在已知了树状数组的使用方法,那么便可以用它来解决一些实际问题了,比如说下面一道经典题:敌兵布阵 :HDU:1166。
题目大致意图为:敌方有排好的数个阵营,每个阵营都有一些士兵,且不断有人进出,在某个时刻快速统计阵营号在某个范围内的阵营内人数和。
为了快速统计前n项和且尽量减少统计时间,避免所有的数据遍历,很容易想到树状数组的应用,不但可以以很少的时间更新数组,而且计算和时减少遍历求和时间,假设要求的阵营排号范围为(a,b),那么只需要sum(b)-sum(a-1),即可,我们可以按照此思路很容易地写出相关的代码:
#include
#include
#include
#include
#define lowbit(x) (x&(-x))
#define MMAX 500010
using namespace std;
int m;
int C[MMAX];
int sum(int i)
{
int ans=0;
while (i>0)
{
ans+=C[i];
i-=lowbit(i);
}
return ans;
}
void add(int num,int i)
{
while (i<=m)
{
C[i]+=num;
i+=lowbit(i);
}
}
void main()
{
int i,j,k,n,x,y;
char ch[7];
scanf("%d",&n);
for (j=0;j 该程序在指定的时间范围内,是可以顺利AC的,那么,我们不妨继续寻找更加简便的方法来更快的减少时间。
我们知道,树状数组的结果是前N项的和,那么,正如该题,如果我们要求的是一段范围内的和该怎么办呢?假设范围是(a,b),那么1到a-1的求和我们计算了两遍,而需要使用的却不是这段的和,我们便不由得去想,可否想一个办法让数组直接存储的就是一定范围内的和,这时候需要涉及到的就是线段树。
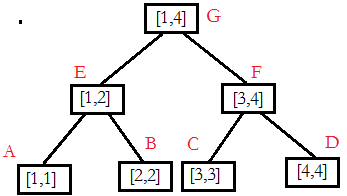
ABCD代表的叶子节点只存储一个元素的和,而EF存储的是两个孩子结点的和E=A+B=1+2,F=C+D=3+4,而G结点存储的也为其两个孩子的和即G=E+F=A+B+C+D=1+2+3+4。
那么,如果想要求(3,4)的和,只需要调出F结点输出即可,如果有一个叶子节点内的数据变动,要做的便是向上迭代,将其双亲结点变动相应的参数,直到树的根结点。
但是如何准确地使用线段树呢?首先需要做的就是深刻理解线段树的原理和性质:
线段树是一种二叉搜索树,与区间树相似,它将一个区间划分成一些单元区间,每个单元区间对应线段树中的一个叶结点。
对于线段树中的每一个非叶子节点[a,b],它的左儿子表示的区间为[a,(a+b)/2],右儿子表示的区间为[(a+b)/2+1,b]。因此线段树是平衡二叉树,最后的子节点数目为N,即整个线段区间的长度。
使用线段树可以快速的查找某一个节点在若干条线段中出现的次数,时间复杂度为O(logN)。而未优化的空间复杂度为2N,因此有时需要离散化让空间压缩。
----来自百度百科
【以下以 求区间最大值为例】
先看声明:
01.#include
02.#include
03.const int MAXNODE = 2097152;
04.const int MAX = 1000003;
05.struct NODE{
06. int value; // 结点对应区间的权值
07. int left,right; // 区间 [left,right]
08.}node[MAXNODE];
09.int father[MAX]; // 每个点(当区间长度为0时,对应一个点)对应的结构体数组下标
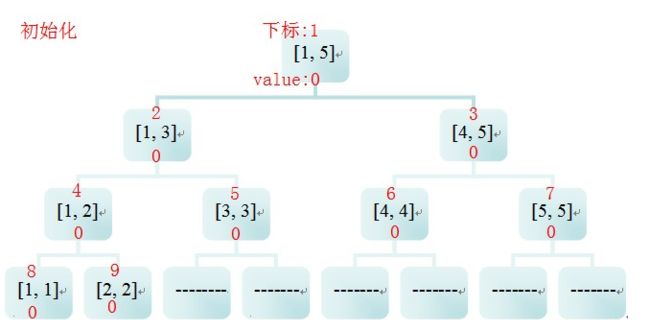
【创建线段树(初始化)】:
由于线段树是用二叉树结构储存的,而且是近乎完全二叉树的,所以在这里我使用了数组来代替链表上图中区间上面的红色数字表示了结构体数组中对应的下标。
在完全二叉树中假如一个结点的序号(数组下标)为 I ,那么 (二叉树基本关系)
I 的父亲为 I/2,
I 的另一个兄弟为 I/2 * 2 或 I/2✲2+1
I 的两个孩子为 I*2 (左) I✲2+1(右)
有了这样的关系之后,我们便能很方便的写出创建线段树的代码了。
01.void BuildTree(int i,int left,int right){ // 为区间[left,right]建立一个以i为祖先的线段树,i为数组下标,我称作结点序号
02. node[i].left = left; // 写入第i个结点中的 左区间
03. node[i].right = right; // 写入第i个结点中的 右区间
04. node[i].value = 0; // 每个区间初始化为 0
05. if (left == right){ // 当区间长度为 0 时,结束递归
06. father[left] = i; // 能知道某个点对应的序号,为了更新的时候从下往上一直到顶
07. return;
08. }
09. // 该结点往 左孩子的方向 继续建立线段树,线段的划分是二分思想,如果写过二分查找的话这里很容易接受
10. // 这里将 区间[left,right] 一分为二了
11. BuildTree(i<<1, left, (int)floor( (right+left) / 2.0));
12. // 该结点往 右孩子的方向 继续建立线段树
13. BuildTree((i<<1) + 1, (int)floor( (right+left) / 2.0) + 1, right);
14.}
【单点更新线段树】:
假设该线段树的作用是找到N个节点的最大值,由于我事先用 father[ ] 数组保存过 每单个结点 对应的下标了,因此我只需要知道第几个点,就能知道这个点在结构体中的位置(即下标)了,这样的话,根据之前已知的基本关系,就只需要直接一路更新上去即可。
01.void UpdataTree(int ri){ // 从下往上更新(注:这个点本身已经在函数外更新过了)
02.
03. if (ri == 1)return; // 向上已经找到了祖先(整个线段树的祖先结点 对应的下标为1)
04. int fi = ri / 2; // ri 的父结点
05. int a = node[fi<<1].value; // 该父结点的两个孩子结点(左)
06. int b = node[(fi<<1)+1].value; // 右 (每个数字按位左移一个单位相当于乘2)
07. node[fi].value = (a > b)?(a):(b); // 更新这个父结点(从两个孩子结点中挑个大的)
08. UpdataTree(ri/2); // 递归更新,由父结点往上找
09.}
//直到更新完毕,根节点中存放的数则是数组中所有的数组的最大数。
【查询区间最大值】:
将一段区间按照建立的线段树从上往下一直拆开,直到存在有完全重合的区间停止。对照图例建立的树,假如查询区间为 [2,5]
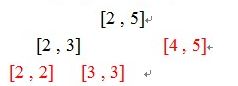
红色的区间为完全重合的区间,因为在这个具体问题中我们只需要比较这 三个区间的值 找出 最大值 即可。
01.int Max = -1<<20;
02.void Query(int i,int l,int r){ // i为区间的序号(对应的区间是最大范围的那个区间,也是第一个图最顶端的区间,一般初始是 1 啦)
03. if (node[i].left == l && node[i].right == r){ // 找到了一个完全重合的区间
04. Max = (Max < node[i].value)?node[i].value:(Max);
05. return ;
06. }
07. i = i << 1; // get the left child of the tree node
08. if (l <= node[i].right){ // 左区间有涉及
09. if (r <= node[i].right) // 全包含于左区间,则查询区间形态不变
10. Query(i, l, r);
11. else // 半包含于左区间,则查询区间拆分,左端点不变,右端点变为左孩子的右区间端点
12. Query(i, l, node[i].right);
13. }
14. i += 1; // right child of the tree
15. if (r >= node[i].left){ // 右区间有涉及
16. if (l >= node[i].left) // 全包含于右区间,则查询区间形态不变
17. Query(i, l, r);
18. else // 半包含于左区间,则查询区间拆分,与上同理
19. Query(i, node[i].left, r);
20. }
21.}
此段算法代码并不好理解,但是,可以根据二叉树的遍历便可以得到大致思路:
首先,从最大的结点:根结点开始遍历,如果目标数据域与根数据相同,那么直接输出的就是跟数据域内的数据,如果不相同,那么一定是小于跟数据域的,可以先判断其在左子树和右子树中是不是有目标数据域内的数。
首先,判断是否在左子树中:将i从代表跟子树的下标1转换为左子树的下标i<<1;然后判断,如果在左子树中有数据,那么一定是从小的数据开始排,有if (node[i].right>=l),如果有,那么判断是否整个数据域都在左子树中:if (node[i].right>=r)如果是,那么就可以递归算法,传参i(左子树坐标),继续从头判断是否目标数据域全部在该结点中……如果不是,那么则说明目标数据域即在左子树中有元素,也在右子树中有,先判断左子树中的元素具体位置,将r置为node[i].right,保证目标数据域都在i结点中,递归,再次调用数据,判断是否目标数据域全部在该结点中……直到找到了左子树中的部分的最大值,那么,右子树中的该怎么办呢?已知找到后,循环将跳出,那么,将i++,得到的下标就是当前子树的兄弟,即右子树了;已知右子树可能有部分的目标数据域内的数据,也可能没有,那么,只要加以判断if (node[i].left<=r),之后的判断与左子树内的处理相似,如果判断为否,退出循环,找到解,若为是,判断是否全部都在该区域中,递归参数i,若为否,递归数据域的左区间将为node[i].left。
此代码运用的环境为求最大值,可以减少比较和遍历时间。
在本题当中,所求的解为一定数据域内的和,便需要找到完全符合的数据域,并将它们的值并入和的值即可。根据题意得出相应代码:
#include
#include
#include
#include
#define MMAX 3000010
using namespace std;
struct
{
int value;
int right,left;
}node[MMAX];
int num[500010];
int sum;
int n;
void build (int i,int l,int r)
{
if (l==r)
{
node[i].right=r;
node[i].left=l;
node[i].value=num[l];
return;
}
node[i].left=l;
node[i].right=r;
build(i*2,l,(l+r)/2);
build(i*2+1,(l+r)/2+1,r);
node[i].value=node[i*2].value+node[i*2+1].value;
}
void add(int i,int l,int r)
{
if (node[i].left==l&&node[i].right==r)
{
sum+=node[i].value;
return;
}
i=i<<1;
if (node[i].right>=l)
{
if (node[i].right>=r)
add(i,l,r);
else
add(i,l,node[i].right);
}
i++;
if (node[i].left<=r)
{
if (node[i].left<=l)
add(i,l,r);
else
add(i,node[i].left,r);
}
}
void update(int i,int shu)
{
int a=1;
while (a<=MMAX)
{
node[a].value+=shu;
if (node[a].right==node[a].left)
break;
if (i<=(node[a].left+node[a].right)/2)
a*=2;
else
a=2*a+1;
}
}
void main()
{
int i,j,k,m,x,y;
char s[12];
scanf("%d",&m);
for (int cas=1;cas<=m;cas++)
{
scanf("%d",&n);
memset(num,0,sizeof(num));
for(i=1;i<=n;i++)
{
scanf("%d",&num[i]);
}
build(1,1,n);
printf("Case %d:\n",cas);
getchar();
while(scanf("%s",s)&&s[0]!='E')
{
sum=0;
scanf("%d%d",&x,&y);
getchar();
if (s[0]=='Q')
{
add(1,x,y);
printf("%d\n",sum);
}
else if (s[0]=='A')
update(x,y);
else if (s[0]=='S')
update(x,-y);
}
}
}
由上面的代码论述可知,实现从根结点到达某个根结点的数据更新,不但可以按照比较左右数据域的大小比较,还可以根据实际情况将其与(node[i].left+node[i].right)/2进行比较来确定目标结点在左子树中还是右子树中。