前言
由于某次在某个微信群里跟大家聊到,感觉这几年这个群的聊天话题变化真的很明显,再加上自己微信记录几乎都没删掉的时候(对,po主本质上是个仓鼠,信息都是无价的),就提到了可以拿出来做一下分析,然后就产生了这篇文章/教程。
btw 大家也请不要拿这个去做坏事情,并且这里也事先声明,很多微信中涉及的ID什么的大家尽可能不要透露给陌生人,虽然微信没有给出更多的API,但ID本身毕竟还是比名字还可靠地。
这篇文章只是给大家一点小的尝试,通过学习这篇文章的话,大家应该可以学会如何拿到微信记录,并且大概了解了微信记录是怎么储存的,并且了解时间戳与如何对时间序列的数据进行resample,从而获得不同时间间隔的数据。并分时间段的去生成词云。 大概像这样,因为微信记录太多个人信息了,我就放了个高糊的图了

然后文本分析绝对不仅仅这么点东西,大家可以继续挖掘,甚至可以做主题分析,或者进行词语偏好的分析,甚至可以作为定制化的聊天机器人的训练材料,反正只有想不到,没有做不到啦(:з」∠),欢迎大家多玩蛇共同学习python。
大纲
正如把大象放进冰箱只需要三步一样,那么利用微信聊天记录也只有三步
- 导出聊天记录
- IOS系统
- 解析导出文件
- python
- 画图
- plotly + amueller/word_cloud
(python module)
- plotly + amueller/word_cloud
正文
那么利用微信记录的话,我们肯定就很难在手机/平板上进行操作,毕竟又要越狱或者安装语言,就很麻烦,而且手机上的目录结构也比较复杂,这一点我们直接略过。。。所以我选择了从手机上把聊天记录导出到电脑上,来进行操作。
导出记录
关于导出聊天记录的方法其实有很多。。。(大家请小心使用,避免造成数据丢失以及下了流氓软件)
但是真正能够用来做文本分析的却并不多。。
为什么呢??
就说微信官方的备份与恢复
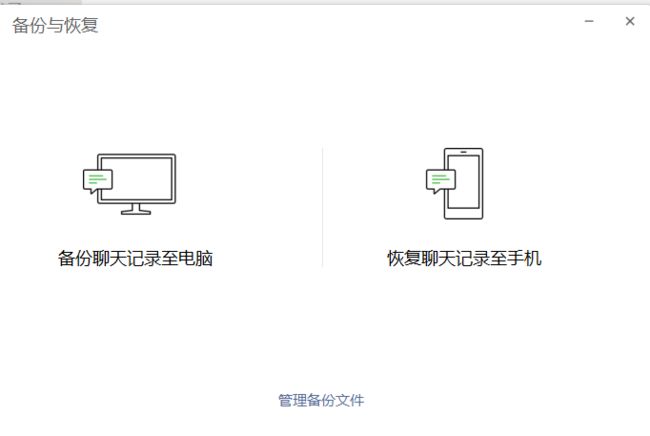
其实最后导出的结果,是一个 加密后的数据库文件,所以单单凭借这个导出的备份,我们几乎无法做文本分析。
而关于使用安卓系统的,网上也很多,但是似乎大多也是要经过复杂的解密操作,而且首先也必须需要进行ROOT,再加上po主也没有安卓手机,这里就放一些网上的教程好了。
- MicromsgHistory github
- 导出微信聊天记录并生成词云
最后终于终于进入这个部分的正题。
简单地说
通过itunes的IOS备份,再加上一个软件wx backup,就可以实现导出微信聊天记录并在电脑上阅读/分析的目的
复杂的操作大家可以详见这个链接,btw现在是win+mac系统都可用这软件的
- 微信聊天记录导出--发布 知乎
最后导出来的文件大概长这样。。。
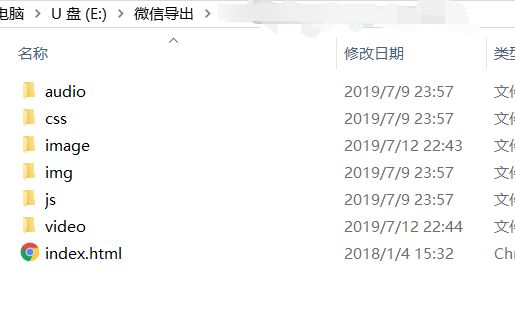
大家直接打开
index.html就可以看到导出的聊天记录,其中也可以看到曾经分享过的照片、视频。(音频似乎没有成功导出来)
而我们要使用的则是
js/message.js
其中也分享一个小技巧,因为现在大家的手机都普遍容量巨大,而大家的电脑可能都是些固态硬盘256G的,所以对于这种无差别IOS备份的操作,很有可能会使电脑容量不足!尤其是itunes这种无法选择备份目录,只能备份到C盘的“流氓”软件。 反正我手机备份下来有60G+
Win7下更改iTunes备份路径最便捷的方法(收藏一下总没错)
这个亲测win10 + win8也都可以啦,简单地说
通过软链接 (快捷方式)的方式,将原本itunes默认使用的备份地址,链接到一个更大空间的可以自定义的地方(例如移动硬盘之类的)
解析导出的聊天记录
由于这里要使用python的代码去解析,所以要求使用的人有一点python的编程能力,当然抄源代码也是没问题的,就是得知道怎么在自己电脑上安装anaconda, ipython之类的软件了。甚至还得知道怎么安装github上的仓库
简单说一下以上步骤好了
- 下载合适自己电脑系统的anaconda
- 按图索骥的安装程序
pip install jieba pandas numpy tqdm(后续要使用的软件)- 还是使用上面提到的app,输入
jupyter lab- 然后就可以开始愉快的代码之旅了。。
只要五步就可以学会使用python,买不了吃亏买不了上当了
message_odir = "D:\\Desktop\\微信导出\\群名+id" # 看导出的文件夹名字
message_path = message_odir + "\\js\\message.js"
data = {}
message = open(message_path,'r',encoding='utf-8').read()
exec(message.replace('var ',''))
由于在js\message.js中,仅仅声明一个变量data,而且这个data中含有类似于python的dict的数据结构,所以我直接使用exec进行执行,并且载入了所有的消息数据到data中
进行ID到名字的转化,毕竟大家都看不懂一个ID,还是看名字比较熟悉一点
# chartroom ID
gID = data["owner"]['user']
gname = data["owner"]['name']
# For chatroom
# get all user ID and its name
members = data["member"]
mid2username = {mid: members[mid]['name'] for mid in members}
mid2username.pop(gID)
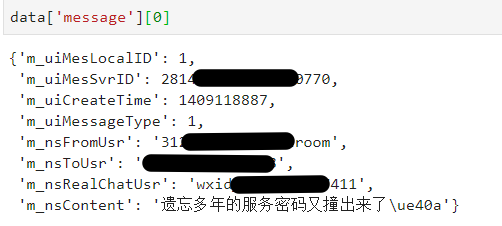
大家可以通过自己的方式,观察这个data中的结构,但以下是一个将这个数据转化为一个方便后续使用的DataFrame的方法,因为后面会涉及到时间的分块,所以我还是将其转为数据框来后续使用
all_messages_df = pd.DataFrame.from_records(data['message'])
all_messages_df.loc[:,'fromWho'] = [mid2username.get(record,'碎碎念达人')
# 碎碎念达人 是po主的用户名
for record in all_messages_df.loc[:,"m_nsRealChatUsr"]]
all_messages_df.loc[:,'datetime'] = [get_time(record)
for record in all_messages_df.loc[:,"m_uiCreateTime"]]
all_messages_df= all_messages_df.loc[:,["fromWho","datetime","m_nsContent"]]
all_messages_df = all_messages_df.set_index("datetime")
上面是基本的数据处理过程,这里再讲一下大家所重点想看的一点。
文本分析在获取数据并清洗数据之后,当然要开始做分词处理(不是必需的一步,但是是重要的一步)
这里使用“结巴”中文分词:做最好的 Python 中文分词组件
作为分词的工具包,使用起来也十分方便,如果实在上述的pd.DataFrame的情况下的话,再结合amueller/word_cloud,只需要以下的一丢丢的代码。
total_seg_word = jieba.lcut(' '.join(all_messages_df.loc[:,'m_nsContent']))
filtered_seg_word = remove_word(total_seg_word) # 非必需的一步,需要自己定义停用词
import wordcloud
txt = ' '.join(filtered_seg_word)
w = wordcloud.WordCloud(font_path = 'msyh.ttc' ,
width = 2000,
height = 1400,
background_color = 'white',
collocations=False,
colormap ='cividis',
max_words =500) #使用微软雅黑字体
w.generate(txt)
w.to_file(message_odir + '\\total.png')
就可以画出一个词云图片来。
形如
关于停用词
由于日常交流的语言中存在大量的无意义、语气、语法助词,所以需要一个词汇表去记录这些词,这个词汇表我们可以称之为停用词表,如果不去除的话,最后生成的词云中会存在大量的。。。。就像下面这个一样 不去除停用词的后果
不去除停用词的后果
关于画图和代码
代码部分我觉得还是jupyter notebook展示会好一点,所以把整个完整的流程包括停用词表都放到github上了。
以下是到那个notebook的链接(部分结果我去掉了output,避免出现个人信息之类的(:з」∠),有意见我也没办法)
note book demo
wechat dig
参考
- python 将微信聊天记录生成词云
- 微信聊天记录导出--发布 知乎
- “结巴”中文分词:做最好的 Python 中文分词组件
- wechat dig
- 动态展示notebook