一、定义
在一幅加权有向图中,最短路径是指从顶点s到顶点t的最短路径是所有从s到t的路径中的权重最小者。
求解最短路径通常需要考虑以下情况:
- 路径是有向的;
- 并不是所有顶点都是可达的;
- 可能出现负权边;
- 最短路径可能并不唯一;
- 可能出现环或平行边;
- 可能出现负权环,这种情况下,最短路径问题没有意义。
二、单源最短路径算法
2.1 理论基础
单源最短路径:即给定一幅加权有向图和一个起点s,回答“从s到给定目的顶点v是否存在一条有向路径?如果有,找出最短的那条路径。”
单源最短路径问题的求解结果是一棵最短路径树(SPT)。

API定义:
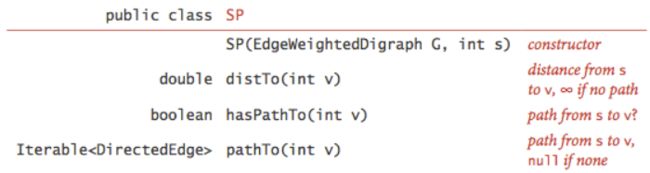
数据结构定义:
distTo[]:保存各个顶点已知的到源点s的最短路径,初始时为正无穷大;
edgeTo[]:保存各个顶点在最短路径上的父路径,如edgeTo[v]表示源点s->v的最短路径上的最后一条路径。
边松弛:
定义:假定源点为s,松弛边v->w,意味着检查s->w的最短路径是否是先从s->v,再从v->w,即判断 PATH(s,w) > PATH(s,v) + PATH(v,w)是否成立?
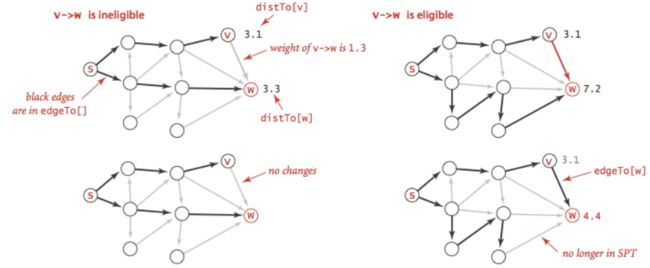
边松弛-源码:
private void relax(DirectedEdge e) {
int v = e.from(), w = e.to();
if (distTo[w] > distTo[v] + e.weight()) {
distTo[w] = distTo[v] + e.weight();
edgeTo[w] = e;
}
}
顶点松弛:
定义:顶点松弛就是边松弛的通用情况。在边松弛中,假定源点为s,松弛边为v->w;而在顶点松弛中,松弛边为顶点v的所有出边。
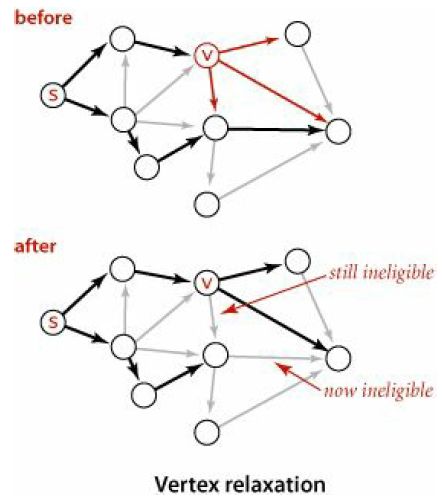
顶点松弛-源码:
private void relax(EdgeWeightedDigraph G, int v) {
for (DirectedEdge e : G.adj(v)) {
int w = e.to();
if (distTo[w] > distTo[v] + e.weight()) {
distTo[w] = distTo[v] + e.weight();
edgeTo[w] = e;
}
}
}
2.2 最短路径的最优性条件
令G是一幅加权有向图,顶点s是G中的起点,distTo[]表示各个顶点到源点的已知最短路径。
对于从s不可达的顶点v,distTo[v]的值为无穷大,则,当且仅当dist[w] ≤ distTo[v] + PATH(v,w)时,dist[w]为s->w的最短路径。
因此,无论一种算法会如何计算distTo[],都只需要遍历图中的所有边一遍并检查最优性条件是否满足,就能知道数组中的值是否就是该顶点到源点的最短路径长度。
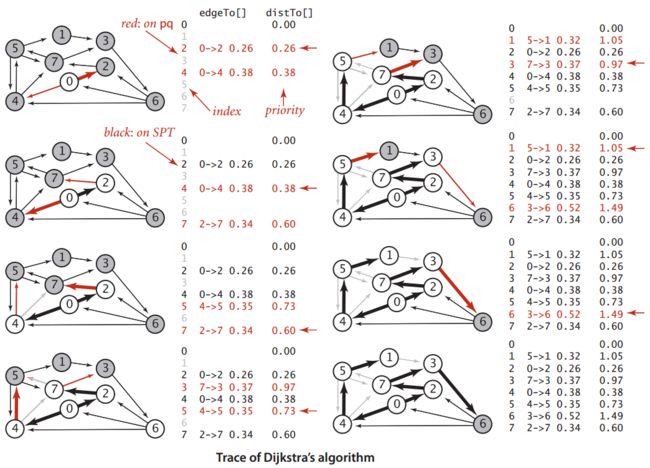
2.3 Dijkstra算法
Dijkstra算法是针对单源最短路径的算法,仅适合求解不含负权边的加权有向图。(用于从指定源点s开始,求解源点s到其余所有顶点的最短路径)
算法步骤:
该算法每次添加离源点最近的顶点到路径树中:
- 初始时,将源点s加入索引优先队列,
distTo[i]:保存顶点i到源点s的当前已知最短路径,初始时为正无穷大;
edgeTo[v]:保存各个顶点在最短路径上的父路径,如edgeTo[v]表示源点s->v的最短路径上的最后一条路径。 - 从队列中取出并删除一个最小顶点v(相当于查找当前离源点s最近的顶点),对该顶点进行松弛操作:
如果松弛成功,即找到一个邻点w满足:PATH(s,w) > PATH(s,v) + PATH(v,w),则更新PATH(s,w) = PATH(s,v) + PATH(v,w),并将w加入索引优先队列。 - 重复第2步,直到队列为空,最终
distTo[]数组中的值就是源点到所有顶点的最短路径。
源码实现:
public class DijkstraSP {
// distTo[v]保存顶点v到源点s的最短路径,初始时,distTo[s]=0,其它为无穷大
private double[] distTo;
// edgeTo[v]保存指向顶点v的最短路径,即s->v的路径上的最后一条路径
private DirectedEdge[] edgeTo;
// 索引优先队列,以顶点v为索引,distTo[v]为值,每次取出最小的进行顶点松弛
private IndexMinPQ pq;
public DijkstraSP(EdgeWeightedDigraph G, int s) {
distTo = new double[G.V()];
edgeTo = new DirectedEdge[G.V()];
for (int v = 0; v < G.V(); v++)
distTo[v] = Double.POSITIVE_INFINITY;
distTo[s] = 0.0;
// relax vertices in order of distance from s
pq = new IndexMinPQ(G.V());
pq.insert(s, distTo[s]);
while (!pq.isEmpty()) {
int v = pq.delMin();
for (DirectedEdge e : G.adj(v))
relax(e);
}
}
//边松弛
private void relax(DirectedEdge e) {
int v = e.from(), w = e.to();
if (distTo[w] > distTo[v] + e.weight()) {
distTo[w] = distTo[v] + e.weight();
edgeTo[w] = e;
if (pq.contains(w))
pq.decreaseKey(w, distTo[w]);
else
pq.insert(w, distTo[w]);
}
}
/**
* 源点到顶点v的最短路径值
*/
public double distTo(int v) {
return distTo[v];
}
public boolean hasPathTo(int v) {
return distTo[v] < Double.POSITIVE_INFINITY;
}
/**
* 源点到顶点v的最短路径
*/
public Iterable pathTo(int v) {
validateVertex(v);
if (!hasPathTo(v))
return null;
Stack path = new Stack();
for (DirectedEdge e = edgeTo[v]; e != null; e = edgeTo[e.from()]) {
path.push(e);
}
return path;
}
public static void main(String[] args) {
In in = new In(args[0]);
EdgeWeightedDigraph G = new EdgeWeightedDigraph(in);
int s = Integer.parseInt(args[1]);
// 计算从源点s开始的最短路径树
DijkstraSP sp = new DijkstraSP(G, s);
for (int t = 0; t < G.V(); t++) {
if (sp.hasPathTo(t)) {
StdOut.printf("%d to %d (%.2f) ", s, t, sp.distTo(t));
for (DirectedEdge e : sp.pathTo(t)) {
StdOut.print(e + " ");
}
StdOut.println();
} else {
StdOut.printf("%d to %d no path\n", s, t);
}
}
}
}
性能分析:
时间复杂度:O(ElgV)
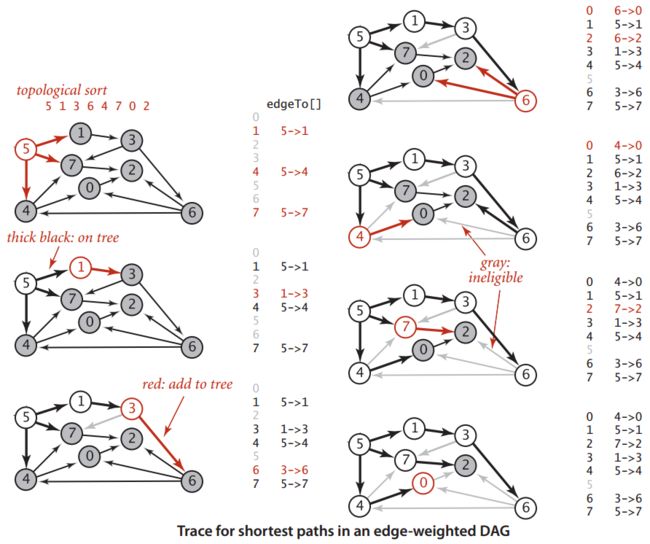
2.4 基于拓扑排序的最短路径算法
基于拓扑排序的最短路径算法的基本步骤如下:
- 对于一幅加权有向无环图(DAG),进行拓扑排序,得到一个拓扑序列;
- 按照拓扑序列,依次对顶点进行松弛。
算法特点:
- 能够在线性时间内解决单源最短路径问题;
- 能够处理负权边;
- 由于是基于拓扑排序,所以必须是无环图
源码实现:
public class AcyclicSP {
// distTo[v]保存顶点v到源点s的最短路径,初始时,distTo[s]=0,其它为无穷大
private double[] distTo;
// edgeTo[v]保存指向顶点v的最短路径,即s->v的路径上的最后一条路径
private DirectedEdge[] edgeTo;
public AcyclicSP(EdgeWeightedDigraph G, int s) {
distTo = new double[G.V()];
edgeTo = new DirectedEdge[G.V()];
for (int v = 0; v < G.V(); v++)
distTo[v] = Double.POSITIVE_INFINITY;
distTo[s] = 0.0;
// 对原图进行拓扑排序
Topological topological = new Topological(G);
if (!topological.hasCycle())
throw new IllegalArgumentException("Digraph is not acyclic.");
// 按照拓扑序列,依次松弛顶点的每条出边
for (int v : topological.order()) {
for (DirectedEdge e : G.adj(v))
relax(e);
}
}
// relax edge e
private void relax(DirectedEdge e) {
int v = e.from(), w = e.to();
if (distTo[w] > distTo[v] + e.weight()) {
distTo[w] = distTo[v] + e.weight();
edgeTo[w] = e;
}
}
public double distTo(int v) {
return distTo[v];
}
public boolean hasPathTo(int v) {
validateVertex(v);
return distTo[v] < Double.POSITIVE_INFINITY;
}
public Iterable pathTo(int v) {
validateVertex(v);
if (!hasPathTo(v))
return null;
Stack path = new Stack();
for (DirectedEdge e = edgeTo[v]; e != null; e = edgeTo[e.from()]) {
path.push(e);
}
return path;
}
public static void main(String[] args) {
In in = new In(args[0]);
int s = Integer.parseInt(args[1]);
EdgeWeightedDigraph G = new EdgeWeightedDigraph(in);
// find shortest path from s to each other vertex in DAG
AcyclicSP sp = new AcyclicSP(G, s);
for (int v = 0; v < G.V(); v++) {
if (sp.hasPathTo(v)) {
StdOut.printf("%d to %d (%.2f) ", s, v, sp.distTo(v));
for (DirectedEdge e : sp.pathTo(v)) {
StdOut.print(e + " ");
}
StdOut.println();
} else {
StdOut.printf("%d to %d no path\n", s, v);
}
}
}
}
性能分析:
时间复杂度:O(E+V)
2.5 Bellman-Ford 算法
Bellman-Ford算法的前提条件是:从源点s出发,s到任意负权环的顶点都是不可达的(否则,最短路径问题没有意义)。
算法思想:
Bellman-Ford 算法的基本思想是,对于V个顶点的图,每次对所有边进行松弛,每松弛1次,就得到从源点出发路径长度为k的顶点的最短路径,最多松弛V-1次就可以得到所有顶点的最短路径。
为什么最多是需要V-1次松弛?
因为V个顶点形成一棵最短路径树,根据树定理,V个顶点的树只有V-1条边,所以任意两个顶点之间的最短路径长度最多是V-1。
算法步骤:
在任意含有V个顶点的加权有向图中,给定源点s(从s无法到达任何负权重环):
- 初始时,除了
dist[s]=0以外,其余皆为无穷大; - 从源点s出发,每次都对图中的所有边进行“松弛”:
第1轮“松弛”后,得到从源点出发,只经过1条边到达其余各顶点的最短路径;
第2轮“松弛”后,得到从源点出发,只经过2条边到达其余各顶点的最短路径;
…
第k轮“松弛”后,得到从源点出发,只经过k条边到达其余各顶点的最短路径; - 对于一个有V个顶点的图来说,任意两个顶点之间的最短路径最多只有V-1条边。
故最多经过V-1轮,即可得到源点到各个顶点的最短路径。
源码描述如下:
for (int n = 1; n <= G.V()-1; n++)
for (int v = 0; v < G.V(); v++)
for (DirectedEdge e : G.adj(v))
relax(e);
注:负权回路的检测
Bellman-Ford 算法适用的有向图中,不能出现负权回路。
在不含负权回路是情况下,经过V-1次松弛后,各个顶点的最短路径不会发生变化。
所以为了检测负权回路,可以在V-1次松弛后,再补充1次松弛,如果松弛后,某个顶点的最短路径发生变化,说明存在负权回路。
2.6 基于队列的Bellman-Ford算法(SPFA算法)
优化思路:
SPFA算法是对Bellman-Ford算法的优化,在Bellman-Ford算法中,每次松弛后,有些顶点已经求得了最短路径,此后这些顶点的最短路径会一直保持不变,不再受后续松弛的影响。
所以,可以每次松弛时,仅对上一次松弛时最短路径发生了变化的顶点进行松弛,具体步骤如下:
- 用一个队列保存所有待松弛的顶点,初始时只有源点s;
- 每次出队一个顶点v,对其所有出边进行松弛;如果存在某条v->w的边松弛成功(满足
PATH(s,w) > PATH(s,v) + PATH(v,w)),则将w加入队列(假设w原来在不队列中)。
注意:w必须是不在队列中,否则可能重复添加相同顶点,所以需要用一个boolean数组标识某个顶点是否已经在队列中。 - 重复步骤2,直到队列为空或发现负权环。
如何判断图中是否存在负权回路?
如果不存在从起点s可达的负权回路,那么算法终止的条件将是队列为空;
如果存在呢?队列永远不会空(又在兜圈子了)!
这意味着程序永不会结束,为此,我们必须判断从s可达的路径中是否存在负权回路。
两种判断方法:
①根据前面的算法思想我们只知道,Bellman-Ford算法最多需要进行V-1次松弛。所以对于任意一个顶点,每进入一次队列,意味着需要进行一次松弛,所以如果某个顶点进入队列的次数超过V,说明存在负权环。
②周期性检测,每当边的松弛次数达到一个指定值,就进行一次检测(如下源码)。
基于队列的Bellman-Ford算法(SPFA算法)源码:
public class BellmanFordSP {
// distTo[v]保存顶点v到源点s的最短路径,初始时,distTo[s]=0,其它为无穷大
private double[] distTo;
// edgeTo[v]保存指向顶点v的最短路径,即s->v的路径上的最后一条路径
private DirectedEdge[] edgeTo;
// 标识顶点v是否已经在待松弛队列中
private boolean[] onQueue;
// 待松弛队列,保存所有待松弛的顶点
private Queue queue;
// 记录边的松弛总次数
private int cost;
// 保存负权环
private Iterable cycle;
public BellmanFordSP(EdgeWeightedDigraph G, int s) {
distTo = new double[G.V()];
edgeTo = new DirectedEdge[G.V()];
onQueue = new boolean[G.V()];
for (int v = 0; v < G.V(); v++)
distTo[v] = Double.POSITIVE_INFINITY;
distTo[s] = 0.0;
queue = new Queue();
queue.enqueue(s);
onQueue[s] = true;
while (!queue.isEmpty() && !hasNegativeCycle()) {
int v = queue.dequeue();
onQueue[v] = false;
relax(G, v);
}
}
// relax vertex v and put other endpoints on queue if changed
private void relax(EdgeWeightedDigraph G, int v) {
for (DirectedEdge e : G.adj(v)) {
int w = e.to();
if (distTo[w] > distTo[v] + e.weight()) {
distTo[w] = distTo[v] + e.weight();
edgeTo[w] = e;
if (!onQueue[w]) {
queue.enqueue(w);
onQueue[w] = true;
}
}
// 每间隔一段时间,就检查一次属否出现负环。
// 这里的间隔定为顶点总数的倍数
if (cost++ % G.V() == 0) {
findNegativeCycle();
if (hasNegativeCycle())// found a negative cycle
return;
}
}
}
public boolean hasNegativeCycle() {
return cycle != null;
}
public Iterable negativeCycle() {
return cycle;
}
/**
* 查找负权环
* 先根据当前已知的最短路径,生成一幅图 然后通过DFS判断是否有总权值为负的环
*/
private void findNegativeCycle() {
int V = edgeTo.length;
EdgeWeightedDigraph spt = new EdgeWeightedDigraph(V);
for (int v = 0; v < V; v++)
if (edgeTo[v] != null)
spt.addEdge(edgeTo[v]);
EdgeWeightedDirectedCycle finder = new EdgeWeightedDirectedCycle(spt);
cycle = finder.cycle();
}
public double distTo(int v) {
if (hasNegativeCycle())
throw new UnsupportedOperationException("Negative cost cycle exists");
return distTo[v];
}
public boolean hasPathTo(int v) {
return distTo[v] < Double.POSITIVE_INFINITY;
}
public Iterable pathTo(int v) {
if (hasNegativeCycle())
throw new UnsupportedOperationException("Negative cost cycle exists");
if (!hasPathTo(v))
return null;
Stack path = new Stack();
for (DirectedEdge e = edgeTo[v]; e != null; e = edgeTo[e.from()]) {
path.push(e);
}
return path;
}
public static void main(String[] args) {
In in = new In(args[0]);
int s = Integer.parseInt(args[1]);
EdgeWeightedDigraph G = new EdgeWeightedDigraph(in);
BellmanFordSP sp = new BellmanFordSP(G, s);
// print negative cycle
if (sp.hasNegativeCycle()) {
for (DirectedEdge e : sp.negativeCycle())
StdOut.println(e);
}
// print shortest paths
else {
for (int v = 0; v < G.V(); v++) {
if (sp.hasPathTo(v)) {
StdOut.printf("%d to %d (%5.2f) ", s, v, sp.distTo(v));
for (DirectedEdge e : sp.pathTo(v)) {
StdOut.print(e + " ");
}
StdOut.println();
} else {
StdOut.printf("%d to %d no path\n", s, v);
}
}
}
}
}
性能分析:
- 时间复杂度
平均情况:O(E+V)
最坏情况:O(EV)
三、多源最短路径算法
3.1 Floyd-Warshall算法
算法思想:
基于“动态规划”思想,对于一幅加权有向图中的任意两个顶点I,J:
- 如果两个顶点之间没有其它顶点,则最短路径就是两个顶点之间的距离;
- 如果两个顶点之间只有1个顶点,则当
PATH(I,J) > PATH(I,k) + PATH(k,J)时,说明顶点k使得i,j之间距离变短了,则更新PATH(I,J) = PATH(I,k) + PATH(I,J); - 如果两个顶点之间只有2个顶点,则对这两个顶点分别判断
PATH(I,J) > PATH(I,k) + PATH(k,J);
… - 如果两个顶点之间只有k个顶点,则对这k个顶点分别判断
PATH(I,J) > PATH(I,k) + PATH(k,J);
源码实现:
for (int k = 0; k < n; k++) {
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
if (e[i][j] > e[i][k] + e[k][j])
e[i][j] = e[i][k] + e[k][j];
}
}
}
性能分析:
- 时间复杂度
O(V3)
四、各类最短路径算法比较
| \ | Dijkstra算法 | Bellman-Ford算法 | SPFA算法(基于优先队列的Bellman-Ford) | Floyd-Warshall算法 | 基于拓扑排序的最短路径算法 |
|---|---|---|---|---|---|
| 时间复杂度 | O(ElgV) | O(EV) | 平均:O(E+V) 最坏:O(EV) |
O(V3) | O(E+V) |
| 算法特点 | 1.稠密图(邻接矩阵); 2.和顶点关系密切; 3.解决单源最短路径问题 |
1.稀疏图(邻接表); 2.和边关系密切; 3.解决单源最短路径问题; 4.查找负权环 |
1.稀疏图(邻接表); 2.和边关系密切; 3.解决单源最短路径问题; 4.查找负权环 |
1.稠密图(邻接矩阵); 2.和顶点关系密切; 3.解决多源最短路径问题 |
1.解决单源最短路径问题 |
| 负权边/环 | 1.不能解决负权边; 2.可有环 |
1.可以解决负权边; 2.可有环 |
1.可以解决负权边; 2.可有环 |
1.可以解决负权边; 2.可有环 |
1.可以解决负权边; 2.不能有环 |