姓名:苗春雨 学号:16019110036
转载自:http://geek.csdn.net/news/detail/245625
【嵌牛导读】:本文是强化学习名作——“Reinforcement Learning: an Introduction”一书中最为重要的内容,旨在介绍学习强化学习最基础的概念及其原理,让读者能够尽快的实现最新模型。毕竟,对任何机器学习实践者来说,RL(强化学习,即Reinforcement Learning)都是一种十分有用的工具,特别是在AlphaGo的盛名之下。
【嵌牛鼻子】:人工智能
【嵌牛提问】:关于人工智能的强化学习方法?
【嵌牛正文】:第一部分,我们将具体了解了MDPs (马尔可夫决策过程)以及强化学习框架的主要组成部分;第二部分,我们将构建并学习有关价值函数和Bellman (贝尔曼方程)的理论知识,它是强化学习中最重要公式,我们将一步一步地推导、解释,以揭开强化学习的神秘面纱。
当然,本文只是尽力用最快、最直观的方式带你来理解强化学习背后的理论,而要加深自己在该话题上的理解,Sutton和Barto所写的“Reinforcement Learning:An Introduction”肯定值得你用心读一读。此外,AlphaGo身后的大神David Silver在YouTube上所讲强化学习十课也值得你认真学一学。
监督学习 vs. 评估学习
对于很多感兴趣的问题,监督学习的范例没有办法给我们提供所需要的灵活性。监督学习和强化学习这两者之间最主要的区别在于收到的反馈是评估性的还是指导性的。指导性的反馈告诉你如何达到目标,而评估性的反馈则告诉你将会把目标完成到什么程度。监督学习以指导性的反馈为基础来解决问题,而强化学习则是基于评估性反馈来解决问题的。图像分类就是用带有指导性反馈的监督学习解决问题的一个实际例子;当算法尝试分类一些特定的数据时,它将从指导性的反馈中了解到哪个才是真正的类别。而另一方面,评估性的反馈仅仅告诉你完成目标的程度。如果你用评估性反馈来训练一个分类器,你的分类器可能会说“我认为这是一个仓鼠”,然后它会得到50分。但是,由于没有任何语境信息,我们不知道这 50 分是什么。我们需要进行其他的分类,探索50分意味着我们是准确或是不准确。或许10000分是一个更好的分值,因此我们还是不知道它是什么,除非我们尝试去对其他数据再进行分类。

猜到是仓鼠就可以得到两个金色星星和一个笑脸,而猜沙鼠能得到一个银色星星和一个大拇指
在我们感兴趣的很多问题中,评估性反馈的想法是更直观的,更易实现的。例如,想象一个控制着数据中心温度的系统。指导性反馈在这里似乎没有任何用处,你怎样告诉你的算法在任意给定的时间步中每个零件正确的设置是什么?评估性反馈在这里就将发挥它的用处了。你能很容易的知道在一个特定的时间段用了多少电,或者平均温度是多少,甚至有多少机器温度过高了等数据。这实际上就是谷歌使用强化学习解决这些问题的方式。让我们直接来学习吧。
马尔科夫决策过程
假定我们知道状态 s,如果未来的状态条件独立于过去的状态,那么状态 s 就具有马尔科夫性质。这意味着s描述了所有过去的状态直到现在的状态。如果这很难理解,那我们就用一个例子来解释,让这个问题显得更简单一点。假设一个球飞过空中,如果它的状态是由它的位置和速度决定,并足以描述它当前的位置和接下来的位置(不考虑物理模型和外界影响)。因此,这一状态就具备马尔科夫性质。但是,如果我们只知道这个球的位置不知道它的速度,它的状态就不再是马尔科夫。因为现在的状态并不是所有以前状态的归纳,我们需要以前的时间点所得到的信息去构建合适的球的模型。
强化学习通常可以建模为一个马尔科夫决策过程,即MDP(Markov Decision Process)。MDP是一个有向图,它有节点和边的状态,可以描述马尔科夫状态之间的转变,下面是一个简单的例子:
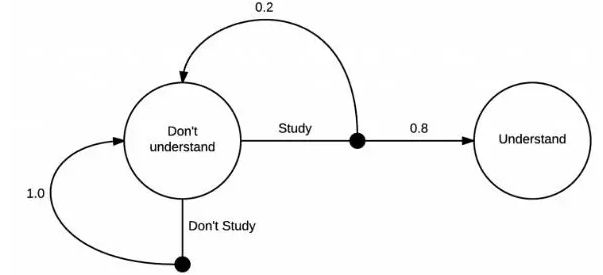
一个简单的马尔科夫决策过程
这个MDP展示了学习马尔科夫决策的过程。在最开始你在一个“不理解”的状态中,接下来,你有两个可能的动作,学习或者不学习。如果你选择不学习,则有100%的可能性返回到不理解的状态里。但是,如果你选择学习,只有20%的可能性让你回到最开始的地方,即80%的可能性变成理解的状态。
实际上,我确定转换到理解状态的可能性超过80%,MDP的核心其实很简单,在一个状态你可以采取一系列的动作,在你采取行动之后,这里有一些你能转化去什么状态的分布。在采取不学习动作的例子中,这个转化也能被很好的确定。
强化学习的目标是去学习怎么花更多的时间在更有价值的状态上,为了有一个更有价值的状态,我们需要MDP提供更多的信息。
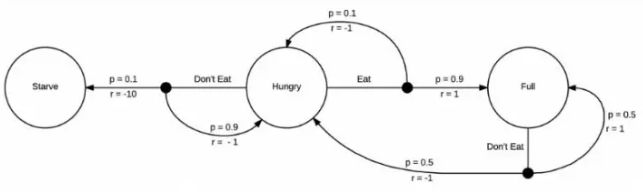
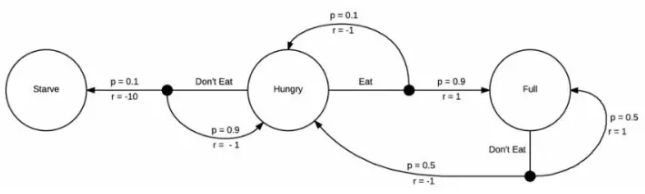
你不需要一个MDP来告诉自己饿了要吃饭,但是强化学习的机制是需要它的
这个MDP增加了奖励机制,你每转化到一个状态,就会获得一次奖励。在这个例子中,由于接下来状态是饥饿,你会得到一个负面的奖励,如果接下来状态是饿死,那会得到一个更负面的奖励。如果你吃饱了,就会获得一个正面的奖励。现在我们的MDP已经完全成型,我们可以开始思考如何采取行动去获取能获得的最高奖励。
由于这个MDP是十分简单的,我们很容易发现待在一个更高奖励的区域的方式,即当我们饥饿的时候就吃。在这个模型中,当我们处于吃饱状态的时候没有太多其它的选择,但是我们将会不可避免的再次饥饿,然后立马选择进食。强化学习感兴趣的问题其实具有更大更复杂的马尔科夫决策过程,并且在我们开始实际探索前,我们通常不知道这些策略。
形式化强化学习问题
现在我们有了很多我们需要的基础材料,接下来我们需要将目光转向强化学习的术语。最重要的组成是智能体(agent)和环境(environment)。智能体是被间接控制的,且存在于环境中。回顾我们的马尔科夫决策模型,智能体可以在给定的状态下选择一个对它有显著影响的动作。然而,智能体并不能完全的控制环境的动态,环境会接收这些动作,然后返回新的状态和奖励
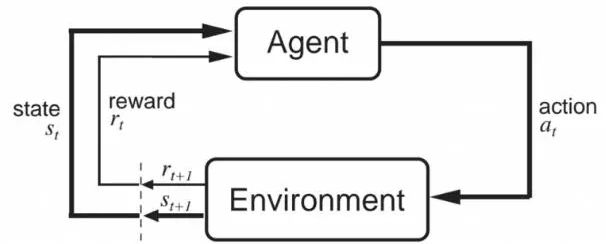
来自Sutton和Barto的书“Reinforcement Learning: an Introduction”(这是强烈推荐的)的这张图,很好的解释了智能体和环境之间的相互作用。在某个时间步t,智能体处于状态s_t,采取动作a_t。然后环境会返回一个新的状态s_t+1和一个奖励r_t+1。奖励处于t+1时间步是因为它是由环境在t+1的状态s_t+1返回的,因此让它们两个保持一致更加合理(如上图所示)。
我们现在已经有一个强化学习问题的框架,接下来准备学习如何最大化奖励函数。在下一部分中,我们将进一步学习状态价值(state value)函数和动作价值(action value)函数,以及奠定了强化学习算法基础的贝尔曼(Bellman)方程,并进一步探索一些简单而有效的动态规划解决方案。
奖励与回报
正如前面所说的,强化学习中的智能体学习如何最大化未来的累积奖励。这个用来描述未来的累积奖励的词称为回报,通常用R表示。我们还使用下标t来表示在某个时间步骤下的返回值。数学公式的表示如下:
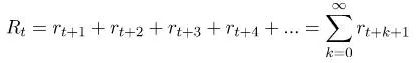
如果我们让这个级数无限延伸,那么我们可能会得到无穷的回报,但这样的话使得这个问题的定义失去意义。因此,只有当我们期望得到的奖励是有限级的,这个等式才有意义。有终止程序的任务称为情景任务。纸牌游戏是情景性问题的好例子。情景的开始是向每个人发牌,并且不可避免地根据特定的游戏规则而结束。然后,下一轮另一个情景又开始,再次处理这些纸牌。
比起使用未来的累积奖励,更为常用地是使用未来累积折扣奖励:
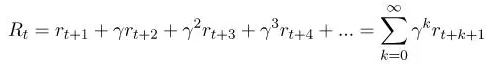
在这里0<γ<1。以这种方式来定义回报值有两个好处:不仅能够以无限级数来定义回报值,而且还能为随后的回报赋予更好的权重,这意味着我们更关心即将到来的回报,而不是我们将来会得到的回报。γ的值越小,就越正确。在特殊情况下,我们令γ等于0或者1。当γ等于1时,我们就回到了第一个等式,我们关心的是所有的回报,而不是考虑到未来有多远。另一方面,当γ等于0时,我们关心的是当前的回报,而不考虑之后的任何回报。这将导致我们的算法缺乏长远性。它将学会采取最适合当前情况的行动,但不会考虑此行动对未来的影响。
策略
策略,被记为Π(s,a),描述了行动的一个方式。它是一个这样的函数:接受一个状态和一个动作,并返回在该状态下采取这个动作的概率。因此,对于一个给定的状态,它必须满足 。在下面的例子中,当我们饿时,我们可以在吃和不吃两个动作之间做出选择。
我们的策略应该描述如何在每个状态下采取行动。因此,一个等概率的随机策略就该像这样子: 其中E代表吃的行动, 代表不吃的行动。这意味着,如果你处于饥饿状态,你在选择吃或者不吃的概率是相同的。
我们使用强化学习的目标是为了去学习一个最优的策略Π*,它告诉我们如何行动以得到最大化的回报。这只是一个简单的例子,容易知道例子中的最优决策是饿了就吃 。在这个实例中,正如许多MDPs (马尔可夫决策过程)一样,最优的决策是确定性的。每一个最佳状态都有一个最佳行动。有时这被写成
Π*(s)=a,这是一个从状态到这些状态下最优决策行动的一个映射。
价值函数
我们利用价值函数来得到学习的最优策略。强化学习中有两种类型的价值函数:状态价值函数,表示为V(s);和行为价值函数,表示为Q(s,a)。
状态价值函数描述了在执行一个策略时的状态值。这是一个从状态s开始执行我们的策略Π所得到的预期回报:
值得注意的是,即使在相同的环境下,价值函数也会根据策略而改变。这是因为状态的价值函数取决于你的行为方式,因为你在某一个特定的状态下的行为会影响你预期的回报。同样要注意的是期望的重要性。(期望就像一个平均值,就是你期望看到的回报)。我们使用期望的原因在于:当你到达一个状态时,会发生一些随机状况。你可能有一个随机策略,这意味着我们需要将我们所采取的所有不同行动的结果结合起来。同样地,过渡函数可以是随机的,也就是说,我们不能以100%的概率结束任何状态。记住上面的这个例子:当你选择一个行动时,环境将返回下一个状态。可能有多个状态可以返回,甚至是一个动作。更多的信息我们将会在Bellman方程(贝尔曼方程)中得到。期望将所有的随机性都考虑在内。
我们将使用另一个价值函数是动作价值函数。动作价值函数是指我们采取某一特定策略时,在某个状态下采取一个动作所产生的价值。这是在策略Π下,对给定状态和行动时所返回的预期回报:
对状态价值函数的注释同样适用于动作价值函数。它将考虑到未来行动的随机性,以及从环境中返回状态的随机性。
贝尔曼方程
Richard Bellman是一位美国应用数学家,他推导了以下方程,让我们能够开始求解这些MDPs (马尔可夫决策过程)。在强化学习中,贝尔曼方程无处不在,必须了解强化学习算法是如何工作的。但是在我们了解贝尔曼方程之前,我们需要了解一些更有用的符号。我们P和R定义为如下:

是另一种表达我们从状态s开始,采取行动a,到状态s’的期望 (或平均) 奖励的表达方式。
最后,有了这些知识,我们准备推导Bellman方程 (贝尔曼方程)。我们将把状态价值函数考虑到Bellman方程(贝尔曼方程)之内。根据回报的定义,我们可以修改公式(1)为如下所示:
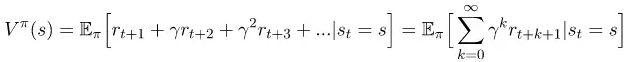
如果我们想从总和回报中提出第一个奖励,公式可以被改写为这样:
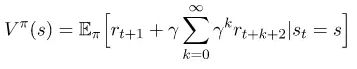
在这里期望可以被描述如果我们采取策略Π时,继续从状态s出发的期望回报。可以通过对所有可能的动作和所有可能的返回状态的求和来描述期望。接下来的两个方程可以帮助我们迈出下一步。
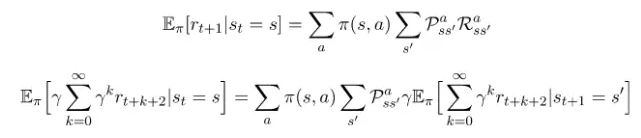
通过对这两个部分分配期望值,我们就可以将我们的方程转化为如下形式:
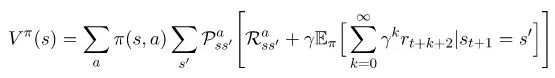
值得注意得是,方程(1)和这个方程的结束部分是一样的。因此,我们可以将其替换,得到如下:
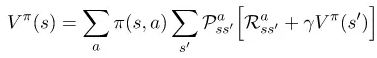
Bellman方程(贝尔曼方程)的动作价值函数可以以类似的方式推导出来。感兴趣的人可以在文章的最后看到具体的步骤。其最终结果如下:
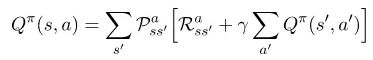
Bellman方程的重要性在于,它能让我们将一个状态的值表达成其他状态的值。这意味着当我们知道状态st+1的值时,我们可以轻松地计算出状态st的值。这为我们解决每个状态值的迭代计算问题打开了大门,因为如果我们知道下一个状态的值,我们就能知道当前状态的值。在这里,最重要的是要记住方程式的编号。最后,随着Bellman方程(贝尔曼方程)的出现,我们可以开始研究如何计算最优策略,并编写我们的第一个强化学习智能体程序。
下一步:动态规划
在下一篇文章中,我们将研究使用动态规划来计算最优策略,这将为更高级的算法奠定基础。然而,这将是第一个实际编写强化学习算法的机会。我们将研究策略迭代和值迭代以及他们的优缺点。在此之前,感谢您的阅读。
正如所承诺的:推导Bellman方程的动作价值函数(贝尔曼方程)
正在我们推导出Bellman方程状态价值函数的过程一样,我们用相同的推导过程得到了一系列的方程,下面我们从方程(2)开始继续推导:
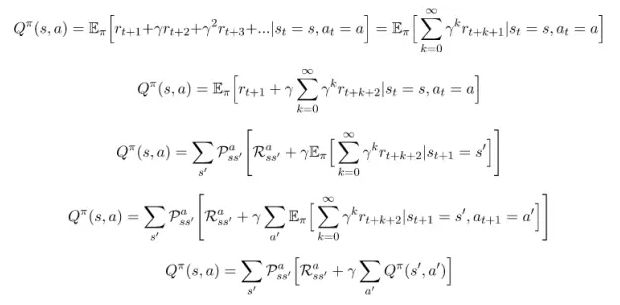
相关链接:
Reinforcement Learning: an Introduction
http://incompleteideas.net/sutton/book/the-book-2nd.html
RL Course by David Silver
https://www.youtube.com/watch?v=2pWv7GOvuf0
RL Course by David Silver PPT
http://www0.cs.ucl.ac.uk/staff/d.silver/web/Teaching.html
Everything You Need to Know to Get Started in Reinforcement Learning
https://joshgreaves.com/reinforcement-learning/introduction-to-reinforcement-learning/
Understanding RL: The Bellman Equations
https://joshgreaves.com/reinforcement-learning/understanding-rl-the-bellman-equations/