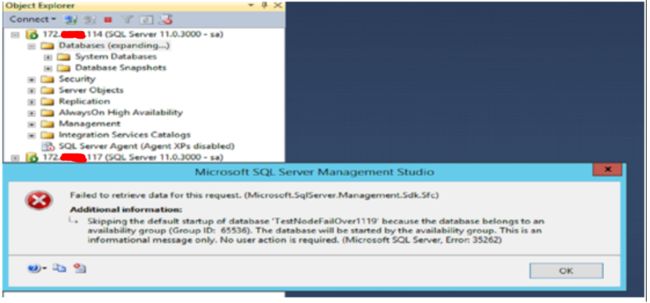
Step 3:刷新DB,查询可用性组和DB的状态已分别处于Resolving 和Recovery Pending,数据库不可用。
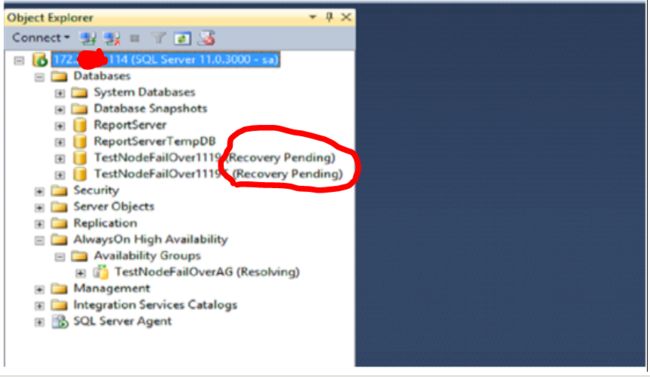
此时Listener IP 也不可用
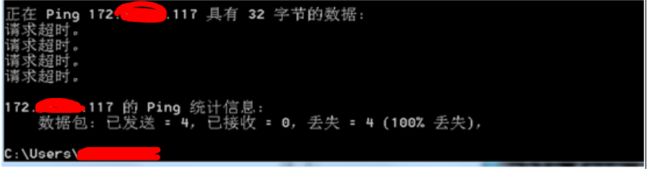
Step 4: 查看对应的Cluster 服务对应的Service Name
(Server ManageràLocal ServeràServices)
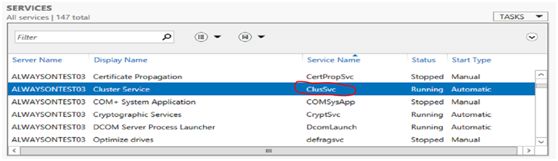
或(Server ManageràToolsàComponent ServicesàServices)
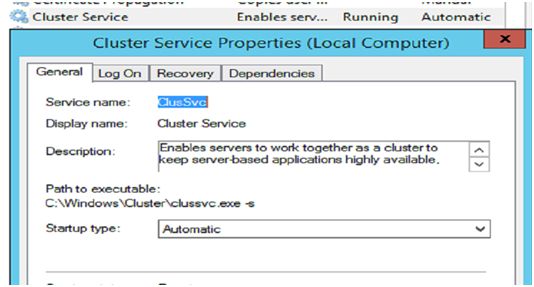
Step5:手动停止群集服务
---- net.exe stop Cluster_Name(实为Service name)
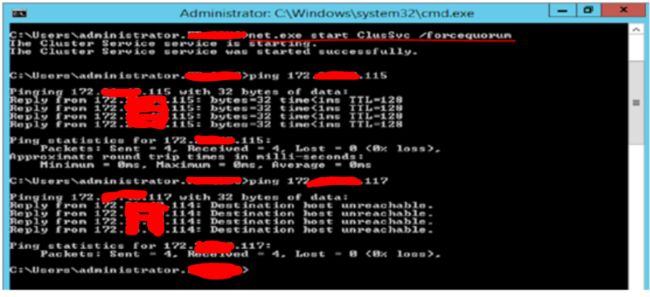
成功关闭后172.XXX.XXX.115无法Ping 通
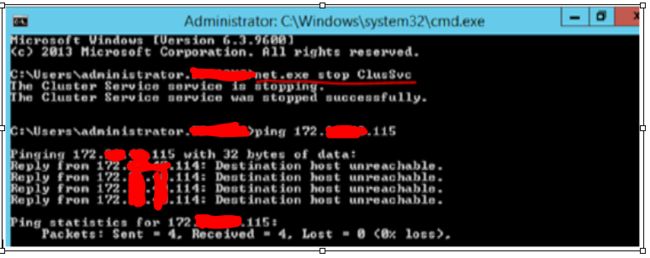
Step6:在单一节点上使用强制仲裁,藉以启动WSFC群集
---- net.exestart Cluster_Name/forcequorum
成功启动后Cluster IP 可以Ping 通;Listener IP 无法Ping 通
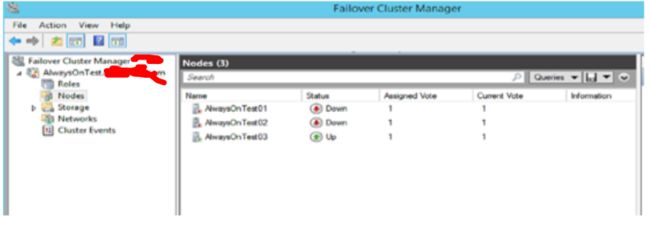
通过FailOver Cluster Manger 查看节点和AG的状态如下:
下图为各节点状态;
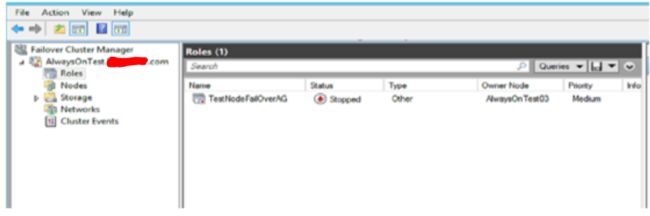
下图为高可用性组的状态
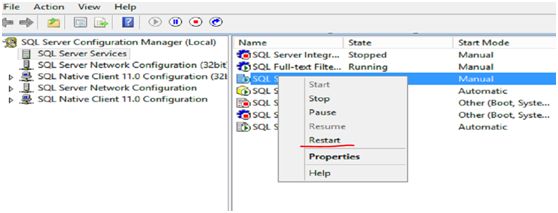
Step 7:重启SQL Serveice 服务
----(个别情况下:首先,Disable后restart,然后再Enable后restart)
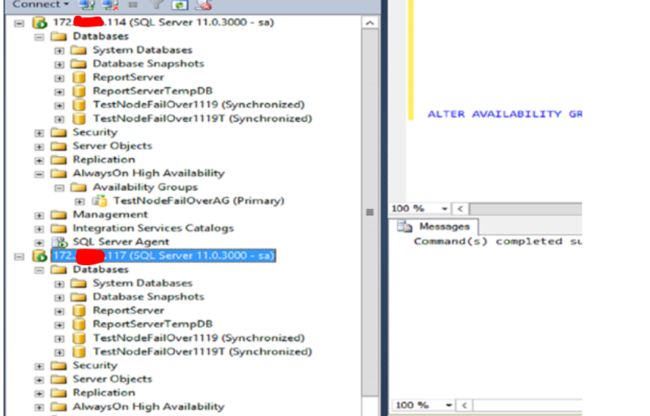
Step 8:执行可用性群组的强制性手动容错转移
---- ALTER AVAILABILITY GROUP group_name FORCE_FAILOVER_ALLOW_DATA_LOSS (其中 group_name 是可用性组的名称)

Step 9:可用性组的状态变为Primary状态,DB显示同步,listener IP也为可用
步骤概况总结:
Windows Failover Cluster若因故障server太多, 会使整个cluster fail, 此时在其他残存server的DB, 会在Recovery Pending状态, 无法使用, 采用以下可使DB恢复使用.
停止群集服务 --> 强制仲裁以启动WSFC群集 --> 重启SQL Serveice服务 --> 执行可用性群组的强制性手动容错转移.
4:补充说明
此时Restart测试过程中关闭的节点(XXX.112;XXX.113),部署其上的DB显示Not Synchronizing。

本文版权归作者所有,未经作者同意不得转载,谢谢配合!!!