差不多2月左右,冲假的缘故休得特别多,又正好碰到统计上无法解决的问题,于是本人也很有野心的列了一张清单,几月的时候要看完哪些书目、做点小研究、整理一些心得什么的,不过就像许多人每年的「梦想板」,写爽的成分比较多…,趁着空档,终于赶在开工前夕把ptt上也常有推荐的经典译作, Neter原著的「应用线性回归模型」扫完,再加上看了一部分的「类别资料分析导论」,穿插着几本统计小书,一时恐怕是整理不完了。
我们准备来谈谈回归分析(回归分析?)的本质以及它的历史轶事,但无论如何,一窥回归分析的堂奥之前,还是有些观念需要先建立起来。
为何这么麻烦?把方法完整巡游一遍后,回头探讨基本结构是很有好处的,像是出国旅行,人生地不熟的时候,常常只能跟着人潮与旅行团规划走,但熟练的旅行者,会钻进街巷之中,寻找连结着城市各处的最短途径以及稍纵即逝的美丽风景。
首先,故事从这里开始:回归是什么?
统计回归模型( Regression )的起源:天才可以无限制地被遗传下去吗?
时空来到好久好久以前,英国的达尔文(对,就是那个达尔文)有个谣传智商高达200的天才表弟叫Galton , Galton是个惊人的另类科学家,虽不是正统的学院学者,却出版了数以百计的书籍与论文,领域之广几乎无所不包,被尊称为「 Victorian Polymath 」。
Galton 身为伟大的达尔文的表弟,不意外地,他对遗传学也很有心得,并首创了优生学( Eugenics )用词。由于出身银行业兼军火商的家族, Galton 幸运地得以任意从事他喜爱的探险与科学活动,在1880 中期到1890 年代这段时间, Galton 找来了一群人做了各种人体特征的纪录,他得到两个心得:
第一,有两随机变数X 、 Y ,当其中一者的改变多少受到另一方的影响时,必然存在同时作用于此二者的因素,将这种关系定义为「有相关」,反之则为独立。
第二,当时人类遗传学开始相信优势是可以遗传给后代的,但是会不会持续下去则是未证实的疑问,譬如身高都很高的夫妻,是否会生下更高的儿女?

Galton 发现,父母特征的确会遗传给后代,但是并不会产生极端身高的族群。当父母的身高已经远离平均身高时,生下的儿女身高并没有持续「远离」平均,而会稍微「靠近」平均,也就是相对矮了一点;反之父母身高很矮的后代,身高会相对其父母「靠近」平均一点。
当然双亲身高都很高的后代,比起双亲身高都很矮的后代,还是相对较高的,不过差距并未一直增加,反而会持续减少。
Galton把这个「极端」往「平均」移动的现象称为「 regression to the mean 」。用东方人的说法,就是「物极必反」,至于「极物」将「反向」何方?
Galton 说,这个答案就叫「平均数」。
Galton的第一项发现「相关系数r」,后来由另一位在统计史上名气鼎盛的Karl Pearson推导出线性通则,该式又名「Pearson积差相关系数」。
晚年的Galton与Pearson及Weldon关系相当好,不仅是研究伙伴,也资助二人创办了至今影响力仍巨的生物统计期刊《 Biometrika 》,在Galton的支持下,早期的《 Biometrika 》皆以超水准的规格发行,让该刊知名度大开, Galton过世以后也是由Pearson亲自为其整理传记。
Pearson的介绍,可参阅《卡方检定ON THE CROSS:PEARSON, YATES AND FISHER 》。
回归分析概念的视觉化
Galton 的回归概念,被逐渐补充、扩大,变得越来越完整,现在回归已是一个意义广泛的用词,更好的说法是「回归模型」,在这个模型底下包含了许多用以解释、判断、修正的诸多内容,若要产生一个「真正正确而有用」的模型所需的知识量,只看入门教科书绝对是不够的。
从模型整合的角度出发,所有回归都具有三个基本要件:
1. 系统成分( Systematic Component )
2. 随机成分( Random Component )
3. 连结函数( Link Function )
系统成分是给定的回归中,用来解释研究现象的元素,随机成分则是研究希望讨论的「未知」的现象。而「连结」就是描述系统成分与随机成分两者之间关系的函数。
从文字定义似乎不易理解「回归」是什么,由图入手或许清楚得多,以下利用某地区房屋「坪数X 」对应「房价(单位:千万) Y 」的简回归( Simple Regression )范例说明之:

图中的圆点,是抽样的资料点,贯穿其中的直线,则是「回归直线」,回归直线的意义即是Galton 所谓的「平均」。残差e31 、 e33 分别表示第31 、 33 个资料点与平均线的差异,其余以此类推。其中,「坪数X 」就是系统成分,而「房价Y 」则是随机成分,对一个简单直线回归,连结函数就是线性方程式。
由于「回归到平均」的性质,观察回归直线与资料点的距离,即可推估该资料的一些特性,掌握这些数学特性,可以帮助我们做几件事:
1.可推估某资料点是否为「离群的极端值」。
2.可计算自变数X 与应变数Y 的相关性。
3.根据上述的相关性,可描述资料集的发展趋势。
4.拓展到拥有多个预测变数X 的「复回归」,可分析多个自变数与应变数的互动。
5.可大胆预测「资料集之外(括号外的部份)」的资讯,对应变数的可能影响。
例图用的是「线性回归」,然而回归用以描述自变数与应变数关系的函数不只有直线而已,二次或三次以上曲线、指数、对数、分段都是可行的方式,这也衍生出各种回归问题。
回归分析的公式化与残差
以最普遍的直线回归为例,典型的线性回归式如下:

此式称为「母体回归直线」,是描述「真实未知情况」的完美配适。但是因为完整、正确的普查在多数情况下几乎是不可行的,因此没人知道「真实情况」究竟是如何,退而求其次,统计学容忍些许错误的可能性,改以抽样资料推算真实的大概样貌。
样本回归直线因此诞生:

回归式中的「残差( Residual )」描述「观察资料Yi 」与「配适结果Yi-hat 」的差异,残差越小,代表模型的配适越接近观察资料,假如可证明观察资料之于真实情况具有代表性,就可利用配适结果对真实情况的良好描述进行有用的统计推论。
可以想像,对一个良好模型,其模型残差的期望值E( ei )应该要等于0。
残差的实际用法,改天再讨论,本文仅着重于残差与模型的关系描述。
在一般的直线回归中,残差的假设为:
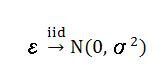
有趣的是,其中残差的常态假设并非必要,虽然假设残差服从常态分配对很多人而言可能是理所当然的…,一些作者直接就把它写成基本假设,虽没有大问题却没交代清楚,其实还是有一点细微差别的。
先来看看为何残差不必要是常态分配?
根据高斯-马可夫定理( Gauss-Markov Theorem ),以「最小平方法( Least Squares Method )」计算线性回归参数b0 、 bi将有「最佳线性不偏估计量( BLUE , Best Linear Unbiased Estimator )」性质的前提,要求残差符合以下条件:
1. 残差期望值为0 。
2. 残差具有同质变异,变异数为一固定常数。
3.残差间没有自相关( Autocorrelation )。
4.自变数与残差无关,即「正交性( Orthogonality )」。
发现了吗?最小平方法下的残差其实是不需要常态假设的。关于回归系数的最小平方估计,可参阅《一场关于猜的魔术:统计估计的形成》。

统计回归分析与常态分配的关系
回到回归分析的主题上,针对残差假设为常态分配的意义有三:
第一,回归是需要相对大样本才较有意义的方法,特别是多元变数的复回归,对样本的需求量很大,很自然会符合中央极限定理。实务上,笔者会建议300-500 个样本或是更多时才适用。
第二,统计推论常见的Z 、 T 、 Chi-squared 、F基本上都是跟常态的机率分布性质( Normal Distribution )有关,光是有残差,要是无法对残差进行推论也是不够力的。
第三,系数检定用的T 分配及类T 统计量都是对偏离常态不太敏感的统计量,因为它们本身就是常态Z 统计量的近似,因此近似又近似的结果就是,除非是残差真实分配远离常态,不然影响非常有限。在稍大的样本条件下更是如此(理由同第一点)。
那有没有残差不为常态的回归模型范例?
有的,像Logistic回归式就没有残差的假设,因为「根本没有残差」,那是因为推导中代换掉的关系,有机会再来谈。
回到残差的分配对模型的影响上,记得常态分配具有「水平位移」的特性吗?
对模型:
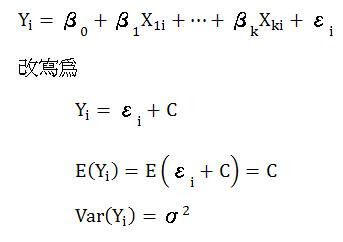
由此可知,当假定残差服从常态分配时,其实也就等于假定Y将服从常态分配,期望值E( Y )= b0 + biX +… bkX ,变异数与残差相同。
应该有人看过教科书这么说:对Y 而言,假设其为常态分配…,理由可以从这里找到。
在回归里,残差变异数的估计量数是MSE ( Mean Squared Error ),因此回归线的变异数也等于MSE ,记得以前做专题还看过一个很烂的翻译叫做「均方差」…,天啊,什么东西?
假如你也被书中一下子说残差变异数、一下子说模型变异数、一下子均方差搞得糊里糊涂,那么现在应该松一口气了,因为都是同一件事。
所以一般说的直线回归究竟是不是常态的方法?
某个程度上视你从什么角度切入。基本上,回归的分配取决于残差的假设,而XY对应关系则决定回归的函数形式。在上述的直线模型中,假如只有一个自变项,通常称为简回归或简单直线回归( Simple Regression ),同时存在多个自变项的情形,称为复回归或多元回归( Multiple Regression ),两者在许多基本性质上可以直接推广,不过在复回归,容易产生因多元变数而起的模型问题,是以在统计教学中通常会将两者分开讨论。
简回归的式子其实就是国中学过的Y = a*X + b ,但在统计上描述得更实务、更精细,直线回归基本特性,可由符号下标看出来:
第一,每一组样本Xi1~Xik 对应到一个应变数Yi (函数基本定义)。
第二,截距项与斜率项在回归配适完成之后就固定住了,因此可以任意代入想观察的自变数组合,或者稍作修正,做资料集外的「预测」,做讨论比较时也很方便…,总之这种一目了然的形式深受分析人员喜爱。
接着来谈谈回归函数的形式吧。
广义线性模型的变化与结构:直线、曲线与非线
如果从自变数「 X 」与应变数「 Y 」的函数反应形状来决定回归的「线性」,那么我们基本上可以得到三个种类:直线、曲线与非线。
但是!对于这几种对应关系的回归称呼,似乎没有一致的标准。
举个例子来说好了,某些作者会用「线性」来表示「直线+曲线」,但问题是曲线在没有充分指定的情况下是非常任意的,也就是所有的对应关系都是广义的曲线,其实直线本身也不过曲率= 0的曲线特例罢了。
另一些作者,用「线性」代表「直线」,非线性代表「广义的曲线」,这个分法本身就有误导之嫌,毕竟线性不等于直线,在书目之前来来去去很容易混为一谈。
至于直线与非直线的区别,曾看过这样的分法:直线回归永远是「一阶式」,只要是「二阶」以上式子基本上就是非直线。但是这个有点可议…,等一下的例子告诉你为什么。

刚开始很令人纳闷,明明就可以清清楚楚划分成三种情形,统计学家何苦老爱用个意义不定的「线性」一词来描述回归…?不过这是有原因的。
到目前为止,本文使用的范例都是「直线」。
不如来看看「非直线」的回归能不能给我们一些线索:

抛物线回归不难懂,是很常见的曲线,但是多项式回归就很复杂了,随着次方项增高,结果可能是一平面、曲面或者无法图像化,总之,对应关系根本就不是线型。你可能会有点意外的是,其实,这两个式子,「曲线」与「不是线」的回归,都是「线性」回归。
关键在于变数转换!
用抛物线回归的例子,只要设新变数X' = X^2 ,再换入原先的公式,不就令「二阶式」变为「一阶式」了吗?有样学样,交互作用以及更高阶项次也都能比照办理。
总之只要回归式表示成「相加式」,不管是怎样的对应关系,曲线或者非线都可以透过代入新变数转成直线。
至于「相乘式」的回归…,没错,还是线性回归。不过转换的方式不一样。
我们曾在《 Data Transformation的一些探讨》中看过这个公式:
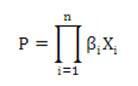

是的,该式加入残差项就成为「相乘式」的回归,转换后的e' = log( e ) 。
在前面提到的《 Data Transformation的一些探讨》一文中,笔者没有特意以「回归模型」为例的原因是,这个资料变造手法即使在非模型分析,也可能产生不错的作用,当然了,资料转换在回归中是很重要的技巧。
再换个例子,以经济学柯布-道格拉斯生产函数( Cobb-Douglas Production Function )为例并加入残差项如下:
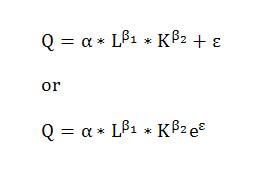
其中Q 代表产出, L 代表劳动力投入, K 代表资本投入。
转换的方式同上,取对数转换:
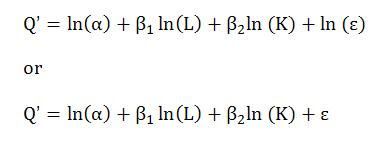
这正是一个标准的线性回归式。
看完「曲线」与「非线」转换成「直线」的过程,相信你也不难理解为何众多统计学家都爱用「线性回归」的名称,因为不管是怎样的函数形式,在统计学家的巧手下,都有办法合理地转成线性关系!
虽然变数转换好不好用有时候见仁见智,但是理论上提供的弹性确实非常强大。
线性这种极强的相容性,提供了一个「超级模型」所需要的基础,你一定在想,有没有可能利用这种性质把各种不同类型的回归模型全都包在同一个理论下来解读呢?
事实上,此模型就名为「广义线性模型( GLM , Generalized Linear Model )」,广泛包纳了ANOVA 、直线回归、多项式回归、Poisson回归、 Logistic回归等等模型,不光反应变数是连续型的回归,反应变数是类别变数的模型也可以用它来解释。
还记得前面提过所有回归的共同组成吗?一个回归模型包含了三个基本元素:
1. 系统成分( Systematic Component )
2. 随机成分( Random Component )
3. 连结函数( Link Function )
这三个元素,就是广义线性模型的结构定义!
广义线性模型从两个方向将常态线性模型扩充到其他模型:
第一,随机成分假设为非常态的其他分配;
第二,将连结函数从直线方程式改为其他函数。
当随机成分Y 不限于常态,那么以类别变数为反应变数的模型就能用同一套概念运作,譬如Y 服从二项分配,那么Y 取値就成为非0 即1 ,而非常态分配的范围负无限大到正无限大之间。甚至计数资料也可以应用上来,譬如Poisson 分配。
连结函数的弹性,则允许GLM 纳入各种不同的对应关系,并利用前述的资料转换技巧,将曲线与非线案例变为直线函数,成为名符其实的「 广义线性模型」。
广义线性模型的常见应用:直线回归、 ANOVA 与卡方检定
对社会科学领域的学生来说,它们三个可能是最广泛学习的方法了,但在我的学习印象中,也是最傻傻搞不清楚的方法。
ANOVA 与卡方,在大学的时候许多老师都会要求学生手动计算,主要的方法就是开表格,对ANOVA 开二维表,对卡方也是开二维表,瞎的地方则是统计量算着算着,怎么两个方法好像都差不多!
后来敎回归,才终于导入模型化的概念,但是这下可惨了,因为已经把卡方检定跟ANOVA 混在一起,我实在无法理解为什么ANOVA =直线回归?
事后想想,这个疑惑某个程度上可归因为没有细分「变数类型」的关系。
统计的资料维度,概分四类:
1. 名目变数或类别变数( Nominal Variable 、 Categorical Variable )
2. 顺序变数( Ordinal Variable )
3. 区间变数( Interval Variable )
4. 比例变数( Proportional Variable )
其中1 、 2 合称「质」变数; 3 、4 称为「量」变数。
对于具有绝对原点的比例资料相信多数人都不陌生,统计上较容易产生问题的是前面三种,譬如顺序变数,喜好分数从1~3 , 1 为最喜欢, 3 为最不喜欢,看起来好像可以直接做加减运算,不过这样会有个隐藏的问题,因为你不晓得分数1 与分数2 的差距是不是等于分数2 到分数3 的差距。
假如不是这样的话,那么运算结果就失真了。若是单位「等距」,顺序变数就会变成「区间变数」。详细内容可参考 UCLA Academic Technology Services的网站,此处有相关说明。
在二维卡方检定当中,行列代表的两个变数都是「类别变数」,内容是运用各类别的次数,检定机率的「独立性」与比例的「同质性」,但对ANOVA 而言,比较的是各组的「平均数」差异,也就是说「组别是类别变数」,但平均数却是「连续变数」。
而直线回归,稍早之前已经解释过,应变数Y 受到残差的影响,服从「常态分配」, Y 是理所当然的「连续变数」,至于X 的变数类型…,前面没提,因为类别变数或顺序变数都适用,比例变数更是不在话下,可说「没什么限制」。
数学里,无限制的状况是很难得的,理由可以从前面「水平位移」与「转直线」的过程找到一点线索。
因为对回归线而言, X 不影响回归的分配谁属,由于有了转直线的方法, X 对Y 的真实函数对应也不太重要了,因此X 只要不与残差有相关,能符合高斯-马可夫定理,除此之外则是很自由的。
如此说来,直线回归与ANOVA 的关系就清楚多了,对仅有1 个预测变数X ,且是「属质」变数的直线回归,根本就是ANOVA 。
从这层关系来看,回归分析的检定报表使用ANOVA Table 实在是再合理不过了。
顺道一提, X为「属质」变数的回归,将会用到「虚拟变数( Dummy Variable )」的变数转换,质对量的分析,不论用ANOVA计算或者跑Dummy回归,结果会一模一样,对于GLM将ANOVA纳入广义线性的家族之中,现在你应该一点都不意外了。
另外要提醒,在其他的回归当中,是有以「类别变数」为应变数Y 的模型,所以这里特别指出「直线回归」。
最后就以一张简化的图示,来说明三者的差异,但是下图的对应式并不保证XY 具有因果关系,这又是另一个大主题了,我们改天再深入讨论。

这么长你都看得完?更多文章等你挑战:
* DATA TRANSFORMATION的一些探讨
* 维度缩减DIMENSION REDUCTION,通往线性代数的圣母峰: 特征值分解(EIGENVALUE DECOMPOSITION)、奇异值分解(SINGULAR VALUE DECOMPOSITION) 与主成份分析(PRINCIPAL COMPONENT ANALYSIS)
* 随机性、大数法则与中央极限定理
* 统计R语言实作笔记系列– 资料尺度与变数类型
* 统计R语言实作笔记系列– 2D视觉化进阶GGPLOT()的基本架构(一)
* 数大有时不美的统计性质