作者:王昆仑 (天津大学)
Stata 连享会: 知乎 | | 码云 | CSDN
- Stata连享会 计量专题 || 公众号合集
 点击查看完整推文列表
点击查看完整推文列表
连享会:内生性问题及估计方法专题

连享会#金秋十月 @ 空间计量专题 (2019.10.24-27,成都)

导入
双重差分模型 (Difference-Differences, DID)是政策评估的非实验方法中最为常用的一种方法。本系列推文的目的是,利用模拟的方式直观的展示 Standard DID,Time-varying DID 以及其于Event Study Approach (ESA) 的结合应用。
一、引言
关于 DID 方法的推文已经不少了,仅连享会就推送过 Stata: 双重差分的固定效益模型 和 多期DID:平行趋势检验图示 两篇专题文章,还有利用 margins 命令来计算 DID 模型的边际效果的推文 DID 边际分析:让政策评价结果更加丰满 。另外,李春涛老师的爬虫俱乐部公众号也用两期的篇幅来对DID模型和其平行趋势的检验做了简要的介绍。对于 DID 方法可能还不是熟悉的同学,可以结合陈强老师的推文和参考资料里提到的内容一起学习。
与上述的文章相比,这一系列推文有以下三点优势:第一,本系列将上述的 DID 模型的设置,平行趋势的检验和图形表示以及边际效果等一般化的流程尽可能地在一篇推文中展示出来,为读者作为参考;第二,本系列利用同一套的模拟数据,将 Standard DID 以及 Time-varying DID 结合起来,
分析其方程设定的异同;第三,在实际的操作过程中,Time-varying DID 利用 ESA 方法对平行趋势进行检验时,由于可能存在不是所有
个体都最终接受了政策干预,因此,这两种情况下,ESA 方程的设定和代码写作存在差异,这也是本系列推文所着重关心的问题。
二、模拟数据的生成
我重新生成了一份模拟数据,结构为 60 个体*10年共600个观测值的平衡面板数据。我们在数据中设定 2005 年为政策发生当年,id 30-60的个体为处理组,剩余的个体形成控制组。我们将基础的文件保存为DID_Basic_Simu.dta文件,方便后面调用。
///设定60个观测值,设定随机数种子
clear all
set obs 60
set seed 10101
gen id =_n
/// 每一个数值的数量扩大11倍,再减去前六十个观测值,即60*11-60 = 600,为60个体10年的面板数据
expand 11
drop in 1/60
count
///以id分组生成时间标识
bys id: gen time = _n+1999
xtset id time
///生成协变量x1, x2
gen x1 = rnormal(1,7)
gen x2 = rnormal(2,5)
///生成个体固定效应和时间固定效应
sort time id
by time: gen ind = _n
sort id time
by id: gen T = _n
//生成treat和post变量,以2005年为接受政策干预的时点,id为30-60的个体为处理组,其余为控制组
gen D = 0
replace D = 1 if id > 29
gen post = 0
replace post = 1 if time >= 2005
///将基础数据结构保存成dta文件,命名为DID_Basic_Simu.dta,默认保存在当前的 working directory 路径下
save "DID_Basic_Simu.dta",replace
连享会计量方法专题……
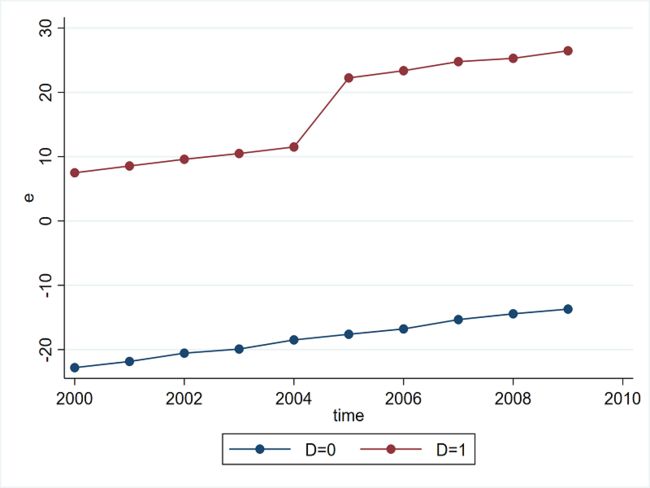
三、政策效果不随时间而变的 Standard DID 的模拟
///调用本文第二部分生成的基础数据结构
clear
use "DID_Basic_Simu.dta"
///生成两种潜在结果,并且合成最终的结果变量,令政策的真实效果为10,且不随时间发生变化,直到最后一期
bysort id: gen y0 = 10 + 5 * x1 + 3 * x2 + T + ind + rnormal()
bysort id: gen y1 = 10 + 5 * x1 + 3 * x2 + T + ind + rnormal() if time < 2005
bysort id: replace y1 = 10 + 5 * x1 + 3 * x2 + 10 + T + ind + rnormal() if time >= 2005
gen y = y0 + D * (y1 - y0)
///去除协变量和个体效应对y的影响,画出剩余残差的图像
xtreg y x1 x2 , fe r
predict e,ue
binscatter e time, line(connect) by(D)
///输出生成的图片,令格式为800*600
graph export "article1_1.png",as(png) replace width(800) height(600)
利用双向固定效应(two-way fixed effects)的方法估计交互项的系数,其中用到 reg, xtreg, areg, reghdfe 等多个 Stata 命令,四个命令的比较放在了下方的表格中。在本文中,主要展示 reghdfe 命令的输出结果,该命令的具体介绍可以参考 Stata: reghdfe-多维固定效应。
| reg | xtreg | areg | reghdfe | |
|---|---|---|---|---|
| 个体固定效应 | i.id | xtreg,fe | areg,absorb(id) | absorb(id time) |
| 时间固定效应 | i.time | i.time | i.time | absorb(id time) |
| 估计方法 | OLS | 组内去平均后OLS | OLS | OLS |
| 优点 | 命令熟悉,逻辑清晰 | 固定效应模型的官方命令 | 官方命令,可以提高组别不随样本规模增加的估计效率 | 高维固定效应模型,可以极大提到估计效率,且选项多样,如支持多维聚类 |
| 缺点 | 运行速度慢,结果呈现过多不太需要的固定效应的结果 | 需要手动添加时间固定效应 | 需要手动添加时间固定效应 | 无 |
reghdfe y c.D#c.post x1 x2, absorb(id time) vce(robust)
+--------------------------------------------------------------------------------+
(converged in 3 iterations)
HDFE Linear regression Number of obs = 600
Absorbing 2 HDFE groups F( 3, 528) = 262423.36
Statistics robust to heteroskedasticity Prob > F = 0.0000
R-squared = 0.9995
Adj R-squared = 0.9995
Within R-sq. = 0.9993
Root MSE = 1.0154
+-------------------------------------------------------------------------------+
| Robust
y | Coef. Std. Err. t P>t [95% Conf. Interval]
+-------------------------------------------------------------------------------+
c.D#c.post | 9.868932 .1654078 59.66 0.000 9.543994 10.19387
x1 | 4.998123 .0060976 819.69 0.000 4.986144 5.010101
x2 | 3.003366 .0084909 353.71 0.000 2.986685 3.020046
+-------------------------------------------------------------------------------+
Absorbed degrees of freedom:
+--------------------------------------------------------+
Absorbed FE | Num. Coefs. = Categories Redundant
+--------------------------------------------------------+
id | 60 60 0
time | 9 10 1
+--------------------------------------------------------+
将回归结果存储,并且放在同一张表格中输出。
///四组回归结果输出如下
reg y c.D#c.post x1 x2 i.time i.id, r
eststo reg
xtreg y c.D#c.post x1 x2 i.time, r fe
eststo xtreg_fe
areg y c.D#c.post x1 x2 i.time, absorb(id) robust
eststo areg
reghdfe y c.D#c.post x1 x2, absorb(id time) vce(robust)
eststo reghdfe
estout *, title("The Comparison of Actual Parameter Values") ///
cells(b(star fmt(%9.3f)) se(par)) ///
stats(N N_g, fmt(%9.0f %9.0g) label(N Groups)) ///
legend collabels(none) varlabels(_cons Constant) keep(x1 x2 c.D#c.post)
+--------------------------------------------------------------------------------+
| The Comparison of Actual Parameter Values
+--------------------------------------------------------------------------------+
| reg xtreg_fe areg reghdfe
+--------------------------------------------------------------------------------+
c.D#c.post | 9.869*** 9.869*** 9.869*** 9.869***
| (0.166) (0.189) (0.166) (0.166)
x1 | 4.998*** 4.998*** 4.998*** 4.998***
| (0.006) (0.006) (0.006) (0.006)
x2 | 3.003*** 3.003*** 3.003*** 3.003***
| (0.008) (0.008) (0.008) (0.008)
+--------------------------------------------------------------------------------+
N | 600 600 600 600
Groups | 60
+--------------------------------------------------------------------------------+
* p<0.05, ** p<0.01, *** p<0.001
+--------------------------------------------------------------------------------+
四组回归结果中交互项和协变量的估计系数和标准误几乎完全相同(唯一的区别在于 xtreg_fe 估计交互项系数的标准差),并且都十分接近于模拟生成时的设定值,说明方程设定和使用的估计方法是合适的。从上面四个回归结果可以知道,交互项的估计系数均为9.86,其95%置信区间明显包含政策的真实效果10。因此,上述四个命令在估计双向固定效应上作用是等价的。
(补充:在本文的模拟中主要使用的是固定效应模型,那么如果使用随机效应模型来估计,方程的形式和结果是否会有变化?这一问题留给感兴趣的读者去思考。PS:仔细观察一下本文的数据生成过程(Data Generating Process, DGP))。
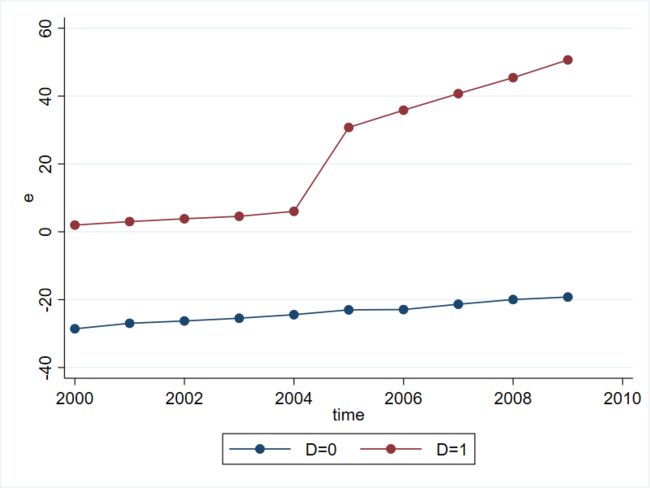
四、政策效果随时间而变的 Standard DID 的模拟
///调用本文第二部分生成的基础数据结构
clear
use "DID_Basic_Simu.dta"
///生成两种潜在结果,并且合成最终的结果变量,令政策的真实效果随时间发生变化,即(5*T-T),由于从2005年开始接受干预,因此,每年的政策效果应为24,28,32,36,40.
bysort id: gen y0 = 10 + 5 * x1 + 3 * x2 + T + ind + rnormal()
bysort id: gen y1 = 10 + 5 * x1 + 3 * x2 + T + ind + rnormal() if time < 2005
bysort id: replace y1 = 10 + 5 * x1 + 3 * x2 + T * 5 + ind + rnormal() if time >= 2005
gen y = y0 + D * (y1 - y0)
///去除协变量和个体效应对y的影响,画出剩余残差的图像
xtreg y x1 x2 , fe r
predict e,ue
binscatter e time, line(connect) by(D)
利用双向固定效应(two-way fixed effects)的方法估计交互项的系数,其中用到 reg, xtreg, areg, reghdfe 等多个 Stata 命令。在本文中,主要展示命令'reghdfe'的输出结果。
. reghdfe y c.D#c.post x1 x2, absorb(id time) vce(robust)
+--------------------------------------------------------------------------------+
(converged in 3 iterations)
HDFE Linear regression Number of obs = 600
Absorbing 2 HDFE groups F( 3, 528) = 44552.05
Statistics robust to heteroskedasticity Prob > F = 0.0000
R-squared = 0.9978
Adj R-squared = 0.9975
Within R-sq. = 0.9964
Root MSE = 2.4029
+--------------------------------------------------------------------------------+
| Robust
y | Coef. Std. Err. t P>t [95% Conf. Interval]
+--------------------------------------------------------------------------------+
c.D#c.post | 31.84782 .3931208 81.01 0.000 31.07555 32.6201
x1 | 5.014706 .0154247 325.11 0.000 4.984405 5.045008
x2 | 2.973101 .0202111 147.10 0.000 2.933397 3.012805
+--------------------------------------------------------------------------------+
Absorbed degrees of freedom:
+-------------------------------------------------------------+
Absorbed FE| Num. Coefs. = Categories Redundant
+-------------------------------------------------------------+
id | 60 60 0
time | 9 10 1
+-------------------------------------------------------------+
将回归结果存储,并且放在同一张表格中输出。
///四组回归结果输出如下
reg y c.D#c.post x1 x2 i.time i.id, r
eststo reg
xtreg y c.D#c.post x1 x2 i.time, r fe
eststo xtreg_fe
areg y c.D#c.post x1 x2 i.time, absorb(id) robust
eststo areg
reghdfe y c.D#c.post x1 x2, absorb(id time) vce(robust)
eststo reghdfe
estout *, title("The Comparison of Actual Parameter Values") ///
cells(b(star fmt(%9.3f)) se(par)) ///
stats(N N_g, fmt(%9.0f %9.0g) label(N Groups)) ///
legend collabels(none) varlabels(_cons Constant) keep(x1 x2 c.D#c.post)
+--------------------------------------------------------------------------------+
| The Comparison of Actual Parameter Values
+--------------------------------------------------------------------------------+
| reg xtreg_fe areg reghdfe
+--------------------------------------------------------------------------------+
c.D#c.post | 31.848*** 31.848*** 31.848*** 31.848***
| (0.394) (0.194) (0.394) (0.394)
x1 | 5.015*** 5.015*** 5.015*** 5.015***
| (0.015) (0.016) (0.015) (0.015)
x2 | 2.973*** 2.973*** 2.973*** 2.973***
| (0.020) (0.019) (0.020) (0.020)
+--------------------------------------------------------------------------------+
N | 600 600 600 600
Groups | 60
+--------------------------------------------------------------------------------+
* p<0.05, ** p<0.01, *** p<0.001
+--------------------------------------------------------------------------------+
四组回归结果中交互项和协变量的估计系数和标准误几乎完全相同(唯一的区别在于 xtreg_fe 估计项系数的标准差),并且都十分接近于模拟生成时的设定值,说明方程设定和使用的估计方法是合适的。从上面四个回归结果可以知道,交互项的估计系数均为31.848。再次验证了上述四个命令在估计双向固定效应(two-way fixed effects)上作用是等价的。
(补充:在本文的模拟中主要使用的是固定效应模型,那么如果使用随机效应模型来估计,方程的形式和结果是否会有变化?这一问题留给感兴趣的读者去思考。PS:仔细观察一下本文的数据生成过程(Data Generating Process, DGP))。
连享会计量方法专题……
五、Standard DID 和 Event Study Approach 的结合
本部分介绍政策效果随时间发生变化和不随时间发生变化两种情况下,如何与时间研究法(Event Study Approach)相结合。 DID 应用 ESA 方法有两个目的:一是可以利用回归方法对双重差分法中最重要的平行趋势假设进行检验,与上面的图示法相比,好处在于可以控制协变量的影响,方程形式也更加灵活;二是可以更加清楚地得到政策效果在时间维度上地变化。因此,这部分检验在论文中也往往被称为政策的动态效果(Dynamic Effects) 或者灵活的 DID (Flexible DID Estimates).具体实现结果如下:
5.1 灵活的 DID :政策效果不随时间发生变化
Standard DID 的动态效果也有多种语法命令的形式,本文提供两种,主要应用 Stata 的 Factor Variables 语法。
///调用本文第二部分生成的基础数据结构
clear
use "DID_Basic_Simu.dta"
///生成两种潜在结果,并且合成最终的结果变量,令政策的真实效果为10,且不随时间发生变化,直到最后一期
bysort id: gen y0 = 10 + 5 * x1 + 3 * x2 + T + ind + rnormal()
bysort id: gen y1 = 10 + 5 * x1 + 3 * x2 + T + ind + rnormal() if time < 2005
bysort id: replace y1 = 10 + 5 * x1 + 3 * x2 + 10 + T + ind + rnormal() if time >= 2005
gen y = y0 + D * (y1 - y0)
///预先生成年度虚拟变量
tab time, gen(year)
方法1如下:
. reghdfe y i.D#i.time x1 x2, vce(robust) absorb(id time)
+--------------------------------------------------------------------------------+
(converged in 3 iterations)
HDFE Linear regression Number of obs = 600
Absorbing 2 HDFE groups F( 11, 520) = 71307.67
Statistics robust to heteroskedasticity Prob > F = 0.0000
R-squared = 0.9995
Adj R-squared = 0.9995
Within R-sq. = 0.9993
Root MSE = 1.0147
+--------------------------------------------------------------------------------+
| Robust
y | Coef. Std. Err. t P>t [95% Conf. Interval]
+--------------------------------------------------------------------------------+
D#time |
1 2001 | .4381916 .3796627 1.15 0.249 -.3076697 1.184053
1 2002 | .6093975 .3984095 1.53 0.127 -.1732924 1.392087
1 2003 | .4808495 .3948783 1.22 0.224 -.2949033 1.256602
1 2004 | .1168801 .4088713 0.29 0.775 -.6863626 .9201227
1 2005 | 9.810181 .3870237 25.35 0.000 9.049859 10.5705
1 2006 | 10.48194 .3664986 28.60 0.000 9.761937 11.20194
1 2007 | 9.999201 .3978656 25.13 0.000 9.217579 10.78082
1 2008 | 10.2474 .4087051 25.07 0.000 9.444481 11.05031
1 2009 | 10.45248 .3979999 26.26 0.000 9.670592 11.23436
x1 | 4.996797 .0061877 807.54 0.000 4.984641 5.008953
x2 | 3.004127 .0087679 342.63 0.000 2.986902 3.021352
+--------------------------------------------------------------------------------+
Absorbed degrees of freedom:
+-------------------------------------------------------------+
Absorbed FE| Num. Coefs. = Categories - Redundant
+-------------------------------------------------------------+
id | 60 60 0
time | 9 10 1
+-------------------------------------------------------------+
方法2如下:
. reghdfe y c.D#(c.year2-year10) x1 x2, absorb(id time) vce(robust)
+--------------------------------------------------------------------------------+
(converged in 3 iterations)
HDFE Linear regression Number of obs = 600
Absorbing 2 HDFE groups F( 11, 520) = 71307.67
Statistics robust to heteroskedasticity Prob > F = 0.0000
R-squared = 0.9995
Adj R-squared = 0.9995
Within R-sq. = 0.9993
Root MSE = 1.0147
+--------------------------------------------------------------------------------+
| Robust
y | Coef. Std. Err. t P>t [95% Conf. Interval]
+--------------------------------------------------------------------------------+
c.D#c.year2 | .4381916 .3796627 1.15 0.249 -.3076697 1.184053
c.D#c.year3 | .6093975 .3984095 1.53 0.127 -.1732924 1.392087
c.D#c.year4 | .4808495 .3948783 1.22 0.224 -.2949033 1.256602
c.D#c.year5 | .1168801 .4088713 0.29 0.775 -.6863626 .9201227
c.D#c.year6 | 9.810181 .3870237 25.35 0.000 9.049859 10.5705
c.D#c.year7 | 10.48194 .3664986 28.60 0.000 9.761937 11.20194
c.D#c.year8 | 9.999201 .3978656 25.13 0.000 9.217579 10.78082
c.D#c.year9 | 10.2474 .4087051 25.07 0.000 9.444481 11.05031
c.D#c.year10| 10.45248 .3979999 26.26 0.000 9.670592 11.23436
x1| 4.996797 .0061877 807.54 0.000 4.984641 5.008953
x2| 3.004127 .0087679 342.63 0.000 2.986902 3.021352
+--------------------------------------------------------------------------------+
Absorbed degrees of freedom:
+-------------------------------------------------------------+
Absorbed FE| Num. Coefs. = Categories - Redundant
+-------------------------------------------------------------+
id | 60 60 0
time | 9 10 1
+-------------------------------------------------------------+
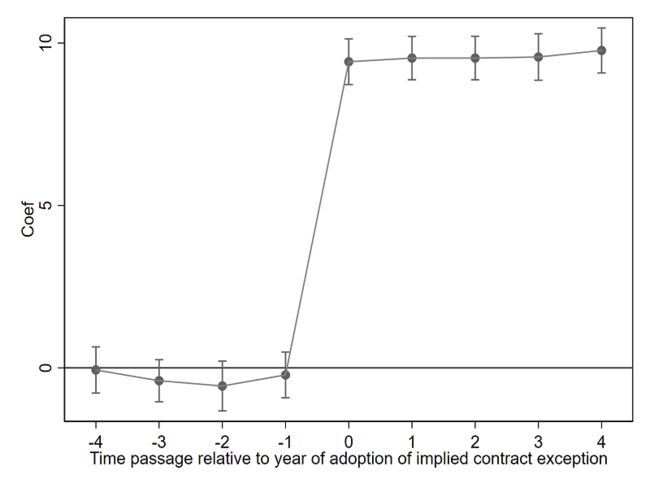
方法1和方法2的主要差异在于:方法2通过手动生成时间虚拟变量,构造出交互项,因此可以指定某一个组别作为参照组,在本文中将样本中的第一期作为基准组,另外在论文中常用的还有讲政策实施的前一期和当期作为基准参照组。除此之外,两种方程设定所得到的估计系数完全一致,以第一期为基期,第二期和第五期的系数的T值远小于2,因此,可以认为它们与0没有显著差异,从而验证了平行趋势假设。第六期到第十期的系数分别是9.81,10.48,9.999,10.25,10.45,其95%CI都包含真实效应10,因此,该方程设定是可靠的。系数的图形化表达如下:
coefplot, ///
keep(c.D#c.year2 c.D#c.year3 c.D#c.year4 c.D#c.year5 c.D#c.year6 c.D#c.year7 c.D#c.year8 c.D#c.year9 c.D#c.year10) ///
coeflabels(c.D#c.year2 = "-4" ///
c.D#c.year3 = "-3" ///
c.D#c.year4 = "-2" ///
c.D#c.year5 = "-1" ///
c.D#c.year6 = "0" ///
c.D#c.year7 = "1" ///
c.D#c.year8 = "2" ///
c.D#c.year9 = "3" ///
c.D#c.year10 = "4") ///
vertical ///
yline(0) ///
ytitle("Coef") ///
xtitle("Time passage relative to year of adoption of implied contract exception") ///
addplot(line @b @at) ///
ciopts(recast(rcap)) ///
scheme(s1mono)
5.2 灵活的 DID : 政策效果随时间发生变化
///调用本文第二部分生成的基础数据结构
clear
use "DID_Basic_Simu.dta"
///生成两种潜在结果,并且合成最终的结果变量,令政策的真实效果随时间发生变化,即(5*T-T),由于从2005年开始接受干预,因此,每年的政策效果应为24,28,32,36,40.
bysort id: gen y0 = 10 + 5 * x1 + 3 * x2 + T + ind + rnormal()
bysort id: gen y1 = 10 + 5 * x1 + 3 * x2 + T + ind + rnormal() if time < 2005
bysort id: replace y1 = 10 + 5 * x1 + 3 * x2 + T * 5 + ind + rnormal() if time >= 2005
gen y = y0 + D * (y1 - y0)
///预先生成年度虚拟变量
tab time, gen(year)
方法1如下:
reghdfe y i.D#i.time x1 x2, vce(robust) absorb(id time)
+--------------------------------------------------------------------------------+
(converged in 3 iterations)
HDFE Linear regression Number of obs = 600
Absorbing 2 HDFE groups F( 11, 520) = 75233.93
Statistics robust to heteroskedasticity Prob > F = 0.0000
R-squared = 0.9996
Adj R-squared = 0.9996
Within R-sq. = 0.9994
Root MSE = 1.0147
+--------------------------------------------------------------------------------+
| Robust
y | Coef. Std. Err. t P>t [95% Conf. Interval]
+--------------------------------------------------------------------------------+
D#time |
1 2001 | .4381916 .3796627 1.15 0.249 -.3076697 1.184053
1 2002 | .6093975 .3984095 1.53 0.127 -.1732924 1.392087
1 2003 | .4808495 .3948783 1.22 0.224 -.2949033 1.256602
1 2004 | .1168801 .4088713 0.29 0.775 -.6863626 .9201227
1 2005 | 23.81018 .3870237 61.52 0.000 23.04986 24.5705
1 2006 | 28.48194 .3664986 77.71 0.000 27.76194 29.20194
1 2007 | 31.9992 .3978656 80.43 0.000 31.21758 32.78082
1 2008 | 36.2474 .4087051 88.69 0.000 35.44448 37.05031
1 2009 | 40.45248 .3979999 101.64 0.000 39.67059 41.23436
+--------------------------------------------------------------------------------+
x1 | 4.996797 .0061877 807.54 0.000 4.984641 5.008953
x2 | 3.004127 .0087679 342.63 0.000 2.986902 3.021352
+--------------------------------------------------------------------------------+
Absorbed degrees of freedom:
+-------------------------------------------------------------+
Absorbed FE| Num. Coefs. = Categories Redundant
+-------------------------------------------------------------+
id | 60 60 0
time | 9 10 1
+-------------------------------------------------------------+
reghdfe y c.D#(c.year2-year10) x1 x2 , absorb(id time) vce(robust)
+--------------------------------------------------------------------------------+
(converged in 3 iterations)
HDFE Linear regression Number of obs = 600
Absorbing 2 HDFE groups F( 11, 520) = 75233.93
Statistics robust to heteroskedasticity Prob > F = 0.0000
R-squared = 0.9996
Adj R-squared = 0.9996
Within R-sq. = 0.9994
Root MSE = 1.0147
+--------------------------------------------------------------------------------+
| Robust
y | Coef. Std. Err. t P>t [95% Conf. Interval]
+--------------------------------------------------------------------------------+
c.D#c.year2 | .4381916 .3796627 1.15 0.249 -.3076697 1.184053
c.D#c.year3 | .6093975 .3984095 1.53 0.127 -.1732924 1.392087
c.D#c.year4 | .4808495 .3948783 1.22 0.224 -.2949033 1.256602
c.D#c.year5 | .1168801 .4088713 0.29 0.775 -.6863626 .9201227
c.D#c.year6 | 23.81018 .3870237 61.52 0.000 23.04986 24.5705
c.D#c.year7 | 28.48194 .3664986 77.71 0.000 27.76194 29.20194
c.D#c.year8 | 31.9992 .3978656 80.43 0.000 31.21758 32.78082
c.D#c.year9 | 36.2474 .4087051 88.69 0.000 35.44448 37.05031
c.D#c.year10| 40.45248 .3979999 101.64 0.000 39.67059 41.23436
x1| 4.996797 .0061877 807.54 0.000 4.984641 5.008953
x2| 3.004127 .0087679 342.63 0.000 2.986902 3.021352
+--------------------------------------------------------------------------------+
Absorbed degrees of freedom:
+-------------------------------------------------------------+
Absorbed FE| Num. Coefs. = Categories Redundant
+-------------------------------------------------------------+
id | 60 60 0
time | 9 10 1
+-------------------------------------------------------------+
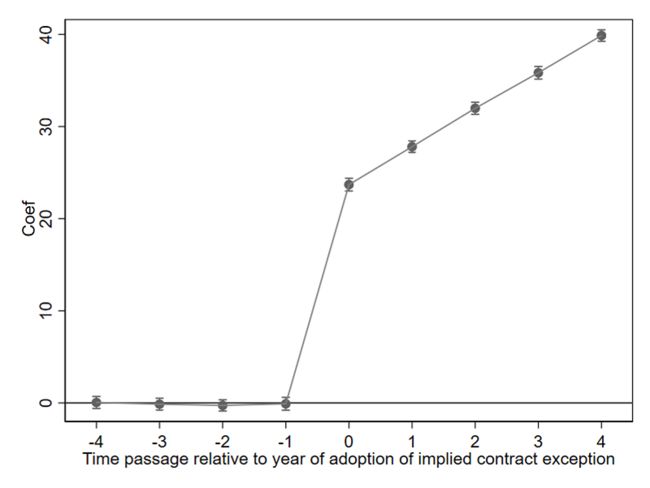
上面两种方法的估计结果完全一致,前五期的T值远小于2,因此可以认为这些估计系数与0无显著差异,而且从第六期开始,估计系数分别为23.81,28.48,32.00,36.25,40.45,这与模拟程序设定的真实值十分接近。下一步是将回归方程的结果通过图形更加直观的呈现出来,具体如下:
coefplot, ///
keep(c.D#c.year2 c.D#c.year3 c.D#c.year4 c.D#c.year5 c.D#c.year6 c.D#c.year7 c.D#c.year8 c.D#c.year9 c.D#c.year10) ///
coeflabels(c.D#c.year2 = "-4" ///
c.D#c.year3 = "-3" ///
c.D#c.year4 = "-2" ///
c.D#c.year5 = "-1" ///
c.D#c.year6 = "0" ///
c.D#c.year7 = "1" ///
c.D#c.year8 = "2" ///
c.D#c.year9 = "3" ///
c.D#c.year10 = "4") ///
vertical ///
yline(0) ///
ytitle("Coef") ///
xtitle("Time passage relative to year of adoption of implied contract exception") ///
addplot(line @b @at) ///
ciopts(recast(rcap)) ///
scheme(s1mono)
六、总结和拓展
本文是本系列推文的第一篇,其主要内容是介绍了政策效果不随时间而变和政策效果随时间而变的 DID 模型的模拟,结合 Event Study Approach
对 DID 最重要的平行趋势假设进行了检验,另外利用 coefplot 命令对 DID 方法所估计的政策动态效果进行了图形化展示。
本系列的下一篇推文将介绍 Time-varying DID 的模拟,平行趋势检验在不同情形下的模型设定的差异以及政策动态效果的图形化表达。
参考资料
- Stata: 双重差分的固定效益模型
- 多期DID:平行趋势检验图示
- DID 边际分析:让政策评价结果更加丰满
- 双重差分模型的平行趋势假定如何检验? ——coefplot命令来告诉你(一)
- 双重差分模型的平行趋势假定如何检验? ——coefplot命令来告诉你(二)
- 模型系列-DID入门(附Stata操作)
- Stata: reghdfe-多维固定效应
- 开学礼包:如何使用双重差分法的交叉项(迄今最全攻略)
附:全部代码
基础数据结构的生成和保存
///设定60个观测值,设定随机数种子
clear all
set obs 60
set seed 10101
gen id =_n
/// 每一个数值的数量扩大11倍,再减去前六十个观测值,即60*11-60 = 600,为60个体10年的面板数据
expand 11
drop in 1/60
count
///以id分组生成时间标识
bys id: gen time = _n+1999
xtset id time
///生成协变量x1, x2
gen x1 = rnormal(1,7)
gen x2 = rnormal(2,5)
///生成个体固定效应和时间固定效应
sort time id
by time: gen ind = _n
sort id time
by id: gen T = _n
///生成treat和post变量,以2005年为接受政策干预的时点,id为30-60的个体为处理组,其余为控制组
gen D = 0
replace D = 1 if id > 29
gen post = 0
replace post = 1 if time >= 2005
///将基础数据结构保存成dta文件,命名为DID_Basic_Simu.dta,默认保存在当前的 working directory 路径下
save "DID_Basic_Simu.dta",replace
政策效果不随时间而变DID模拟的代码
///调用本文第二部分生成的基础数据结构
clear
use "DID_Basic_Simu.dta"
///生成两种潜在结果,并且合成最终的结果变量,令政策的真实效果为10
bysort id: gen y0 = 10 + 5 * x1 + 3 * x2 + T + ind + rnormal()
bysort id: gen y1 = 10 + 5 * x1 + 3 * x2 + T + ind + rnormal() if time < 2005
bysort id: replace y1 = 10 + 5 * x1 + 3 * x2 + 10 + T + ind + rnormal() if time >= 2005
gen y = y0 + D * (y1 - y0)
///去除协变量和个体效应对y的影响,画出剩余残差的图像
xtreg y x1 x2 , fe r
predict e,ue
binscatter e time, line(connect) by(D)
///输出生成的图片,令格式为800*600
graph export "article1_1.png",as(png) replace width(800) height(600)
///多种回归形式
reg y c.D#c.post x1 x2 i.time i.id, r
eststo reg
xtreg y c.D#c.post x1 x2 i.time, r fe
eststo xtreg_fe
areg y c.D#c.post x1 x2 i.time, absorb(id) robust
eststo areg
reghdfe y c.D#c.post x1 x2, absorb(id time) vce(robust)
eststo reghdfe
estout *, title("The Comparison of Actual Paramerer Values") ///
cells(b(star fmt(%9.3f)) se(par)) ///
stats(N N_g, fmt(%9.0f %9.0g) label(N Groups)) ///
legend collabels(none) varlabels(_cons Constant) keep(x1 x2 c.D#c.post)
///ESA及图示法
///预先生成年度虚拟变量
tab time, gen(year)
reghdfe y i.D#i.time x1 x2, vce(robust) absorb(id time)
reghdfe y c.D#(c.year2-year10) x1 x2, absorb(id time) vce(robust)
coefplot, ///
keep(c.D#c.year2 c.D#c.year3 c.D#c.year4 c.D#c.year5 c.D#c.year6 c.D#c.year7 c.D#c.year8 c.D#c.year9 c.D#c.year10) ///
coeflabels(c.D#c.year2 = "-4" ///
c.D#c.year3 = "-3" ///
c.D#c.year4 = "-2" ///
c.D#c.year5 = "-1" ///
c.D#c.year6 = "0" ///
c.D#c.year7 = "1" ///
c.D#c.year8 = "2" ///
c.D#c.year9 = "3" ///
c.D#c.year10 = "4") ///
vertical ///
yline(0) ///
ytitle("Coef") ///
xtitle("Time passage relative to year of adoption of implied contract exception") ///
addplot(line @b @at) ///
ciopts(recast(rcap)) ///
scheme(s1mono)
///输出生成的图片,令格式为800*600
graph export "article1_3.png",as(png) replace width(800) height(600)
政策效果随时间而变DID模拟的代码
///调用本文第二部分生成的基础数据结构
clear
use "DID_Basic_Simu.dta"
///生成两种潜在结果,并且合成最终的结果变量,令政策的真实效果随时间发生变化,即(5*T-T),由于从2005年开始接受干预,因此,每年的政策效果应为24,28,32,36,40.
bysort id: gen y0 = 10 + 5 * x1 + 3 * x2 + T + ind + rnormal()
bysort id: gen y1 = 10 + 5 * x1 + 3 * x2 + T + ind + rnormal() if time < 2005
bysort id: replace y1 = 10 + 5 * x1 + 3 * x2 + T * 5 + ind + rnormal() if time >= 2005
gen y = y0 + D * (y1 - y0)
///去除协变量和个体效应对y的影响,画出剩余残差的图像
xtreg y x1 x2 , fe r
predict e,ue
binscatter e time, line(connect) by(D)
///输出生成的图片,令格式为800*600
graph export "article1_2.png",as(png) replace width(800) height(600)
///多种回归形式
reg y c.D#c.post x1 x2 i.time i.id, r
eststo reg
xtreg y c.D#c.post x1 x2 i.time, r fe
eststo xtreg_fe
areg y c.D#c.post x1 x2 i.time, absorb(id) robust
eststo areg
reghdfe y c.D#c.post x1 x2, absorb(id time) vce(robust)
eststo reghdfe
estout *, title("The Comparison of Actual Paramerer Values") ///
cells(b(star fmt(%9.3f)) se(par)) ///
stats(N N_g, fmt(%9.0f %9.0g) label(N Groups)) ///
legend collabels(none) varlabels(_cons Constant) keep(x1 x2 c.D#c.post)
///ESA及图示法
///预先生成年度虚拟变量
tab time, gen(year)
reghdfe y i.D#i.time x1 x2, vce(robust) absorb(id time)
reghdfe y c.D#(c.year2-year10) x1 x2, absorb(id time) vce(robust)
coefplot, ///
keep(c.D#c.year2 c.D#c.year3 c.D#c.year4 c.D#c.year5 c.D#c.year6 c.D#c.year7 c.D#c.year8 c.D#c.year9 c.D#c.year10) ///
coeflabels(c.D#c.year2 = "-4" ///
c.D#c.year3 = "-3" ///
c.D#c.year4 = "-2" ///
c.D#c.year5 = "-1" ///
c.D#c.year6 = "0" ///
c.D#c.year7 = "1" ///
c.D#c.year8 = "2" ///
c.D#c.year9 = "3" ///
c.D#c.year10 = "4") ///
vertical ///
yline(0) ///
ytitle("Coef") ///
xtitle("Time passage relative to year of adoption of implied contract exception") ///
addplot(line @b @at) ///
ciopts(recast(rcap)) ///
scheme(s1mono)
///输出生成的图片,令格式为800*600
graph export "article1_4.png",as(png) replace width(800) height(600)
关于我们
- 「Stata 连享会」 由中山大学连玉君老师团队创办,定期分享实证分析经验, 公众号:StataChina。
- 公众号推文同步发布于 CSDN 、 和 知乎Stata专栏。可在百度中搜索关键词 「Stata连享会」查看往期推文。
- 点击推文底部【阅读原文】可以查看推文中的链接并下载相关资料。
- 欢迎赐稿: 欢迎赐稿。录用稿件达 三篇 以上,即可 免费 获得一期 Stata 现场培训资格。
- E-mail: [email protected]
- 往期推文:计量专题 || 精品课程 || 推文 || 公众号合集

