前一段时间写了一篇文章《凌晨1点突发致命生产事故,人工多线程来破局!》,只是一篇生产事故的记实文章,没想到在圈内流传甚广,其中有程序员对其中的细节有点疑惑,刚好国庆可以和大家再进一步探讨一下。
现在技术圈有一个不太好的现象,经常看到这样一个现象,当出现稍微热门一点的文章的时候,总会出现两级分化的现象,一拨人会反馈牛逼写得太好了,然后另一拨人总是反馈又开始吹牛逼了,各种无脑质疑。
个人认为两个现象其实都不太客观,一篇文章的出现只是作者本人对于技术的阐述,难免有自身的局限,同样既然能写文章必然也不会是瞎乱吹牛逼,那毕竟也有同事朋友都认识,后面还要在这个行业混。
既然文章肯定具有它的局限性,如果写出来读者可以给出一些更好的建议,这样对于写文章的人也是一种学习,我经常从读者的留言中学到了很多知识,这是一种正反馈。
现在的问题是很多技术人把抬杠当作了一种本事,用以展示自己的优越感,如果能说到点子上也还好,关键是有的留言你一看就可以发现,技术涵养太低了明显是不懂行的情况。
这篇文章发出来后,公众号的用户反馈还可以,因为大家对我有个基本认识,在博客园和开源中国中,部分技术朋友质疑比较多的地方给予解释一下:
问题 1:“几百万商户、几千个代理商”,“上千多张表,关系极为复杂”,“在生产环境找十台服务器”至少也得是淘宝,京东这个级别的电商网站才能有这个规模了吧!
回复:淘宝、京东到底有多少商户我还真不太清楚,所以不敢妄言,但请不要轻易低估一家排名靠前的第三方支付公司的数据量,由于历史堆积、外放通道等各种原因,这点数据还是有的。
至于在生产环境找十台服务器,这种操作应该是随随便便的一个中型互联网公司都能搞定的,之前公司至少用了 300-400 太服务器,从中找个10台不是啥问题。
问题2 :吹什么牛逼,难道贵公司是淘宝,拼多多?淘宝也就几百万商户,还日均 40 亿的交易量,用 Spring Cloud 几百个微服务撑不起这么大的体量。
回复:淘宝也就几百万商户这个数据准确吗?包含个体小微商户?
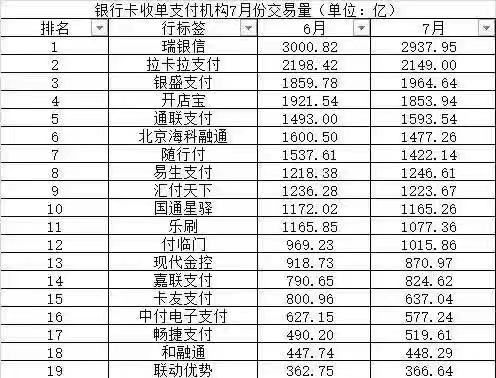
日均 40 亿的交易额在线下收单这个行业这不算高,下面这张是网传收单机构2019年7月交易量排名截图,排名第 10 就已经不止这个交易量了。
用 Spring Cloud 几百个微服务撑不起这么大的体量这个问题,就明显是一个外行得不能再外行的问题了,我就姑且不说有多少成功案例了,就这种评估方式就是低级的。
没有说哪个技术可以支持多少体量或者不能支持多少体量,要评估这个问题,需要看是什么样的团队在什么样的场景以什么样的方式来使用次技术。技术本身并不能决定能支撑多大体量,最重要的是看你怎么用它。
问题3:我怎么看这是数据库工程师的工作,为什么需要写程序迁移呢?
这一看就是技术小白了,从一个非常老的系统迁移到一个完全的新系统,这其中的业务变化、逻辑变化有多少?如果能让 DBA 直接迁移的话,那这个系统有多简单?
且不说这个系统涉及尽千张表,以前老系统的架构和新系统的架构差别有多大, 最重要的是这个新系统后面还跟了一个大数据平台,大数据平台需要根据新系统的 Binlog 日志,做相关数据的逻辑操作。
所以从读者提问本身来讲,就能看出根本不明白这个难点在哪里。
问题4:为什么不建一个和生产 1:1 的环境来模拟测试呢?
一般情况下研发会有四个环境来测试:
- DEV 开发环境,研发人员开发完成自行测试环境。
- SIT 集成测试环境,将自己项目上传到 sit 一般就进入测试部测试阶段了,整体集成测试。
- UAT 客户集成测试环境,一般可以做外部合作商对接的准生产环境,要尽可能的和生产环境保持一致。
- PRO 生产环境,这个大家都清楚,就是真正项目要运行的环境。
读者说的1:1 环境,应该就是需要 UAT 和 PRO 的环境尽可能的保持一致,这是一个比较理想的情况,估计只有部分有钱的互联网公司可以真正实现。
我们做一个中型的互联网公司,每年在 IDC 上面的花费大概在几千万,如果要完全 1:1 的模拟生产环境,每年的花费大概在1000万以上,中型互联网公司很难说服老板去干这件事情。
问题5 :更别提都啥时代了还 servlet,从描述的技术方案和处理流程来看,基本属于作坊式的阶段,一个程序员写一个接口就能做日均几十亿交易的系统迁移了,呵呵。
使用 Servlet 一点都不过时,现在企业级开发90%的公司都使用的是 Spring MVC 吧,Spring MVC 就是 Servlet 包装出来了,很过时吗?
至于属不属于作坊式的阶段我不反驳,流程上肯定是有缺陷的这个我认可,但并不是一个程序员写一个接口做几十亿的系统迁移,如果真的是这样那还需要留 20 号的人在这里干嘛。
这么大级别的数据迁移肯定是一个系统性的工程,并不是1、2个程序员可以负责的,但是迁移程序的发起入口用 1、2 程序员负责足以,中间需要调用 N 个系统的接口配合来完成整体的工作。
问题6 :我觉得这个错误犯得很低级 日数据量达到几十亿次的应用 居然没考虑到数据量过大迁移耗时太长的问题?平时小项目写个定时器都会考虑会不会执行时间过长导致,第一次还没执行完就执行第二次,你们面对千亿的数据量居然没有考虑这个问题?
这个问题中有一个错误,交易额是日几十亿而不是交易量几十亿次,订单量远远没有到达这个量级。数据迁移当然考虑了迁移时间,在整个项目迁移之前其实已经进行过很多次的小规模迁移了,并不是第一次迁移,这个文章中也说明了,这个提问者明显没有看完就来喷了。
这个迁移程序在干这次大活之前,其实已经经历多次考验了,所以从某种程度上来讲这次出问题,轻视也是问题发生的原因之一。
不但已经多次使用,在正式迁移之前也安排进行了多次的验证,只是做为管理者没有和程序员一起深入排查部分细节,存在部分管理失职。
另外有的读者说为什么不使用多线程,我强调一下整个迁移项目使用了多线程,并且还不是仅仅一个多线程,只是程序的最外层没有使用多线程,也就是我们后面的补救方案。
其实还有很多问题,这里不再一一回应,有的提问真的是太低级,感觉都不应该是一个程序员提出的问题。
不过还是有一些读者会对这种大规模迁移有所了解,这其中涉及的细节简直不要太多,任何一个小的忽略都有可能导致大的问题,这种事情没有办法在文中一一举例出来。
不过我觉得有一位读者的回复我比较认可:
那些说风凉话的肯定没有做过上千张表新老系统的迁移,还数据库中间件对接,呵呵
最后,还是那句话:保持技术人的那颗初心,一切以解决实际问题为主。