作者: 一字马胡
转载标志 【2017-12-29】
更新日志
| 日期 | 更新内容 | 备注 |
|---|---|---|
| 2017-12-29 | 创建分析文档 | Spring源码分析系列文章(二) |
前言
在Spring源码分析的第一篇文章Spring源码分析之Bean的解析中,主要梳理了Spring Bean解析的链路,当然只是梳理了主干部分,细节的内容没有涉及太多。本文接着上一篇文章,开始进行Spring Bean加载的源码分析,bean解析完成之后,还不是可用的对象实例,需要进行加载,所谓bean的加载,就是将解析好的BeanDefinition变为可用的Object。在进行源码分析之前,可以猜测一下Spring bean加载到底做了些什么工作。首先,Spring bean解析的工作将我们在xml中配置的bean解析成BeanDefinition并且放在内存中,现在,我们可以拿到每一个bean的完整的信息,其中最重要的应该是Class信息,因为实例化对象需要知道具体需要实例化的Class信息。还需要知道具体bean的属性值等信息,而这些数据目前都是可以拿到的,所以接下来的事情就是根据这些信息首先new一个对于Class类型的Object,然后进行一些初始化,然后返回。
当然,Spring bean加载的实现远远没有这么简单,这中间涉及的内容很多,本文依然不会涉及太多细节的内容,主要梳理Spring bean加载的主干流程,知道一个bean是如何被解析,以及如何加载的,是本文以及第一篇文章内容所想要表达的内容。
Spring Bean加载流程分析
分析Spring bean加载的第一步是找到分析的入口。接着上一篇文章的例子,从下面的代码开始分析:
String file = "applicationContext.xml";
ApplicationContext context = new ClassPathXmlApplicationContext(file);
ModelA modelA = (ModelA) context.getBean("modelA");
跟进context.getBean,可以在AbstractBeanFactory中找到具体的实现:
public Object getBean(String name) throws BeansException {
return doGetBean(name, null, null, false);
}
可以看到实际执行的方法是doGetBean,因为这个方法较为复杂,所以拆开来分析实现的具体细节。首先关注下面的代码:
final String beanName = transformedBeanName(name);
protected String transformedBeanName(String name) {
return canonicalName(BeanFactoryUtils.transformedBeanName(name));
}
public static String transformedBeanName(String name) {
Assert.notNull(name, "'name' must not be null");
String beanName = name;
while (beanName.startsWith(BeanFactory.FACTORY_BEAN_PREFIX)) {
beanName = beanName.substring(BeanFactory.FACTORY_BEAN_PREFIX.length());
}
return beanName;
}
我们传递进去的name就是我们在xml中配置的id,首先会调用transformedBeanName对传递的name做一次处理,在transformedBeanName中又调用了BeanFactoryUtils.transformedBeanName方法来进行做处理,具体的内容就是判断我们传递的name是不是以“&”开头的,要是的需要去掉再返回。需要注意的是,我们传递的name可能是bean的别名,也可能是BeanFactory,所以transformedBeanName的操作的目的就是取到真正的bean的名字,以便开始后续的流程。
获取到bean的name之后,开始走下面的流程,需要注意下面的方法调用:
// Eagerly check singleton cache for manually registered singletons.
Object sharedInstance = getSingleton(beanName);
具体的getSingleton的实现细节可以参考下面的代码:
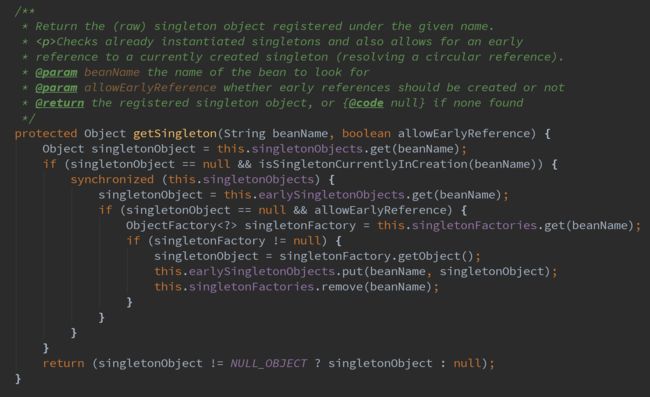
因为我们的bean在配置的时候可能会被配置为单例或者原型模式,单例模式的bean全局只会生成一次,所以getSingleton方法的目的是去Spring的单例bean缓存中寻找是否该bean已经被初始化了,如果已经被初始化了那么直接从缓存取到就可以了,就没有必要走下面的流程了。上面贴出的getSingleton代码实现的就是尝试从缓存map中取bean,当然,这里面还是涉及一些其他的流程的。如果发现需要取的bean实例没有在缓存中,那么就不能走缓存了,就需要走接下来的流程了。方法isSingletonCurrentlyInCreation实现的内容是判断当前bean是否是正在被加载的bean,判断方法是使用一个set来实现,没当在进行加载单例bean之前,Spring会将该bean的name放到set中。earlySingletonObjects是一个map,存储的是还没有加载完成的bean的信息。如果发现从earlySingletonObjects中取到的bean实例为null的话,getSingleton方法就会进行该单例bean的加载。在实现上,首先通过取到用于创建该bean的BeanFactory,然后调用BeanFactory的getObject方法获取到bean实例。
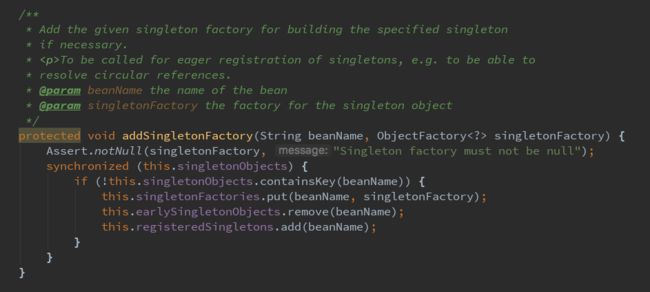
singletonFactories存储着bean name以及创建该bean的BeanFactory。那用于获取bean实例的BeanFactory是什么时候被什么对象放到map中来的呢?可以发现是一个叫做addSingletonFactory的方法在做这件事情,下面是这个方法的实现细节:
那是什么地方调用该方法的呢?可以在AbstractAutowireCapableBeanFactory类中的doCreateBean方法中找到该方法的调用细节,相关的上下文代码如下:
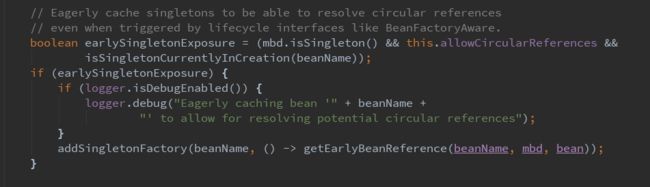
接着回到getSingleton方法,获取到用于创建bean实例的BeanFactory之后,就可以使用singletonFactory.getObject()来获取到实例对象了。下面来分析一下这条链路的具体流程。这里需要注意一下,我们需要知道这个BeanFactory到底是什么样的实现,才能分析具体的内容,所以解铃还得系铃人,回头看看到底放到singletonFactories中的是一个什么样的BeanFactory。最后发现,实际执行的方法是getEarlyBeanReference,见下面的代码:
/**
* Obtain a reference for early access to the specified bean,
* typically for the purpose of resolving a circular reference.
* @param beanName the name of the bean (for error handling purposes)
* @param mbd the merged bean definition for the bean
* @param bean the raw bean instance
* @return the object to expose as bean reference
*/
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof SmartInstantiationAwareBeanPostProcessor) {
SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp;
exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName);
}
}
}
return exposedObject;
}
实际上我们需要关心的是第三个参数bean,这也就是实际的bean实例对象,那这个bean到底是什么呢?是怎么样被创建出来的呢?这就得回头看调用getEarlyBeanReference方法的上下文了,所以回头看doCreateBean方法中的具体内容。主要看下面这段代码:
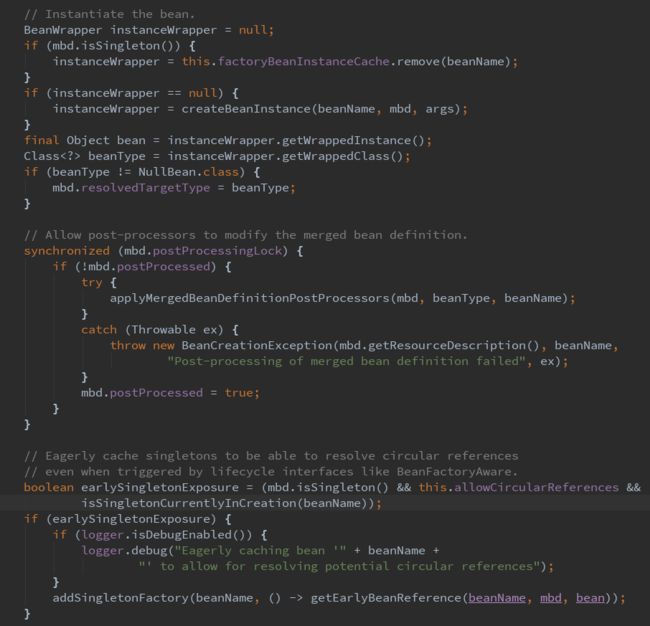
主要的流程是看缓存里面有没有,如果有则不需要再次加载,否则需要调用方法createBeanInstance来创建bean实例,为了简化问题,主要分析createBeanInstance这个方法的实现细节。首先调用方法resolveBeanClass获取bean的Class,然后判断权限等操作,首先来看instantiateBean方法的具体细节,该方法代表使用默认构造函数来进行bean的实例化,而autowireConstructor方法则代表使用有参数的构造函数来进行bean的实例化。下面是instantiateBean的实现细节:

主要关注:beanInstance = getInstantiationStrategy().instantiate(mbd, beanName, parent)这一句代码,然后看instantiate这个方法的实现细节:
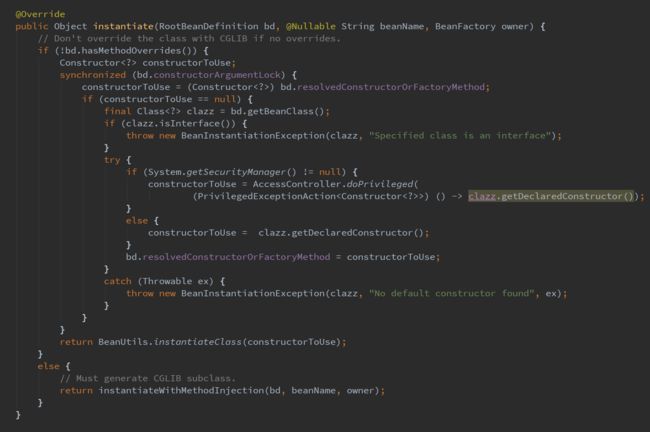
主要关注:return BeanUtils.instantiateClass(constructorToUse)这行代码以及else分支的return语句,闲来看return BeanUtils.instantiateClass(constructorToUse)这句代码的实现细节:
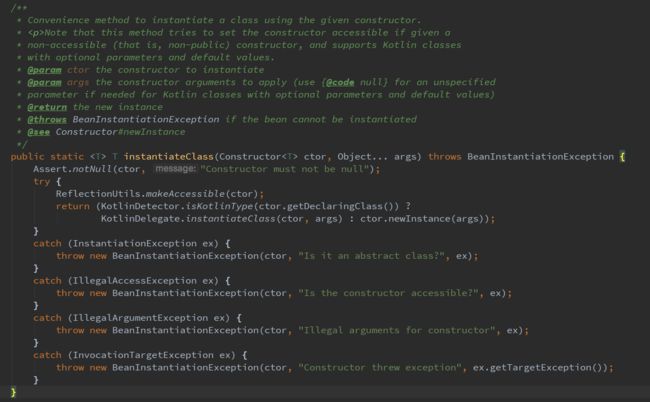
其实就是根据类的构造函数以及构造函数参数来new一个对象,具体的细节可以再跟进去详细研究。下面来看else分支中的instantiateWithMethodInjection(bd, beanName, owner),下面是具体的实现代码:
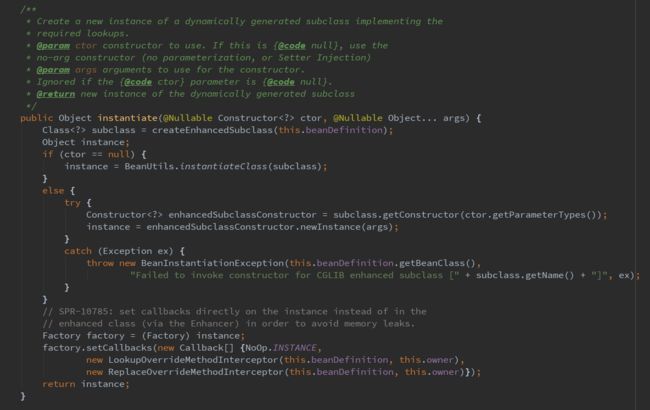
具体的内容就是使用CGlib来进行对象的创建,具体的内容可以参考其他的资料,或者再跟下去来详细研究。下面来看使用有参构造函数来进行bean的实例化的具体实现细节,对应的方法是autowireConstructor,该方法相对于使用默认构造函数来进行bean的实例化来说,需要做的事情是,因为bean可能有多个构造函数,并且可能权限不同,所以Spring需要根据参数个数以及类型选取一个合适的构造函数来进行bean的实例化,这部分代码较多,但是大概的流程就是这样,代码就不再贴出来了。
在new出来一个bean实例之后,还没有真正完成Spring的bean加载内容,因为除了new出来一个Object之外,还需要做其他的事情,下面来分析一下Spring都做了一些什么事情。首先是populateBean方法,该方法实现的功能是对bean进行属性注入,下面是该方法的关键代码:
if (mbd.getResolvedAutowireMode() == RootBeanDefinition.AUTOWIRE_BY_NAME ||
mbd.getResolvedAutowireMode() == RootBeanDefinition.AUTOWIRE_BY_TYPE) {
MutablePropertyValues newPvs = new MutablePropertyValues(pvs);
// Add property values based on autowire by name if applicable.
if (mbd.getResolvedAutowireMode() == RootBeanDefinition.AUTOWIRE_BY_NAME) {
autowireByName(beanName, mbd, bw, newPvs);
}
// Add property values based on autowire by type if applicable.
if (mbd.getResolvedAutowireMode() == RootBeanDefinition.AUTOWIRE_BY_TYPE) {
autowireByType(beanName, mbd, bw, newPvs);
}
pvs = newPvs;
}
autowireByName代表根据名字自动注入属性,而autowireByType实现的是根据类型自动注入属性,根据名字注入相对简单一些,而根据类型注入要复杂很多,下面先来分析根据名字自动注入属性的分析。下面是autowireByName的代码:
protected void autowireByName(
String beanName, AbstractBeanDefinition mbd, BeanWrapper bw, MutablePropertyValues pvs) {
String[] propertyNames = unsatisfiedNonSimpleProperties(mbd, bw);
for (String propertyName : propertyNames) {
if (containsBean(propertyName)) {
Object bean = getBean(propertyName);
pvs.add(propertyName, bean);
registerDependentBean(propertyName, beanName);
if (logger.isDebugEnabled()) {
logger.debug("Added autowiring by name from bean name '" + beanName +
"' via property '" + propertyName + "' to bean named '" + propertyName + "'");
}
}
else {
if (logger.isTraceEnabled()) {
logger.trace("Not autowiring property '" + propertyName + "' of bean '" + beanName +
"' by name: no matching bean found");
}
}
}
}
unsatisfiedNonSimpleProperties方法首先获取所有需要进行依赖注入的属性名称,然后保存起来,特别需要注意的是registerDependentBean这个方法的调用,该方法实现的是维护bean的依赖管理。接着是根据类型注入autowireByType的实现。该方法的实现还是很复杂的,暂时不对该方法进行分析。
当执行完上面两个方法之后,已经获取到了所有需要注入的属性信息,pvs持有这些信息,接着,applyPropertyValues方法会实际将这些依赖注入。下面来分析一下applyPropertyValues方法的具体实现流程。具体的实现细节可以参考下面给出的索引:
AbstractAutowireCapableBeanFactory#applyPropertyValues
主要关注核心代码:bw.setPropertyValues(mpvs),bw是bean实例对象,mpvs是属性信息。如果再追踪下去,就可以看到如下的代码链路:
public void setPropertyValues(PropertyValues pvs) throws BeansException {
setPropertyValues(pvs, false, false);
}
public void setPropertyValues(PropertyValues pvs, boolean ignoreUnknown, boolean ignoreInvalid)
throws BeansException {
List propertyAccessExceptions = null;
List propertyValues = (pvs instanceof MutablePropertyValues ?
((MutablePropertyValues) pvs).getPropertyValueList() : Arrays.asList(pvs.getPropertyValues()));
for (PropertyValue pv : propertyValues) {
setPropertyValue(pv);
}
}
这里面已经去掉了一些异常处理的代码,只留下最核心的代码,主要关注setPropertyValue这个方法,再继续跟踪下去:
public void setPropertyValue(PropertyValue pv) throws BeansException {
setPropertyValue(pv.getName(), pv.getValue());
}
到这里就应该很清晰了,pv.getName()是属性名称,而pv.getValue()就是实际上注入的依赖。在完成依赖注入之后,应该说bean就可以使用了,但是因为Spring还提供了一些其他的标签让用户进行个性化设置,比如初始化方法、销毁方法等,接着看exposedObject = initializeBean(beanName, exposedObject, mbd)这行代码的实际工作流程。
protected Object initializeBean(final String beanName, final Object bean, @Nullable RootBeanDefinition mbd) {
if (System.getSecurityManager() != null) {
AccessController.doPrivileged((PrivilegedAction这其中调用了几个个性化的方法,第一个是invokeAwareMethods,是去访问子类的Aware,BeanClassLoaderAware, BeanFactoryAware等,下面是该方法的实现细节:
private void invokeAwareMethods(final String beanName, final Object bean) {
if (bean instanceof Aware) {
if (bean instanceof BeanNameAware) {
((BeanNameAware) bean).setBeanName(beanName);
}
if (bean instanceof BeanClassLoaderAware) {
ClassLoader bcl = getBeanClassLoader();
if (bcl != null) {
((BeanClassLoaderAware) bean).setBeanClassLoader(bcl);
}
}
if (bean instanceof BeanFactoryAware) {
((BeanFactoryAware) bean).setBeanFactory(AbstractAutowireCapableBeanFactory.this);
}
}
}
接着是applyBeanPostProcessorsBeforeInitialization方法,是访问子类的后处理器内容,下面是该方法的详细实现:
public Object applyBeanPostProcessorsBeforeInitialization(Object existingBean, String beanName)
throws BeansException {
Object result = existingBean;
for (BeanPostProcessor beanProcessor : getBeanPostProcessors()) {
Object current = beanProcessor.postProcessBeforeInitialization(result, beanName);
if (current == null) {
return result;
}
result = current;
}
return result;
}
接着是invokeInitMethods方法,是调用用户设定的init方法,下面是该方法的实现细节:
protected void invokeInitMethods(String beanName, final Object bean, @Nullable RootBeanDefinition mbd)
throws Throwable {
boolean isInitializingBean = (bean instanceof InitializingBean);
if (isInitializingBean && (mbd == null || !mbd.isExternallyManagedInitMethod("afterPropertiesSet"))) {
if (logger.isDebugEnabled()) {
logger.debug("Invoking afterPropertiesSet() on bean with name '" + beanName + "'");
}
if (System.getSecurityManager() != null) {
try {
AccessController.doPrivileged((PrivilegedExceptionAction这其中需要注意的一点是,在该方法中调用了afterPropertiesSet方法,然后是获取了用户设定的init方法的名字,然后调用invokeCustomInitMethod方法执行了这个init方法。
到此,单例bean的加载好像分析到头了,确实是,当然这只是一个很小的分支,还有其他的分支没有走,现在回到doGetBean方法,继续分析剩下的代码。为了分析简单,直接从下面的代码开始分析,其他没有分析到的代码以后再详细分析,现在主要是希望走通整个流程,所以只会挑选关键的代码进行分析。首先是下面的代码:
// Guarantee initialization of beans that the current bean depends on.
String[] dependsOn = mbd.getDependsOn();
if (dependsOn != null) {
for (String dep : dependsOn) {
if (isDependent(beanName, dep)) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
"Circular depends-on relationship between '" + beanName + "' and '" + dep + "'");
}
registerDependentBean(dep, beanName);
getBean(dep);
}
}
因为我们的bean可能依赖其他的bean,所以需要在加载当前bean之前加载它所依赖的bean。所以这里面又调用了getBean方法来循环加载依赖的bean。接着看下面的代码:
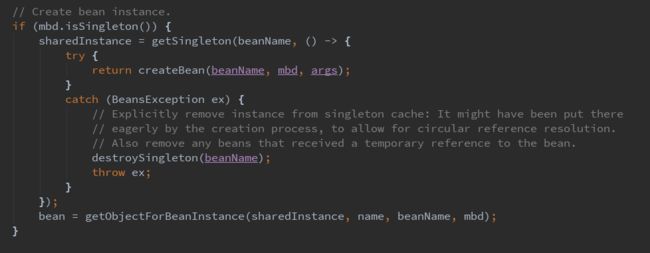
如果bean是一个单例bean,那么会走到该分支里面。会调用getSingleton方法来加载该bean。getSingleton方法的第一个参数是beanName,第二个参数比较关键,是用于创建bean的BeanFactory,所以有必要仔细分析一下该BeanFactory。因为在getSingleton方法中关键的步骤就是调用BeanFactory的getObject方法来获取到一个bean的实例,当然还有很多其他的细节需要判断,但不再本文的叙述范围之内。下面来看这个BeanFactory的具体实现。根据上面贴出的代码,其实内部关键调用了一个方法createBean。下面来看这个方法的实现细节。该方法的关键内容如下:

首先会调用resolveBeforeInstantiation方法,这是一个试探性的方法调用,根据描述,该方法是给BeanPostProcessors一个机会来返回bean实例,具体看看该方法的细节:
protected Object resolveBeforeInstantiation(String beanName, RootBeanDefinition mbd) {
Object bean = null;
if (!Boolean.FALSE.equals(mbd.beforeInstantiationResolved)) {
// Make sure bean class is actually resolved at this point.
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
Class targetType = determineTargetType(beanName, mbd);
if (targetType != null) {
bean = applyBeanPostProcessorsBeforeInstantiation(targetType, beanName);
if (bean != null) {
bean = applyBeanPostProcessorsAfterInitialization(bean, beanName);
}
}
}
mbd.beforeInstantiationResolved = (bean != null);
}
return bean;
}
该方法关键会先调applyBeanPostProcessorsBeforeInstantiation方法来调用实现类的postProcessBeforeInstantiation方法,如果返回内容还为null,就会继续调用applyBeanPostProcessorsAfterInitialization方法来调用实现类的postProcessAfterInitialization。所以这里需要注意一下,这也是一个Spring使用技巧点,可以继承BeanPostProcessor来实现个性化的Spring bean定制。
当resolveBeforeInstantiation方法返回null的时候,就会继续调用doCreateBean方法来加载bean的实例。该方法中首先一个比较关键的方法调用是createBeanInstance,下面的流程在上文中已经进行过了,就不再赘述了。只要知道doCreateBean方法返回的就是一个bean的实例就好了。
当然,我们获取到的bean实例可能是一个FactoryBean,那么就需从FactoryBean中获取到Object。实现该流程的是方法getObjectForBeanInstance。主要看该方法中调用的getObjectFromFactoryBean方法。进到getObjectFromFactoryBean方法之后主要注意方法doGetObjectFromFactoryBean。该方法的主要流程代码如下:
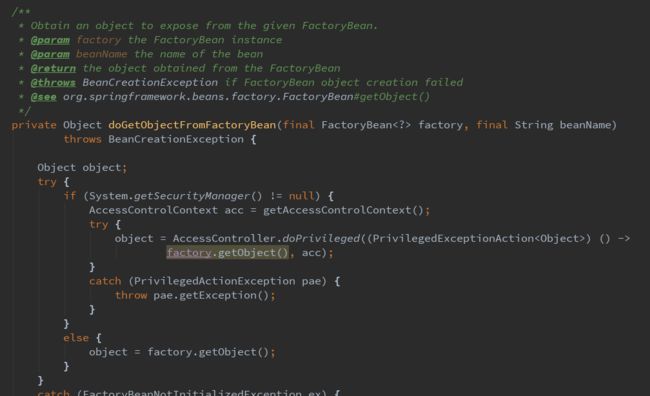
主要关注代码:object = factory.getObject(),继续看下面的代码:
public final T getObject() throws Exception {
if (isSingleton()) {
return (this.initialized ? this.singletonInstance : getEarlySingletonInstance());
}
else {
return createInstance();
}
}
这里区分了单例和原型两种bean,如果bean被配置为单例,则会走第一个分支,原型则会走第二个分支。对于单例bean,首先会判断是否已经初始化过了,如果已经初始化过了,那么就直接取到bean实例,否则会调用getEarlySingletonInstance来获取到bean的实例,下面来具体分析一下getEarlySingletonInstance这个方法的执行流程。跟踪进去最后执行的代码是下面的方法:
private T getEarlySingletonInstance() throws Exception {
Class[] ifcs = getEarlySingletonInterfaces();
if (ifcs == null) {
throw new FactoryBeanNotInitializedException(
getClass().getName() + " does not support circular references");
}
if (this.earlySingletonInstance == null) {
this.earlySingletonInstance = (T) Proxy.newProxyInstance(
this.beanClassLoader, ifcs, new EarlySingletonInvocationHandler());
}
return this.earlySingletonInstance;
}
到这里就很清晰了,还是会判断是否已经加载过了,如果加载过了,那么就不会重复实例化bean了,否则就使用java的动态代理技术生成一个bean实例。
对于原型bean来说,会调用createInstance方法进行bean的实例化过程,对不同类型的FactoryBean会使用不同的子类的方法来获取实例,比如AbstractFactoryBean的子类等等。
到这里需要说明一下FactoryBean这个类,FactoryBean是一个Bean,实现了FactoryBean接口的类有能力改变bean,FactoryBean希望你实现了它之后返回一些内容,Spring会按照这些内容
去注册bean,这也给了程序员一个定制bean的机会,继承了FactoryBean的子类的bean的加载会调用FactoryBean的getObject方法获取bean实例,而且,我们使用getBean获取到的是FactoryBean的getObject方法调用的结果,如果想要获取到FactoryBean本身,需要在bean前面加上“&”标志,这个逻辑可以在方法getObjectForBeanInstance中找到:
// Now we have the bean instance, which may be a normal bean or a FactoryBean.
// If it's a FactoryBean, we use it to create a bean instance, unless the
// caller actually wants a reference to the factory.
if (!(beanInstance instanceof FactoryBean) || BeanFactoryUtils.isFactoryDereference(name)) {
return beanInstance;
}
如果对BeanFactory和FactoryBean傻傻分不清,可以参考文章Spring的BeanFactory和FactoryBean,主要思路就是看后缀,BeanFactory是一种FactoryBean,是用来生成bean的,而FactoryBean是一个bean,它是用来改变FactoryBean生成bean的路径的。
需要注意的一点是,上文的分析中并没有涉及缓存的内容,这部分内容比较离散,我们在走主流程的时候只要知道它会在何时的时候填充缓存(主要关注单例bean),以及在需要的时候从缓存中获取就可以了。
接着回到doGetBean方法中,看下面的分支:
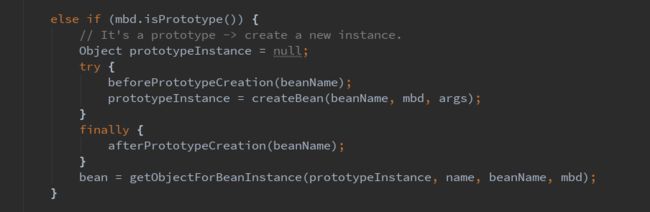
如果不是一个单例的话,那么可能是一个Prototype类型的bean,所谓Prototype类型的bean,就是每次都会创建一个bean实例,这是和单例区分开来说的,除此之外,和单例bean的加载没有区别,所以也不再赘述了。
doGetBean方法还有后续的流程没有走完,但是到此为止我们已经明白了一个bean是如何被加载的,它现在几乎可以被使用了,后面就是一些收尾工作,具体流程就不再分析了,后续会进行一些策略性的补充。
本文涉及的内容时Spring bean的加载,内容较多,而且较为复杂,很多内容都没有提及,只是大概梳理了一下主干流程,接着上一篇文章来继续分析,在上一篇文章中分析了Spring bean解析的流程,解析完成之后需要加载才能使用,在加载的过程中设计很多内容,其中包括bean的实例化,以及bean的依赖注入等内容。bean的加载大体上分为单例和原型,本文主要分析了单例bean的加载,原型bean的加载与单例bean的加载流程是一样的,只是单例全局只有一个bean实例,所有可以从缓存中取到,而原型bean每次都是新创建一个bean实例。总体来讲,分析Spring的源码还是比较复杂的,本文中欠缺的内容将在未来陆续补充完善,但主要目的还是梳理流程,走一遍Spring容器的方方面面,这样使用起来就会多几分底气了。