1.I/O API工具


2.读取csv或文本文件中的数据
1)创建一个.csv文件
White,red,blue,green,animal
1,5,2,3,cat
2,7,8,5,dog
3,3,6,7,horse
2,2,8,3,duck
4,4,2,1,mouse

2)用read_csv()函数读取他的内容,同时将其转化为DataFrame对象
>>> csvframe=pd.read_csv('/Users/caojin/Desktop/myCSV_01.csv')
>>> csvframe
White red blue green animal
0 1 5 2 3 cat
1 2 7 8 5 dog
2 3 3 6 7 horse
3 2 2 8 3 duck
4 4 4 2 1 mouse
3)既然csv也是文本文件,还可以使用read_table()函数但是得指定分隔符
>>> csvframe=pd.read_table('/Users/caojin/Desktop/myCSV_01.csv',sep=',')
>>> csvframe
White red blue green animal
0 1 5 2 3 cat
1 2 7 8 5 dog
2 3 3 6 7 horse
3 2 2 8 3 duck
4 4 4 2 1 mouse
4)上面例子,标识各列的表头位于csv文件的第一行,但一般情况并非如此,可能第一行就是列表数据如下:
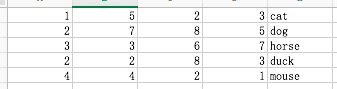

5)没有表头的数据使用read_csv()函数时候,使用header选项,将其设置为None,pandas会自动为其添加默认表头
未使用header
>>> csvframe=pd.read_csv('/Users/caojin/Desktop/myCSV_02.csv')
>>> csvframe
1 5 2 3 cat
0 2 7 8 5 dog
1 3 3 6 7 horse
2 2 2 8 3 duck
3 4 4 2 1 mouse
使用header
>>> csvframe=pd.read_csv('/Users/caojin/Desktop/myCSV_02.csv',header=None)
>>> csvframe
0 1 2 3 4
0 1 5 2 3 cat
1 2 7 8 5 dog
2 3 3 6 7 horse
3 2 2 8 3 duck
4 4 4 2 1 mouse
6)或者可以使用read_csv()函数的时候,使用names指定表头,直接把存有各列名称的数组赋给它即可
>>> csvframe=pd.read_csv('/Users/caojin/Desktop/myCSV_02.csv',names=['a','b','v','d','w'])
>>> csvframe
a b v d w
0 1 5 2 3 cat
1 2 7 8 5 dog
2 3 3 6 7 horse
3 2 2 8 3 duck
4 4 4 2 1 mouse
7)读取csv创建一个具有等级结构的DataFrame,可以read_csv()指定index_col选项,把想要转换为索引的列名称赋给index_col
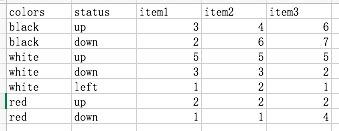

>>> csvframe=pd.read_csv('/Users/caojin/Desktop/myCSV_03.csv',index_col=['colors','status'])
>>> csvframe
item1 item2 item3
colors status
black up 3 4 6
down 2 6 7
white up 5 5 5
down 3 3 2
left 1 2 1
red up 2 2 2
down 1 1 4
3.用RegExp(正则表达式)解析txt文件
1)不是以逗号或者分号分割的需要用read_table()函数,并指sep选项为一个正则表达式

2)以下txt元素都以一个或者多个制表符或者空格相隔

>>> import pandas as pd
>>> txtframe=pd.read_table('/Users/caojin/Desktop/ch05_04.txt',sep='\s*')
>>> txtframe
White red blue green
0 1 5 2 3
1 2 7 8 5
2 3 3 6 7
3)以下txt文件中数字和字母杂糅,需要从中抽取数字部分,无表头需要用header设置成None


>>> txtframe=pd.read_table('/Users/caojin/Desktop/ch05_05.txt',sep='\D*',header=None)
>>> txtframe
0 1 2
0 0 123 122
1 1 124 321
2 2 125 333
4)使用skiprows可以排除多余的行
如果排除前5行
如果只排除第5行


>>> txtframe=pd.read_table('/Users/caojin/Desktop/ch05_06.txt',sep=',',skiprows=[0,1,3,6])
>>> txtframe
White red blue green animal
0 1 5 4 cat NaN
1 2 7 8 5 dog
2 3 3 6 7 horse
3 2 2 8 3 duck
4 4 4 2 1 mouse
4.从txt文件中读取部分数据
只想读取文件一部分,可明确指定要解析的行号这时要用到nrows和skiprows选项,可以指定起始行n(n=skiprows)和从起始行往后读多少行(nrows=i)
>>> csvframe=pd.read_csv('/Users/caojin/Desktop/myCSV_02.csv',skiprows=[2],nrows=3,header=None)
>>> csvframe
0 1 2 3 4
0 1 5 2 3 cat
1 2 7 8 5 dog
2 2 2 8 3 duck
5.切分想要的文本,遍历各个部分逐一对其执行某一特定操作
对于一列数字,每隔两行取一个累加起来,最后把和插入倒Series对象中(暂时略过)
6.往csv文件写入数据
1)携带索引和列名的写入
>>> import numpy as np
>>> import pandas as pd
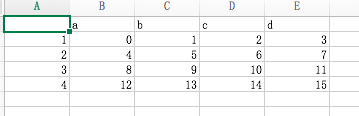
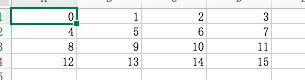
>>> frame=pd.DataFrame(np.arange(16).reshape(4,4),index=[1,2,3,4],columns=['a','b','c','d'])
>>> frame
a b c d
1 0 1 2 3
2 4 5 6 7
3 8 9 10 11
4 12 13 14 15
>>> frame.to_csv('/Users/caojin/Desktop/ch05_07.csv')

2)取消携带索引和列名
>>> frame.to_csv('/Users/caojin/Desktop/ch05_08.csv',index=False,header=False)

3)数据结构中的NaN写入csv文件后显示为空
4)使用to_csv()函数中的na_rep选项把空字段替换为你需要的值
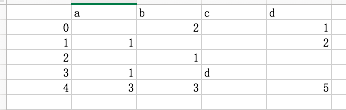

>>> frame=pd.read_csv('/Users/caojin/Desktop/ch05_09.csv')
>>> frame
Unnamed: 0 a b c d
0 0 NaN 2.0 NaN 1.0
1 1 1.0 NaN NaN 2.0
2 2 NaN 1.0 NaN NaN
3 3 1.0 NaN d NaN
4 4 3.0 3.0 NaN 5.0
>>> frame.to_csv('/Users/caojin/Desktop/ch05_10.csv',na_rep='h')


7.安装html5lib模块
8.写入数据到HTML文件
>>> frame=pd.DataFrame(ny.arange(16).reshape(4,4))
>>> frame
0 1 2 3
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
3 12 13 14 15
>>> print(frame.to_html())
0
1
2
3
0
0
1
2
3
1
4
5
6
7
2
8
9
10
11
3
12
13
14
15
9.从HTML文件读取数据
1)先写入DataFrame到一个网页
>>> import html5lib
>>> import numpy as np
>>> import pandas as pd
>>> frame=pd.DataFrame(np.random.random((4,4)),index=['white','black','red','blue'],columns=['up','down','right','left'])
>>> frame
up down right left
white 0.003468 0.319286 0.713373 0.169162
black 0.228553 0.289013 0.263125 0.817748
red 0.032618 0.286309 0.099676 0.765746
blue 0.824121 0.820978 0.858056 0.468772
>>> s=['']
>>> s.append('MY DATAFRAME')
>>> s.append('')
>>> s.append(frame.to_html())
>>> s.append('')
>>> html=''.join(s)
>>> html_file=open('/Users/caojin/Desktop/myFrame.html','w')
>>> html_file.write(html)
835
>>> html_file.close()
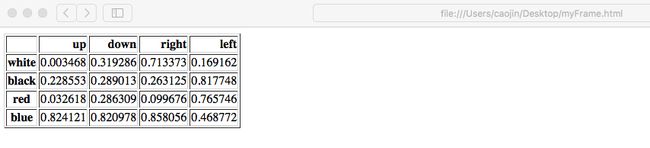
·2)从这个网页读取数据
>>> import lxml
>>> import numpy as np
>>> import pandas as pd
>>> web_frames=pd.read_html('file:///Users/caojin/Desktop/myFrame.html')
>>> web_frames
[ Unnamed: 0 up down right left
0 white 0.003468 0.319286 0.713373 0.169162
1 black 0.228553 0.289013 0.263125 0.817748
2 red 0.032618 0.286309 0.099676 0.765746
3 blue 0.824121 0.820978 0.858056 0.468772]
10.从XML读取数据(暂时略过)
11.读写excel文件
1)读出excel文件
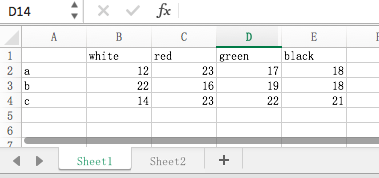

>>> pd.read_excel('/Users/caojin/Desktop/data.xls')
white red green black
a 12 23 17 18
b 22 16 19 18
c 14 23 22 21
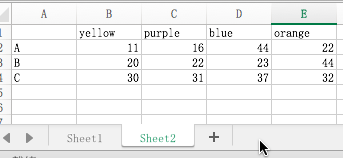
>>> pd.read_excel('/Users/caojin/Desktop/data.xls','Sheet2')
yellow purple blue orange
A 11 16 44 22
B 20 22 23 44
C 30 31 37 32
>>> pd.read_excel('/Users/caojin/Desktop/data.xls','Sheet1')
white red green black
a 12 23 17 18
b 22 16 19 18
c 14 23 22 21
>>> pd.read_excel('/Users/caojin/Desktop/data.xls',1)
yellow purple blue orange
A 11 16 44 22
B 20 22 23 44
C 30 31 37 32
>>> pd.read_excel('/Users/caojin/Desktop/data.xls',0)
white red green black
a 12 23 17 18
b 22 16 19 18
c 14 23 22 21
2)将dataframe对象写入xlsx文件中
>>> import numpy as np
>>> import pandas as pd
>>> import xlrd as xd
>>> import openpyxl as oxl
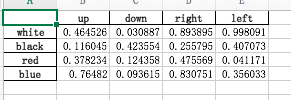
>>> frame=pd.DataFrame(np.random.random((4,4)),index=['white','black','red','blue'],columns=['up','down','right','left'])
>>> frame
up down right left
white 0.464526 0.030887 0.893895 0.998091
black 0.116045 0.423554 0.255795 0.407073
red 0.378234 0.124358 0.475569 0.041171
blue 0.764820 0.093615 0.830751 0.356033
>>> frame.to_excel('/Users/caojin/Desktop/data2.xlsx')
12.读写json文件
1)将DataFrame转化位json
>>> frame
up down right left
white 0.464526 0.030887 0.893895 0.998091
black 0.116045 0.423554 0.255795 0.407073
red 0.378234 0.124358 0.475569 0.041171
blue 0.764820 0.093615 0.830751 0.356033
>>> frame.to_json('/Users/caojin/Desktop/frame.json')

2)读取json
>>> pd.read_json('/Users/caojin/Desktop/frame.json')
down left right up
black 0.423554 0.407073 0.255795 0.116045
blue 0.093615 0.356033 0.830751 0.764820
red 0.124358 0.041171 0.475569 0.378234
white 0.030887 0.998091 0.893895 0.464526
3)复杂的json文件
编写复杂的json文件
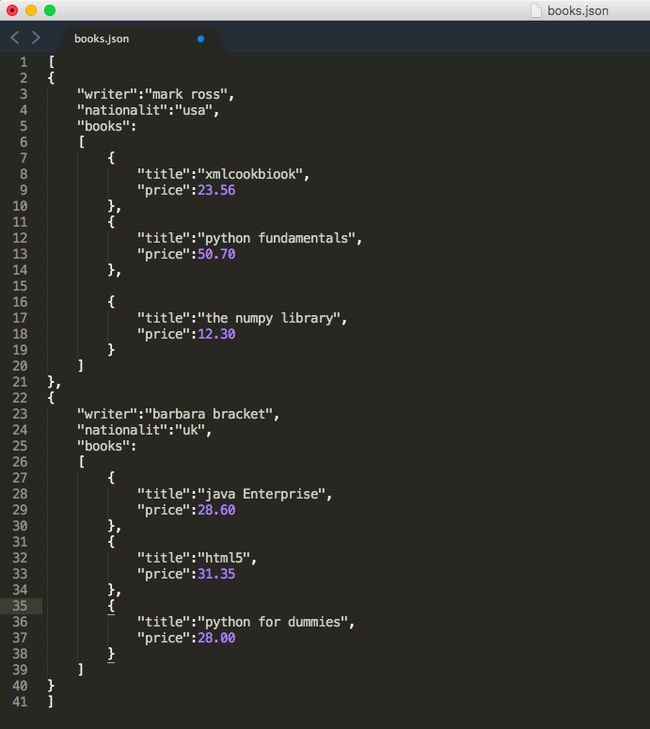

以上结构不再是列表形式,而是一种更为复杂的形式,因此无法在使用read_json()来处理,所以首先要对负责的json进行格式化规范化
>>> import numpy as np
>>> import pandas as pd
>>> import json #由于后面要用到json.loads()函数将json文件转化成python结果,所以要引入json包
>>> from pandas.io.json import json_normalize #由于后面要将json的数据进行规范化所以要引入,规范化后就产出一个dataframe格式的对象
>>> file=open('/Users/caojin/Desktop/books.json','r') #以只读的形式打开已经存号的json文件
>>> text=file.read() #读出json内容赋值给text
>>> print(text)
[
{
"writer":"mark ross",
"nationalit":"usa",
"books":
[
{
"title":"xmlcookbiook",
"price":23.56
},
{
"title":"python fundamentals",
"price":50.70
},
{
"title":"the numpy library",
"price":12.30
}
]
},
{
"writer":"barbara bracket",
"nationalit":"uk",
"books":
[
{
"title":"java Enterprise",
"price":28.60
},
{
"title":"html5",
"price":31.35
},
{
"title":"python for dummies",
"price":28.00
}
]
}
]
>>> text2=json.loads(text)#利用loads函数对读出的text内容进行转换成python格式
>>> print(text2)
[{'nationalit': 'usa', 'books': [{'title': 'xmlcookbiook', 'price': 23.56}, {'title': 'python fundamentals', 'price': 50.7}, {'title': 'the numpy library', 'price': 12.3}], 'writer': 'mark ross'}, {'nationalit': 'uk', 'books': [{'title': 'java Enterprise', 'price': 28.6}, {'title': 'html5', 'price': 31.35}, {'title': 'python for dummies', 'price': 28.0}], 'writer': 'barbara bracket'}]
>>> text3=json_normalize(text2,'books')#利用json_normalize函数对text2的内容按照books键进行产出
>>> text3
price title
0 23.56 xmlcookbiook
1 50.70 python fundamentals
2 12.30 the numpy library
3 28.60 java Enterprise
4 31.35 html5
5 28.00 python for dummies
然而可以将其余同books统一级别的其他键的作为第三个数组参数传入
>>> text4=json_normalize(text2,'books',['writer','nationalit'])
>>> text4
price title nationalit writer
0 23.56 xmlcookbiook usa mark ross
1 50.70 python fundamentals usa mark ross
2 12.30 the numpy library usa mark ross
3 28.60 java Enterprise uk barbara bracket
4 31.35 html5 uk barbara bracket
5 28.00 python for dummies uk barbara bracket
13.HDF5格式
如果想要分析大量数据,最好使用二进制格式
python有很多二进制数据处理工具,HDF5库比较优秀,这种文件的数据结构由节点组成,能够存储大量数据集
>>> import numpy as np
>>> import pandas as pd
>>> import tables as tb #后续要使用HDFS函数必须用这个模块
>>> from pandas.io.pytables import HDFStore
>>> frame=pd.DataFrame(np.arange(16).reshape(4,4),index=['white','black','red','blue'],columns=['up','down','right','left'])
>>> frame
up down right left
white 0 1 2 3
black 4 5 6 7
red 8 9 10 11
blue 12 13 14 15
>>> store=HDFStore('/Users/caojin/Desktop/mydata.h5')#创建一个h5格式文件
>>> store['obj1']=frame#将dataframe对象放入倒h5中
>>> store['obj1']
up down right left
white 0 1 2 3
black 4 5 6 7
red 8 9 10 11
blue 12 13 14 15
14.pickle--python对象序列化
15.用cPickle实现Python对象序列化
序列化=将对象的层级结构转换位字节流的过程

16.用pandas实现对象序列化
>>> import pandas as pd
>>> import numpy as np
>>> frame=pd.DataFrame(np.arange(16).reshape(4,4),index=['white','black','red','blue'],columns=['up','down','right','left'])
>>> frame
up down right left
white 0 1 2 3
black 4 5 6 7
red 8 9 10 11
blue 12 13 14 15
>>> frame.to_pickle('/Users/caojin/Desktop/frame.pkl')

>>> pd.read_pickle('/Users/caojin/Desktop/frame.pkl')#反序列化
up down right left
white 0 1 2 3
black 4 5 6 7
red 8 9 10 11
blue 12 13 14 15
17.对接数据库--mysql数据库连接(这个之后找时间专门写一天笔记)
1)python直接链接数据库(这个之后找时间专门写一天的笔记)
2)Python借助pandas链接数据库
import pandas as pd
import MySQLdb
conn=MySQLdb.connect(host="localhot",user="root",passwd="*****",db="test",charset="utf8")
sql = "select * from user limit 3"
df = pd.read_sql(sql,conn,index_col="id")
print df
cur = conn.cursor()
cur.execute("drop table if exists user")
cur.execute('create table user(id int,name varchar(20))' )
pd.io.sql.write_frame(df,"user",conn)
18.SQLite3数据读写(暂时略过)
19.PostgreSQL数据读写(展示略过)
20.NoSQL数据库MongDB数据读写(展示略过)