本文结构:
- 什么是情感分析?
- 怎么分析,技术上如何实现?
cs224d Day 7: 项目2-命名实体识别
2016课程地址
项目描述地址
什么是情感分析?
就是要识别出用户对一件事一个物或一个人的看法、态度,比如一个电影的评论,一个商品的评价,一次体验的感想等等。根据对带有情感色彩的主观性文本进行分析,识别出用户的态度,是喜欢,讨厌,还是中立。在实际生活中有很多应用,例如通过对 Twitter 用户的情感分析,来预测股票走势、预测电影票房、选举结果等,还可以用来了解用户对公司、产品的喜好,分析结果可以被用来改善产品和服务,还可以发现竞争对手的优劣势等等。
怎么分析,技术上如何实现?
首先这是个分类问题。
最开始的方案是在文中找到具有各种感情色彩属性的词,统计每个属性的词的个数,哪个类多,这段话就属于哪个属性。但是这存在一个问题,例如 don't like ,一个属于否定,一个属于肯定,统计之后变成 0 了,而实际上应该是否定的态度。再有一种情况是,前面几句是否定,后面又是肯定,那整段到底是中立还是肯定呢,为了解决这样的问题,就需要考虑上下文的环境。
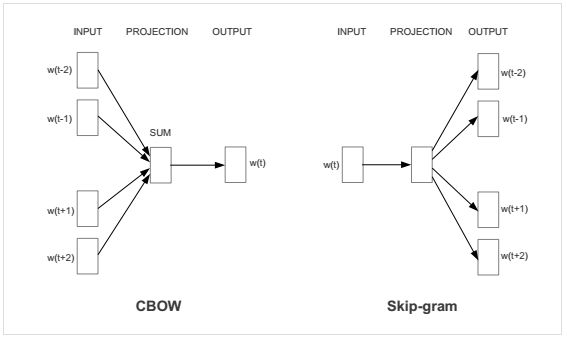
2013年谷歌发了两篇论文,介绍了 Continuous Bag of Words (CBOW) 和 Skip-gram 这两个模型,也就是 Word2Vec 方法,这两种模型都是先将每个单词转化成一个随机的 N 维向量,训练之后得到每个单词的最优表示向量,区别是,CBOW 是根据上下文来预测当前词语,Skip-gram 刚好相反,是根据当前词语来预测上下文。
Word2Vec 方法不仅可以捕捉上下文语境,同时还压缩了数据规模,让训练更快更高效。通过这个模型得到的词向量已经可以捕捉到上下文的信息。比如,可以利用基本代数公式来发现单词之间的关系(比如,“国王”-“男人”+“女人”=“王后”)。用这些自带上下文信息的词向量来预测未知数据的情感状况的话,就可以更准确。
今天的小项目,就是用 word2vec 去解决情感分析问题的。先来简单介绍一下大体思路,然后进入代码版块。
思路分为两部分,第一步,就是先用 word2vec 和 SGD 训练出每个单词的最优表示向量。第二步,用 Softmax Regression 对训练数据集的每个句子进行训练,得到分类器的参数,用这个参数就可以预测新的数据集的情感分类。其中训练数据集的每个句子,都对应一个0-1之间的浮点得分,将这个得分化为 0-4 整数型 5 个级别,分别属于 5 种感情类别,讨厌,有点讨厌,中立,有点喜欢,喜欢。然后将每个句子的词转化成之前训练过的词向量,这样哪些词属于哪个类就知道了,然后用分类器得到分类的边界,得到的参数就可以用来进行预测。
具体实现
接下来以一个初学者的角度来讲一下要如何利用这几个模型和算法来实现情感分析这个任务的,因为项目的代码有点多,不方便全写在文章里,可以去这里查看完整代码。
第一步,用 word2vec 和 SGD 训练出每个单词的最优表示向量。
- 执行 c7_run_word2vec.py
- 其中训练词向量的方法是 c5_word2vec.py
- 同时用 c6_sgd.py 训练参数,并且将结果保存起来,每1000次迭代保存在一个文件中 saved_params_1000.npy
word2vec:
上面提到了,它有两种模型 CBOW 和 Skip-gram,每一种都可以用来训练生成最优的词向量,同时还有两种 cost function 的定义方式,一种是 Softmax cost function, 一种是 Negative sampling cost function,所以在提到 word2vec 的时候,其实是可以有 4 种搭配的方法的,这个小项目里用到的是 Skip-gram 和 Negative sampling cost function 的结合方式。
先定义 skipgram 函数:
给一个中心词 currentWord,和它的窗口大小为 2C 的上下文 contextWords,要求出代表它们的词向量矩阵 W1 和 W2。
def skipgram(currentWord, C, contextWords, tokens, inputVectors, outputVectors,
dataset, word2vecCostAndGradient = softmaxCostAndGradient):
""" Skip-gram model in word2vec """
currentI = tokens[currentWord] #the order of this center word in the whole vocabulary
predicted = inputVectors[currentI, :] #turn this word to vector representation
cost = 0.0
gradIn = np.zeros(inputVectors.shape)
gradOut = np.zeros(outputVectors.shape)
for cwd in contextWords: #contextWords is of 2C length
idx = tokens[cwd]
cc, gp, gg = word2vecCostAndGradient(predicted, idx, outputVectors, dataset)
cost += cc #final cost/gradient is the 'sum' of result calculated by each word in context
gradOut += gg
gradIn[currentI, :] += gp
return cost, gradIn, gradOut
这里用到的成本函数是 Negative sampling,我们的目的就是要使这个成本函数达到最小,然后用这个极值时的参数 grad, 也就是可以得到要求的 wordvectors。要增加准确度,所以可以多次生成中心词和上下文进行训练,然后取平均值,也就是函数 word2vec_sgd_wrapper 做的事情。
def negSamplingCostAndGradient(predicted, target, outputVectors, dataset, K=10):
""" Negative sampling cost function for word2vec models """
grad = np.zeros(outputVectors.shape)
gradPred = np.zeros(predicted.shape)
indices = [target]
for k in xrange(K):
newidx = dataset.sampleTokenIdx()
while newidx == target:
newidx = dataset.sampleTokenIdx()
indices += [newidx]
labels = np.array([1] + [-1 for k in xrange(K)])
vecs = outputVectors[indices, :]
t = sigmoid(vecs.dot(predicted) * labels)
cost = -np.sum(np.log(t))
delta = labels * (t-1)
gradPred = delta.reshape((1, K+1)).dot(vecs).flatten()
gradtemp = delta.reshape((K+1, 1)).dot(predicted.reshape(1, predicted.shape[0]))
for k in xrange(K+1):
grad[indices[k]] += gradtemp[k, :]
return cost, gradPred, grad
**接着用 sgd **迭代 40000 次得到训练好的 wordVectors。
wordVectors0 = sgd(
lambda vec: word2vec_sgd_wrapper(skipgram, tokens, vec, dataset, C,
negSamplingCostAndGradient),
wordVectors, 0.3, 40000, None, True, PRINT_EVERY=10)
关于 word2vec 之前有写过一篇 word2vec 模型思想和代码实现,想了解详细原理和具体怎样实现的童鞋可以去这个这里看。
第二步,用 Softmax Regression 对训练数据集进行分类学习。
- 执行 c10_sentiment.py
- 其中用 c6_sgd.py 去训练权重 weights,
- 然后用 c8_softmaxreg.py 根据训练好的 features,labels,weights 进行类别 label 的预测。
先将数据集分为三部分,training set,deviation set,和 test set。
trainset = dataset.getTrainSentences()
devset = dataset.getDevSentences()
testset = dataset.getTestSentences()
在 trainset 中,每句话对应一个情感的得分或者说是分类,先将每个 word 在 token 中找到序号,然后在第一步训练好的 wordvectors 中找到相应的词向量。
trainFeatures[i, :] = getSentenceFeature(tokens, wordVectors, words)
然后用 sgd 和 softmax_wrapper 迭代 10000 次去训练 weights:
weights = sgd(lambda weights: softmax_wrapper(trainFeatures, trainLabels, weights, regularization), weights, 3.0, 10000, PRINT_EVERY=100)
接着用 softmax regression 进行分类的预测:
_, _, pred = softmaxRegression(trainFeatures, trainLabels, weights)
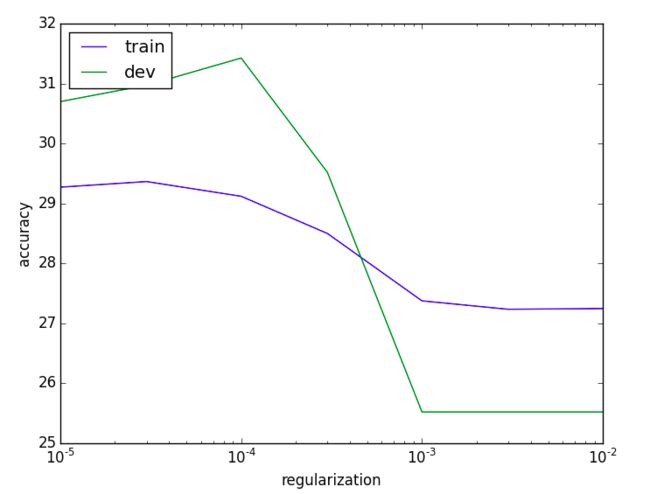
上面用到了不同的 REGULARIZATION=[0.0, 0.00001, 0.00003, 0.0001, 0.0003, 0.001, 0.003, 0.01] ,在其中选择 accuracy 最好的 REGULARIZATION 和相应的结果:
best_dev = 0
for result in results:
if result["dev"] > best_dev:
best_dev = result["dev"]
BEST_REGULARIZATION = result["reg"]
BEST_WEIGHTS = result["weights"]
用这个最好的参数在 test set 上进行预测:
_, _, pred = softmaxRegression(testFeatures, testLabels, BEST_WEIGHTS)
并且的到 accuracy:
print "Test accuracy (%%): %f" % accuracy(testLabels, pred)
下图是 accuracy 和 REGULARIZATION 在 devset 和 trainset 上的趋势:
以上就是 sentiment analysis 的基本实现,把它和爬虫相结合,会有很多好玩的玩儿法!
[cs224d]
Day 1. 深度学习与自然语言处理 主要概念一览
Day 2. TensorFlow 入门
Day 3. word2vec 模型思想和代码实现
Day 4. 怎样做情感分析
Day 5. CS224d-Day 5: RNN快速入门
Day 6. 一文学会用 Tensorflow 搭建神经网络
Day 7. 用深度神经网络处理NER命名实体识别问题
Day 8. 用 RNN 训练语言模型生成文本
Day 9. RNN与机器翻译
Day 10. 用 Recursive Neural Networks 得到分析树
Day 11. RNN的高级应用
我是 不会停的蜗牛Alice
85后全职主妇
喜欢人工智能,行动派
创造力,思考力,学习力提升修炼进行中
欢迎您的喜欢,关注和评论!