CSRAN

本文介绍论文《Co-Stack Residual Affinity Networks with Multi-level Attention Refinement for Matching Text Sequences》的相关工作,本文是CAFE算法的扩展版,CAFE算法只计算了one-layer,而本文作者则计算了multi-layer。事实上简单的stacked layer并不会带来太大效果的提升,甚至可能导致效果变差,为了训练深层次的网络,常用的三种网络结构为highway net、residual net、dense net。本文参考三种网络的设计方式,设计了一个网络更深的CAFE。但是本人在复现论文效果的时候发现参考论文的方式,一直达不到论文的效果,因此对论文中的模型结构稍作修改,将stacked-LSTM去掉,然后直接用highway做多层的CAFE投影,发现效果还不错。
Input Encoder
首先将word representation和character representation进行拼接,然后经过2层的highway network进行特征非线性投影。
Multi-level Attention Refinement
这里就比较简单了,直接讲上面讲到的CAFE作为block,参考类似于residual network的方式,输出为input + 6。6为CAFE中抽取的特征:inter-attention有3维,intra-attention有3维。

Co-Stack Residual Affinity
Co-Stacking
Co-Stacking模块负责融合多层的特征输出a、b。回想我们最常用的相似得分计算,本文对其进行多层扩展,在多层中选择最大相似度的词。
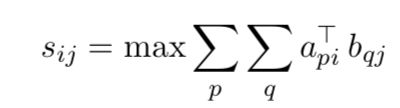
Bidirectional Alignment
通过上面计算的相似矩阵,计算alignment representation。作者论文这里的描述较为模糊,感觉公式推导不过来,因此在实现的时候稍作修改,采用了alignment-pooling的方式进行实现。
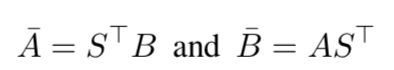

Matching and Aggregation Layer
最后对多层representation和多层alignment representation进行特征增广,然后通过时序模型进行encode。这里作者只是单纯的对时序模型输出进行求和,本人实现的时候也稍作修改,参考之前的论文这里采用了MeanMax。
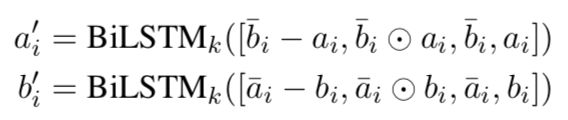

Output and Prediction Layer
这里通过2层的全连接神经网络抽取最终用于classification的representation,然后通过softmax进行归一。
MwAN

本文介绍论文《Multiway Attention Networks for Modeling Sentence Pairs》的相关工作,本文的主要思路是如何利用不同attention所取得的representation来加强特征表示,作者这里采用了大量的attention计算用于对结果进行加权求和。1)作者采用4种不同的attention计算:concat-attention、dot-attention、bilinear-attention和minus-attention;2)由attention计算得到的alignment representation拼接上原始的representation经过一个gate控制信息传播,接着经过一个GRU网络对拼接之后的特征编码,这个时候就会得到四种不同的特征;3)如何对这四种特征进行融合,这里仍然采用attention进行加权融合;4):融合之后的特征再经过一个GRU网络进行最后的编码,GRU输出的是每个词的输出,因此需要对其进行aggregate;5)本文再次对文本Q计算attention加权聚合所有词,最后通过该聚合后的特征对之前的GRU输出做最后的attention加权输出。可以看到整个模型应用的大量的attention计算,就是为了避免简单取max-pooling、mean-pooling导致信息损失的问题。原谅我的无能,参考作者的思路进行实现,并未能取得作者的效果。
Encoding Layer

本文encoding layer与之前稍有不同,本文拼接word embedding和context embedding作为input representation,其中context embedding通过ELMo预训练得到。然后对input representation通过GRU网络进行编码。
Multiway Matching
本文针对2个文本中不同词,设计了4种不同的attention函数:concat attention、bilinear attention、dot attention和minus attention。

文本P第t个词与文本Q中每个词计算一次attention,然后通过该attention对文本Q进行加权用于表示文本P第t个词。
Aggregation
以concat attention为例,对concat之后的特征通过一个gate决定concat之后的特征重要程度,类似于信息控制,然后经过GRU网络进行特征编码。
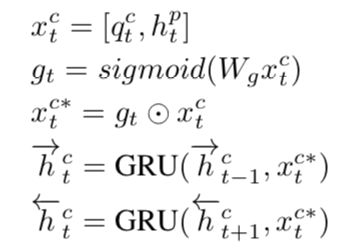
接下来需要对所有的attention输出进行混合聚合,本文采用attention机制对各个attention输出进行加权自适应求和
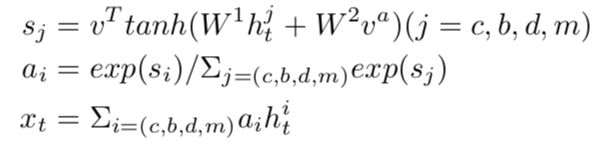
然后,将混合聚合后的特征采用GUR编码

Prediction Layer

对文本Q的编码特征通过attention-pooling选择最要的信息。然后通过该特征与混合编码特征计算co-attention,最后通过该co-attention对混合编码特征加权求和

最后,整个框架采用交叉熵作为损失函数

DRCN

本文介绍论文《Semantic Sentence Matching with Densely-connected Recurrent and Co-attentive Information》的相关工作,本文网络结构相对简单,主要参考了dense-net的网络结构,然后在concatenate时添加attentive information来加强多层网络特征编码能力。
Word Representation Layer
本文input representation由四部分组成:静态word embedding、动态更新word embedding、character embedding和句子间相同词。

Densely connected Recurrent Networks
普通的stacked RNNs由上一层的输出直接做为下一层的输入,但是由于梯度消失和梯度爆炸的问题导致模型非常难以训练

为了避免上面的问题,residual connection通过shortcut完成反向传播。

然而求和运算会阻碍信息的传播,参考densenet的网络设计,作者通过concatenate先前所有层的输出作为下一层的输入,concatenate运算保证了先前隐层的所有特征。

Densely-connected Co-attentive networks
作者通过编码之后两个句子向量计算co-attention


然后将co-attentive information、上一层rnn输出和上一层rnn输入concatenate


Bottleneck component
随着网络层数越深,网络参数越来越大。为了避免这个问题,作者采用autoencoder对特征进行压缩,在减少特征数的同时还能保持原始的信息。
Interaction and Prediction Layer
在经过多层网络之后,作者通过max-pooling对特征进行aggregate。然后对question和answer特征进行组合,最后通过2层的全连接层抽取用于classification的特征。

DMAN

本文介绍论文《Discourse Marker Augmented Network with Reinforcement Learning for Natural Language Inference》的相关工作,文章涉及的内容比较多包含了迁移学习、增强学习和NLI。首先通过特征迁移利用其他数据来丰富目前的特征;在多人标注时,通用的做法是少数服从多数,例如:neural, neural, entailment, contradiction, neural,最终的标签是neural,非0即1的标签太过生硬未能体现出该条样本的置信度,作者这里采用预测标签在该条文本标注集的占比做为reward,因此最终的目标是交叉熵损失最小,reward最大。
Sentence Encoder Model
首先定义source domain的网络结构:通过BiLSTM对句子进行编码,然后对编码特征进行抽取(max-pooling特征和最后时刻特征)




Discourse Marker Augmented Network
Encoding Layer

Interaction Layer
文本匹配模型常用的就是特征交叉,本文做特征交叉时考虑了source domain的特征

通过interaction matrix计算align representation


然后通过align representation做特征增广
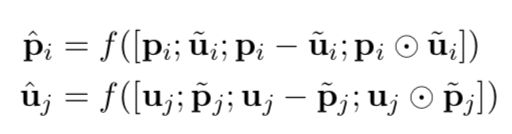
最后通过BiLSTM对特征编码,并对其输出采用attention加权求和


Output Layer

Training
在训练阶段时,作者结合监督学习的交叉熵损失和增强学习的reward共同优化模型,其中reward为预测标签在标注者中的占比。

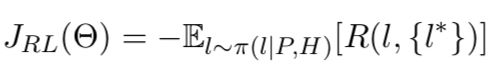


SRL

本文介绍论文《I Know What You Want: Semantic Learning for Text Comprehension》的相关工作,通过对input sentence做语意角色标注来训练tag embedding,然后通过该embedding加强词的表征能力,基础模型采用的ESIM,不同之处在于用ELMo替换Glove embedding,然后加入SRL embedding,其他模型结构不变。最后作者通过实验对SRL embedding、ELMo embedding带来的收益进行了详细的评估,文章的大部分篇幅也是对SRL建模进行了详细的介绍。
下面简单介绍一下文章中的SRL网络结构
Word Representation
word representation包含了两部分:word embedding和SRL embedding,然后进行concat得到最终的word representation。
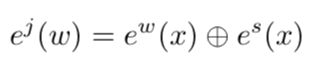
Encoder
编码层为BiLSTM组合highway network做多层的叠加(单独叠加BiLSTM不一定能获得模型效果提升,甚至会带来性能恶化(由于梯度消失和梯度爆炸))

Model Implementation

从最后的实验结果来看,SRL embedding确实带来了效果的提升

参考文献
- Co-Stack Residual Affinity Networks with Multi-level Attention Refinement for Matching Text Sequences
- Multiway Attention Networks for Modeling Sentence Pairs
- Semantic Sentence Matching with Densely-connected Recurrent and Co-attentive Information
- Discourse Marker Augmented Network with Reinforcement Learning for Natural Language Inference
- I Know What You Want: Semantic Learning for Text Comprehension