博客原文
在nginx官网的blog中,作者Chris Richardson关于微服务的文章有七篇:
1. Introduction to Microservices(微服务介绍)
2. Building Microservices: Using an API Gateway(构建微服务:API网关)
3. Building Microservices: Inter-Process Communication in a Microservices Architecture(构建微服务:微服务架构中的进程间通信)
4. Service Discovery in a Microservices Architecture(微服务架构中的服务发现)
5. Event-Driven Data Management for Microservices(微服务中基于事件驱动的数据管理)
6. Choosing a Microservices Deployment Strategy(微服务部署策略)
7. Refactoring a Monolith into Microservices(重构单体应用为微服务)
第5篇文章是我最关注的问题,这里先翻译它。
01 微服务和分布式数据管理的问题
单体应用一般只会使用一个关系型数据库,使用一个关系型数据库的重要优点是,在你的应用中可以使用事务的ACID特性,它能提供一些重要的保证:
- 原子性 – 改变都是原子级的
- 一致性 – 数据库中的状态总是一致的
- 隔离性 – 即使事务是并行执行的,也会看起来和串行的一样
- 持久性 – 一旦事务被提交,数据的变化是永久性的
这样的结果就是,在应用中你可以很轻松地开启一个事务,然后改变(插入、更新和删除)多行数据,最后一起提交这个事务。
使用一个关系型数据库的另一个很大的好处是,它提供了丰富的、声明式的、并且是标准的查询语句(sql)。你可以很轻松地写一个查询语句,从多张表中查询整合数据。
不幸的是,当我们转向微服务架构的时候,数据访问变得复杂了很多。那是因为数据都被每个微服务所私有,其他的微服务只能通过它的API访问。封装数据是为了确保微服务之间是松耦合的,能彼此独立地发展。如果多个服务访问同一个数据,当数据结构发生变化的时候,需要花费很多时间去协调所有相关的服务更新。
更糟糕的是,不同的微服务经常使用不同的数据库。现在的应用经常存储和处理多种多样的数据,关系型数据库经常不是一种最好的选择。在某些情况下,一个特殊的NOSql数据库会有更多方便使用的数据模型,而且经常会有更高的性能和扩展性。举个例子,如果是一个存储和检索文本的服务,将会使用全文搜索引擎,如Elasticsearch。同样地,如果是一个社交服务存储一些图数据,可能会使用图数据库,如Neo4j。因此,基于微服务的应用中经常讲SQL和NoSql数据库混合着使用,这就是所谓的混合持久化(Polyglot Persistence)。
另外,虽然数据存储的混合持久化架构带了很多好处,包括:松耦合服务、高性能和易扩展,然而,这也带来了一些分布式数据管理的挑战。
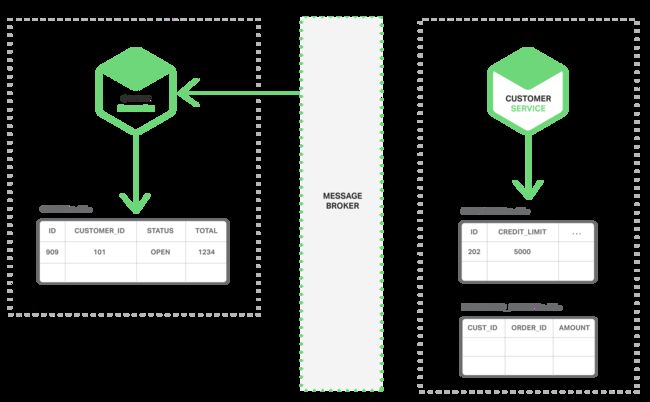
第一个挑战就是,如何实现业务数据的事务,保持跨多个服务的数据一致性。为了证明为什么这是一个问题,让我们看一个在线B2B商城的例子。客户服务提供关于客户的信息,包括他们的信用额度。订单服务管理订单,并且验证新订单金额不能超过客户的信用限额。在这个应用的单体架构版本中,订单服务可以简单地使用一个ACID的事务来实现校验信用余额和创建订单。
相比之下,在微服务架构下订单表和客户表是分别属于各自的服务的。如下图:
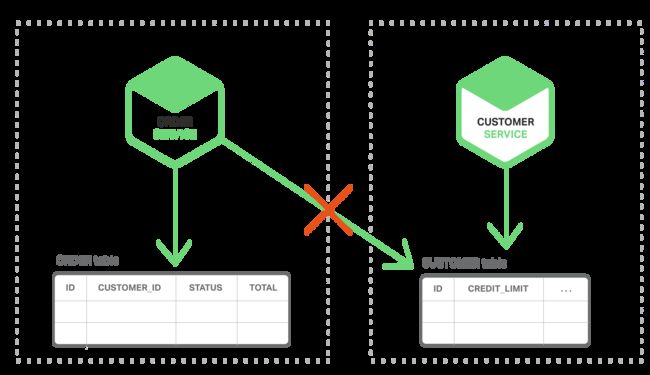
订单服务是不能直接访问客户表的,它仅能使用客户服务提供的API接口。订单服务可以使用分布式事务,例如众所周知的两阶段提交(2PC)。然而,2PC在现在的应用中通常不是一个可用的选择。根据CAP原理,需要你在可用性和ACID式的一致性之间做出选择,通常可用性是较好的选择。此外,很多现在的技术不支持2PC,例如大部分的NoSql数据库。维持跨服务的数据一致性,数据库是必不可少的,因此我们需要另外的解决方案。
第二个挑战是如何实现从多服务中检索数据。例如,让我们想象一下,应用需要展示客户和他最近的订单。如果订单服务提供一个检索客户订单数据的API,你可以检索到这些数据直接加入到应用中。应用从客户服务中检索客户信息,从订单服务中检索客户订单信息。然而,假设订单服务仅支持根据客户主键查询订单(也许它使用的是NoSql数据库,仅支持基于主键的检索)。在这种情况下,显然是没有简单的方法检索到所需要的数据。
02 基于事件驱动的架构
对于很多应用来说,解决方案是采用基于事件驱动的架构。在这样的架构中,当有重要的事情发生时微服务发布一个事件,例如当更新一个交易实体时,其它微服务需要订阅这些事件。当一个微服务接收到一个事件时,它会更新它自己的交易实体,同时这也可能导致更多的事件被发布。
你可以使用事件来实现跨越多个服务的交易的事务性。一个事务包括一系列的步骤,每一步都是由微服务更新一个交易实体和发布一个触发下一个步骤的事件构成。下面的序列图显示了,你如何使用事件驱动的方法在创建订单的时候检查可用信用额度。微服务通过Message Broker交换事件。
- 订单创建一个状态为NEW的订单,然后发布一个订单创建的事件。
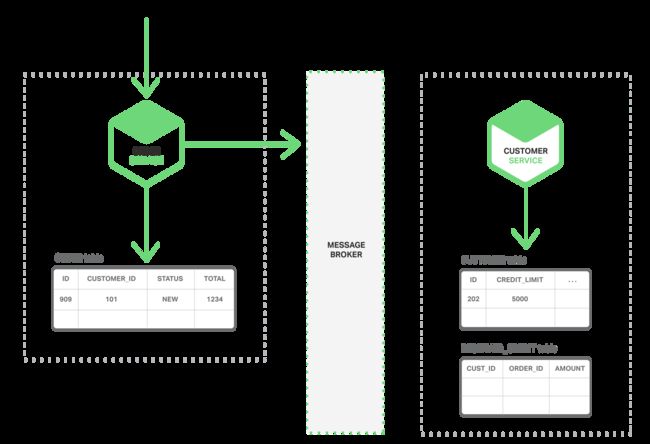
- 客户服务订阅订单创建事件,为这个订单预留信用,然后发布一个信用预留的事件。
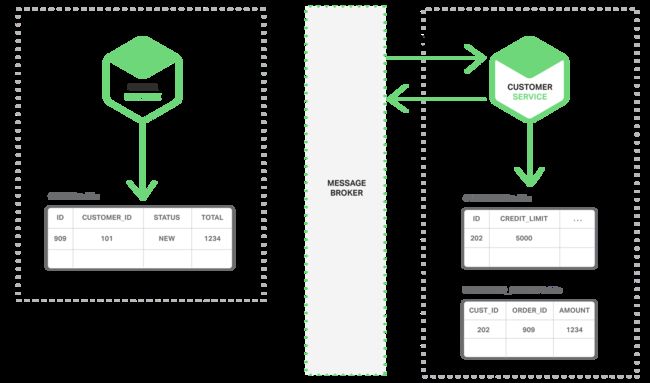
- 订单服务订阅信用预留事件,然后改变订单状态为OPEN。
如果是更复杂的场景可以添加额外的步骤,例如在校验客户信用的同事预留库存。
(1)每个服务要保证更新数据库和发布事件的原子性,更重要的是后者;(2)Message Broker要确保事件被至少传递一次;这样你就可以实现跨多个服务的交易的事务。需要注意的是,这些不是ACID的事务。它们只是提供了一种相对较弱的担保,例如最终一致性。这种事务模型已经被称为基础模型。
你也可以使用事件来维护一个具体的视图,将来自多个微服务的数据预加载进来。维护这个视图的服务需要订阅相关服务,然后更新这个视图。例如客户订单事务更新服务维护了一个客户订单的视图,它需要订阅客户服务和订单服务的事件。
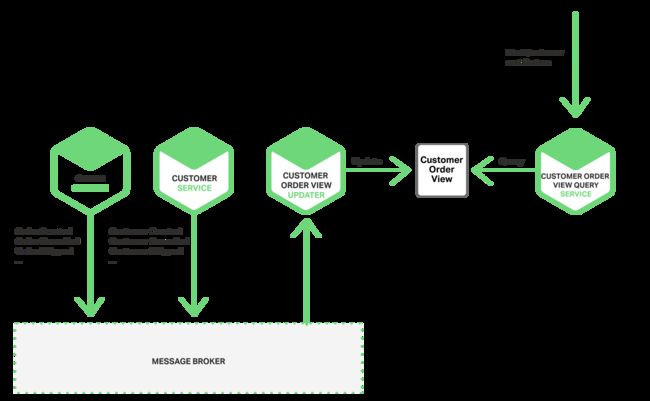
当客户订单更新服务接收到客户或者是订单事件时,它会更新客户订单视图的数据库。可以使用文档数据库(MongoDB)实现客户订单视图,为每个客户存储一个文档。客户订单视图查询服务通过查询客户订单视图数据库处理查询一个客户最近的订单的请求。
基于事件驱动的架构的优点和缺点:实现了跨多个服务的事务,并提供了最终一致性;另一个优点是可以使应用维护一个实体化的视图。一个缺点是,编程模型比使用ACID事务时更加复杂了,通常为了从应用级的故障恢复,你必须实现补偿事务,例如如果校验信用余额失败时你必须取消订单。还有应用必须能够处理不一致的数据,这是因为临时(in-flight)事务的影响是可见。此外,如果实体化的视图中数据还未更新就被服务读取到了,这样你也会看到不一致的数据。另一个缺点是事件的订阅者必须检测和忽略重复的事件。
03 实现原子性
在基于事件驱动的架构中还有另外一个问题,就是更新数据库和发布事件的原子性。例如,订单服务必须在订单表中插入一条数据同时发布一个订单创建的事件,这两个操作必须原子性地完成,这是基本要求。如果在更新数据库之后发布事件之前服务崩溃了,系统就变得不一致了。确保原子性的标准方式是,在涉及到的数据库和Message Broker中使用分布式事务,然而由于上述原因,如CAP原理,这不是我们想要的。
03.1 使用本地事务发布事件
实现原子性的一个方法是,应用使用“仅在本地事务中做多步骤处理”的方法发布事件。关键是需要有一个Event表,它的功能是作为一个消息队列,数据库中存储交易实体的状态。应用可以开启一个本地数据库事务,更新交易实体的状态和插入一条数据到EVENT表,然后提交事务。EVENT表还需要一个独立的应用线程或者进程来发布EVENT到Message Broker,然后使用本地事务标记EVENT已经被发布了。下图描述了该设计:
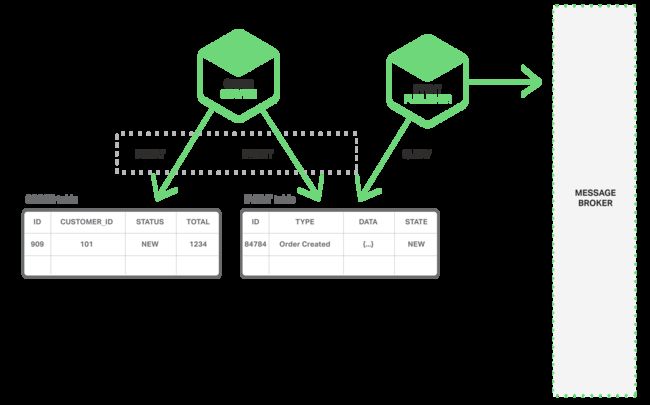
订单服务插入一条数据到订单表,同时插入一个订单创建事件到EVENT表,EVENT表的事件发布线程或进程会将这些未发布的事件发布到Message Broker中,然后更新EVENT表中的事件状态为已发布。
这个方法的优点和缺点:一个优点是,它能保证每次更新都能将事件发布出去,而又不依赖2PC。应用发布了交易级别的事件,我们不需要推断具体发生了什么。这个方法的缺点是,易于犯错,因为程序员必须记得发布事件。这种方法还有一个限制,当我们使用NoSql数据库时这是一个挑战,因为NoSql数据库的事务和查询的能力有限。
这种方法消除了我们对2PC的需求,应用直接使用本地事务更新数据库状态和发布事件。现在让我们看另外一种实现原子性的方法,应用仅仅需要更新状态就能实现。
03.2 利用数据库事务日志
在不使用2PC情况下,保证发布事件的原子性的另一个方法是,创建一个线程或者进程来采集数据库的事务或者提交日志。应用更新数据库的时候,数据被改变的结果都被记录在数据库的事务日志中。数据库事务日志的采集者线程或者进程读取这个事务日志,然后发布事件到Message Broker中。详细设计如下图:

开源的项目 LinkedIn Databus 是一个这种方法的例子。Databus采集Oracle数据库的事务日志,然后根据改变内容发布事件。LinkedIn使用Databus保持各种数据存储中的系统数据的一致性。
另一个例子是,streams mechanism in AWS DynamoDB,这个是管理NoSql数据库的工具。DynamoDB流包含过去24小时的实时订单的改变(创建、更新和删除操作)数据序列,这些数据项会被存储在DynamoDB表中。有一个应用可以从这个流中读取到这些变化,然后将它们发布成事件。
采集事务日志有优点也有缺点。一个优点是,在不使用2PC的情况下,能确保每个更新都被发布成事件;采集事务日志的方法也能简化应用,它将发布事件从应用的业务逻辑中分离出来。一个主要的缺点是,每个数据库的事务日志格式都是特有的,甚至是不同的数据库版本格式也是不同的。同时,在事务日志中从低级别的更新记录转变为高级别的业务事件的逆向工程是很困难的。
采集事务日志解除对2PC的需要,应用只需要做一件事:更新数据库。现在让我们看另外一种不同的方法,不用更新,只需要事件。
03.3 使用事件源
事件源(Event sourcing)实现原子性,而不使用2PC,这是一个完全不同的方法,就是以事件为中心的方法去持久化业务实体。应用存储一系列的状态改变事件,而不是存储一个实体的当前状态。应用依赖重放事件来重建实体的当前状态,无论业务实体的状态什么时候变化,一个新的事件都会被追加到事件列表中。因为存储事件是一个单独的操作,所以它天生具有原子性。
为了展现事件源是如何工作的,举一个订单实体的例子,在一个交易方法中,例如每个订单都被映射成ORDER表中的一行数据和ORDER_LINE_ITEM表中的一行数据。但是当我们使用事件源方法时,订单服务存储订单方式是,存储订单的状态改变事件:创建、通过、发货、取消。每个事件包含充足的数据去重建订单状态。

事件持久化在一个事件数据库中,该数据库有添加和查询实体事件的API,这个事件数据库在架构上类似于一个Message Broker,我们可以实现订阅事件。它提供有订阅事件的API。该事件数据库会将所有的事件传递到所有感兴趣的订阅者中,事件数据库是事件驱动的微服务架构的重要保障。
事件源机制有几个优点,它解决了事件驱动架构中的关键问题,无论状态什么时候变化都能可靠地发布事件。因此,它解决了微服务架构中的数据一致性问题。而且因为它持久化的是事件而不是领域对象,很大程度上还避免了对象和关系型数据库字段不匹配的问题。事件源提供了100%可靠的业务实体改变的审计日志,而且任何时间点都能查询到实体的状态。事件源方法的另外一个好处是,由两个松耦合的业务实体组成的业务逻辑可以交换事件。这样就方便了单体应用转向微服务架构。
事件源机制也有几个缺点,这是一种不同且陌生的编程模型,因此有一定的学习曲线。事件数据库仅支持使用主键查询业务实体,你必须使用 Command Query Responsibility Segregation来实现查询。因此应用程序操作处理最终一致的数据。
04 总结
在微服务架构中,每个微服务都有它自己的数据存储。不同的微服务可能使用不同的SQL和NoSQL数据库,虽然这个数据库架构有很大的好处,但是它创造了分布式数据管理的挑战。第一个挑战是,为了维持不同服务之间的数据一致性,如何实现业务逻辑中的事务;第二个挑战是,如何实现从多个服务中检索数据。
对于大多数的应用来书,解决方案都是采用事件驱动的架构。实现事件驱动的架构一个挑战是,实现更新数据状态和发布事件的原子性。实现这个目的的方法有几个,包括 使用数据库作为消息队列、采集数据库的事务日志 和 事件源机制。
在未来的博客中,我们会继续探讨微服务其他方面的话题。