前言:最近买了一个本《分布式过程协同技术详解》,主要讲的是分布式中间服务协调管理中间件,公司采用的是微服务框架dubbo,其中注册中心就是zookeeper.zookeeper作为apche旗下的一款分布式协调中间件,是很多组件的注册中心,比如:HBase、ElasticJob、Hlive,很有必要学习一下,以便于对于分布式技术也有一定的理解。以下主要是国庆期间看书的收货,现在整理出来。
本篇博客的目录
一:分布式遇到的难题
1:配置信息发生变化,假如A\B\C机器组成的集群,此时再加入一台机器D,此时需要改变,就需要停止所有进程,重新分发配置信息的文件,然后重新启动,这中间就会对服务的可用性造成影响
2:负载发生变化,如果增加或者减少新的机器和进程,系统如何选择新的机器负载均衡?如何添加新配置的机器?
3:某一机器或者进程崩溃、宕机?操作系统可以获得这个故障,提供多进程的消息通信保障,而在分布式系统中,其他机器是无法获得这个异常的,因为他们之间的交互此时是断开的(A和B机器组成的集群中,假如A宕机,此时B是无法与A通信的,那么假如任务依然分配到A上就会出现快速失败)
4:通信故障如何解决?当不同的机器位于不同的子网络中,机器如何进行通信?如何保障机器之间传送消息的及时性?
二:zookeeper的基础知识
2.1:zookeeper的基本数据模型
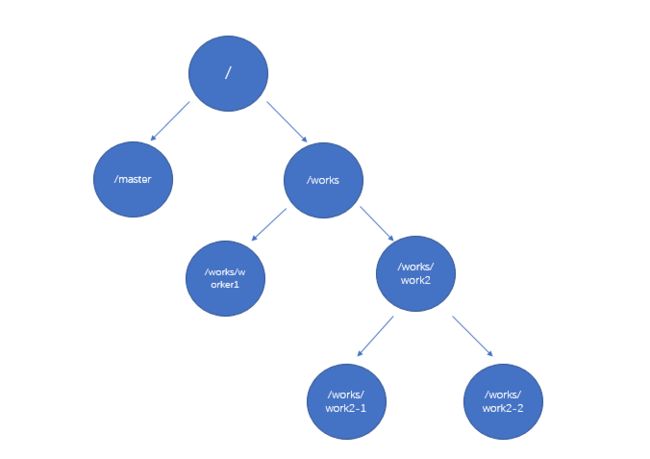
2.1.1:是一个树形结构,类似于文件系统的层级树状结构进行管理,节点互相组成了一个目录
2.1.2:zookeeper的节点称之为znode,它可以有子节点,可以存储数据和不存储数据,不存储数据表示当前还没有选举出主节点。每个zk的节点存储的数据都不会特别大,大概几k左右(数据类型为字节数组)
2.1.3:节点分临时节点和永久节点、有序节点,临时节点在客户端断开后就会消失,永久节点会一直存在,只有用delete命令才能删除。有序节点在被客户端创建以后,就会分配一个序号,并将这个数字增加到路径之后。
2.1.4:每个节点会有自己的版本号,每当节点的数据发生变化,那么该节点的版本号就会累加(乐观锁)
2.1.5:删除、修改节点,版本号不匹配则会报错(类似于乐观锁的机制)
2.1.6:节点可以设置权限acl,可以通过权限来限制用户的访问
2.2:Zookeeper的特性
2.2.1:一致性
数据一致性,数据按照顺序由zk的节点保存和维护,当某一节点的数据发生变化时候,zk会自动将数据同步到其他的节点上(即刻的,同步时间大概在0.5秒之内),类似于mysql的主从同步。某一时刻,客户端访问服务器的时候,各个节点返回的数据一定是一样的。
2.2.2:原子性
事务要么成功要么失败,不会局部化,这点如果知道数据库事务的特性是很好理解的,会有异常回退机制,不会出现数据写入了一半,发生宕机了,而数据依然保留到一半的情况发生,这样很大程度上避免了脏数据对系统的影响。
2.2.3:单一视图性
客户端连接集群中的任一zk节点,数据都是一致的,只会存在一种结果,不会存在不同节点之间的数据程度出不同的状态和属性。单一视图是一致性实现的前提保证。
2.2.4:可靠性
每次对zk的操作状态都会保存在服务端,不会发生操作丢失现象,客户端对服务器发生的改变会立即生效,不会出现延迟。
2.2.5:实时性
客户端随时都可以读取到zk服务端的最新数据,对于服务器的变化,客户端可以立即捕捉到。这依赖于zk的watch与通知原理,当数据发生变化的时候,服务器立即会向客户端推送消息。
2.3:zookeeper常用api和操作指令
zookeeper提供了客户端用于开发人员进行动态操作,主要包含以下几个常用的api:
2.3.1:create /path data 创建一个名为/path的znode节点,并包含数据data。如果想要创建临时节点,create -e
2.3.2:delete /path
删除名为/path的节点,注意此命令可以删除临时节点,也可以删除永久节点。
2.3.3:exists /path 检查是否存在名为/path的节点
2.3.4:setData /path data
设置名为/path的节点数据为data
2.3.5:getData /path
返回名为/path节点的数据信息
2.3.6:getChildren /path
返回所有/path节点所有子节点列表
注意:zokeeper不允许局部写入或读取节点的数据,当设置一个节点的数据或者读取时节点时,内容会被整个替换或者全部都取出来
1:./zkcli.sh 启动客户端进行命令行操作
2:ls和ls2
Ls:查看zk的子目录 ls2:查看节点信息,状态信息
3:get和stat命令
Get:获取当前节点的数据信息 get /path
以下是get命令获取的主要信息:
Czid:节点id ctime:节点创建时间 mzid:修改后的id mtime:修改时间
Pzid:子节点id cverion:子节点的版本 dataVersion:当前节点的版本号
Aclversion:权限版本(权限改变,权限版本会累加1)
Numchildren:子节点的数量
2:检测集群是否配置成功
./zkcli.sh -server [ip]:[port]
三:Zookeeper的作用体现
3.1:master的节点选择,主节点出现错误崩溃或者宕机,从节点就会接手主节点工作,并且master只会有一个,从而保证集群高可用
3.2:统一配置文件管理,只需要配置一台服务器,则可以把相同的配置文件自动同步到其他服务器
3.3:发布与订阅,dubbo发布者把数据存在znode上,订阅者会读取这个数据
3.4:提供分布式锁,分布式环境中不同进程之间争夺资源,类似于多线程中的锁
3.5:集群管理,可以保证数据的强一致性,会自动同步到其他节点
四:zookeeper的监视与通知机制
为了不采用轮询这种耗费资源的机制。zk通过设置在节点的监视点,当节点数据发生变化时,会通知客户端.
对,每个节点操作的时候客户端传送通知,然后再对节点进行变更。你可以设置不同的类型的通知,这个取决于监视点对应的通知类型。客户端可以设置多种监视点,比如监控节点的数据变化,监控子节点的变化,监控节点的创建或者删除。以下是设置节点的,具体流程:
1:客户端设置监视点来监控某一节点数据的变化
2:客户端连接后,向节点添加了一个新的任务
3:客户端接受通知
4:客户端设置新的监视点,在设置完成前,第三个客户端连接后,向节点添加1个新的任务
五:zookeeper的心跳机制和选举制度
心跳机制:客户端定时发送是否存活的通知,每隔5秒ping节点,如果客户端没有及时发送通知,那么属于这个客户端的临时状态的数据全部被删除
选举制度:主节点宕机之后,从节点开始竞争,只有一个节点会胜出,最后成为主节点。注意:当宕机的主节点恢复后,它会成为从节点,而不会成为主节点! zookeeper的主从结构中,主节点负责跟踪从节点状态和任务的有效性,并分配到从节点,它自己本身不执行任务!

六:Zookeeper的分布式锁
访问资源,首先判断锁是否被占用,如果没有被占用,创建zk临时节点,名字叫xxxLock(线程会获得分布式锁),那么其他线程就不会被占用该锁,zookeeper会自动删除节点(countdownLatch),释放锁。如果被占用,当前线程会挂起等待释放锁
七:dubbo与zookeeper
dubbo可以有很多注册中心,zookeeper提供了高度可用和一致性的注册中心,当dubbo的服务应用启动的时候会向zk注册自己的服务,zk会根据服务的ip和id创建节点。当消费者应用启动的时候,会向注册中心进行订阅服务者,注册中心会返回注册服务的列表,而消费者此时会经过dubbo提供的负载均衡算法选择出一个服务提供消费者使用,如果某一节点的服务宕机了,zk内部会经过选举制度,由master节点进行分配服务(由于cap理论,此时zk会出现的暂短的不可用)。如果提供者服务发生变化,dubbo会以长连接的方式向消费者推送变化的数据,保障了服务变化的时候的响应的及时性。

八:cap理论
分布式环境中存在这样的一个概念,cap理论:
Consistency:一致性
Availability:可用性
Paritiontolerance:分区容错性
这三种特性在分布式服务中,只可能满足其中的两种,任何一种分布式不可能三种同时满足。zookeeper是CP的,为什么它不能保障可用性呢?这是因为zk的选举制度,在某一节点宕机的时候,zk内部会通过FastLeaderElection进行选举投票,其中包含到投票措施,自己投票与接收别的服务器投票,投票统计、变更投票等一系列方案进行选举,那么这其中就会存在时间消耗,在投票过程中,zk会出现的短暂不可用。而Eourka(Springcloud的注册中心)在cap理论中是AP的,它因为没有选举制度,所有的节点是均等的,不存在master和slaver,在发生某一节点宕机的时候,不需要选举,只需要平滑的过渡到其他节点。