【python】Knn(K近邻)算法实现原理+代码
【版本】python 3.7 【IDE】IDLE 3.7.4(python3.7 64-bit)(python自带的)
文章里面如果有误可以的话麻烦帮我指出来,提前感谢quq
一、算法介绍
K-NN算法可以说是最简单的机器学习算法,构建模型只需要保存训练数据集即可。想要对新数据点做出预测,算法会在训练数据集中找到最近的数据点,也就是它的“最近邻”。Knn算法最简单的版本只考虑一个最近邻,也就是与我们想要预测的数据点最近的训练数据点。预测结果就是这个训练数据点的已知输出。
简单点说就是在所有样本中找出k个离样本点最近的测试点的类别,哪种类别多样本点就属于哪类。可以理解为你不知道你的性别,然后你看看你周围最近的三个人(k=3),发现是两个男的一个女的,于是你就被分为男的。因此k值一般不为偶数,因为这样可能无法分类。一般来说,我们只选择样本数据集中最相似的k个数据(通常k不大于20)。
二、算法原理
(1)准备数据:准备数据集和标签
(2)计算距离:计算测试点与每个样本的距离,可以利用两点之间之间直线最短公式计算![]()
(3)排序:将这些距离按从小到大排序
(4)确定分类:确定前k个距离最小的元素所在的主要分类
(5)返回结果:返回类别出现频率最高的元素类别,作为样本的类别
三、Knn代码实现
预备内容+知识:
1.假设group = array([[2.0,2.1],[2.4,2.3],[3.1,3.0],[0,0],[1.0,0.1],[1.4,1.5]]),labels = ['A','A','A','B','B','B']
2.则dataSet.shape=(6, 2),六行两列
3.tile():功能是重复某个数组,即把数组沿各个方向复制。比如tile(A,1),功能是将数组A沿着x方向复制1倍;tile(A,(1,2)),功能是将数组A沿着x方向复制2倍,沿着y方向复制1倍(不要弄反了)

4.#.sum(),表示将所有元素的值相加,#.sum(axis=1)为按行相加,axis=0为按列相加。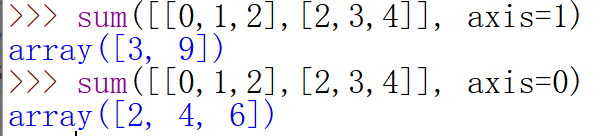
5.argsort(),返回的是数组值从小到大的索引值
6.get(A,B),返回字典中A元素对应的值,若无,则初始化为B
7.operator.itemgetter(x) 用于获取对象的x位置处的数据
8.sorted()中的key关键字:适用于排序列表由元组组成。如sorted(A,key=lambda x:x[0]),x[0]表示元组里的第一个元素,按这个值排序
# 实现Knn
# testPoint为样本点,dataSet为数据集,labels为数据集的标签,k为邻居值
def classifyData(testPoint, dataSet, labels, k):
dataSetSize = dataSet.shape[0] #数据集的大小
# 利用两点间距离计算训练集中每个样本到测试点的距离
# 利用tile()把数组沿各个方向复制,即把testPoint沿着x方向复制1倍,沿着y方向复制dataSetSize倍
diffMat = tile(testPoint, (dataSetSize,1)) - dataSet # 两个矩阵的差,即是[(x1-x2),(y1-y2)]
sqDiffMat = diffMat**2 # 即为[(x1-x2)**2,(y1-y2)**2]
sqDistances = sqDiffMat.sum(axis=1) # 即为(x1-x2)**2+(y1-y2)**2)
distances = sqDistances**0.5 # 即为[(x1-x2)**2,(y1-y2)**2]
# 计算完所有点的距离后,对数据按照从小到大的次序排序,argsort()返回的是数组值从小到大的索引值
sortedDistIndicies = distances.argsort()
# 确定前k个距离最小的元素所在的主要分类,最后返回发生频率最高的元素类别
classCount={}
for i in range(k):
# 取前k个样本的类别
voteIlabel = labels[sortedDistIndicies[i]] # 第i个样本的类别
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1 # 第i个样本所属类别的类别数+1,返回字典classCount中voteIlabel元素对应的值,若无,则初始化为0
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
# 定义key,获取classCount的第1个域的值,按这个值(即类别的个数)进行排序,reverse=True降序排列
return sortedClassCount[0][0] # sortedClassCount[0][1]是类别的个数四、完整代码
'''
@OS:win10
@IDE:IDLE 3.7.4
@Note:文件保存为Knn.py,保存在桌面;运行结果会输出两遍标签,因为此处import Knn了,如果不想这样,可以去掉最后四行改为直接在shell里输入
'''
# -- coding: utf-8 --
from numpy import *
import operator
# 创建训练集
def createDataSet():
group = array([[2.0,2.1],[2.4,2.3],[3.1,3.0],[0,0],[1.0,0.1],[1.4,1.5]])
labels = ['A','A','A','B','B','B']
return group, labels
#实现Knn
def classifyData(testPoint, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
# 利用两点间距离计算训练集中每个样本到测试点的距离,公式为((x1-x2)**2+(y1-y2)**2)**0.5
#利用tile()把数组沿各个方向复制,即把testPoint沿着x方向复制1倍,沿着y方向复制dataSetSize倍(6倍)
diffMat = tile(testPoint, (dataSetSize,1)) - dataSet #两个矩阵的差,即是[(x1-x2),(y1-y2)]
sqDiffMat = diffMat**2 #即为[(x1-x2)**2,(y1-y2)**2]
#.sum(axis=1),表示将所有元素的值按行相加,axis=0为按列相加
sqDistances = sqDiffMat.sum(axis=1) #即为(x1-x2)**2+(y1-y2)**2)
distances = sqDistances**0.5 #即为[(x1-x2)**2,(y1-y2)**2]
# 计算完所有点的距离后,对数据按照从小到大的次序排序,argsort()返回的是数组值从小到大的索引值
sortedDistIndicies = distances.argsort()
# 确定前k个距离最小的元素所在的主要分类,最后返回发生频率最高的元素类别
classCount={}
for i in range(k):
#取前k个样本的类别
voteIlabel = labels[sortedDistIndicies[i]] #第i个样本的类别
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1 #第i个样本所属类别的类别数+1,返回字典classCount中voteIlabel元素对应的值,若无,则初始化为0
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
#定义key,获取classCount的第1个域的值,按这个值(即类别的个数)进行排序,reverse=True降序排列
return sortedClassCount[0][0]
import Knn
group,labels=Knn.createDataSet()
result=Knn.classifyData([2.1,2.3], group, labels, 3) #3为k值,即周围测试点数
print(result)