损失函数(loss function)是用来估量你模型的预测值f(x)与真实值Y的不一致程度,它是一个非负实值函数,通常使用L(Y, f(x))来表示,损失函数越小,模型的鲁棒性就越好。损失函数是经验风险函数的核心部分,也是结构风险函数重要组成部分。模型的结构风险函数包括了经验风险项和正则项,通常可以表示成如下式子:
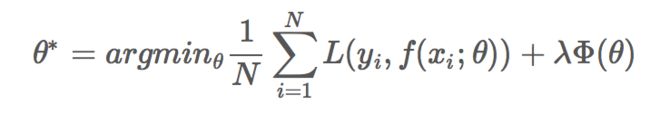
其中,前面的均值函数表示的是经验风险函数,L代表的是损失函数,后面的Φ是正则化项(regularizer)或者叫惩罚项(penalty term),它可以是L1,也可以是L2,或者其他的正则函数。整个式子表示的意思是找到使目标函数最小时的θ值。下面主要列出几种常见的损失函数。
1、对数损失函数
Log损失函数的标准形式:
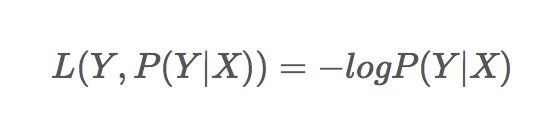
损失函数L(Y, P(Y|X))表达的是样本X在分类Y的情况下,使概率P(Y|X)达到最大值(换言之,就是利用已知的样本分布,找到最有可能(即最大概率)导致这种分布的参数值;或者说什么样的参数才能使我们观测到目前这组数据的概率最大)。因为log函数是单调递增的,所以logP(Y|X)也会达到最大值,因此在前面加上负号之后,最大化P(Y|X)就等价于最小化L了。
逻辑回归的P(Y=y|x)表达式如下:
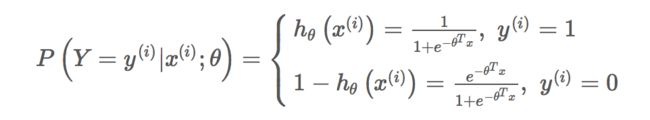
将上面的公式合并在一起,可得到第i个样本正确预测的概率:
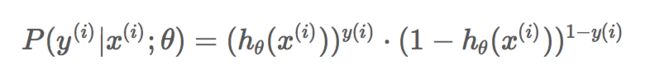
上式是对一个样本进行建模的数据表达。对于所有的样本,假设每条样本生成过程独立,在整个样本空间中(N个样本)的概率分布为:
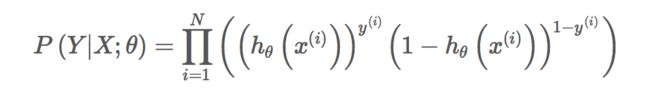
将上式代入到对数损失函数中,得到最终的损失函数为:
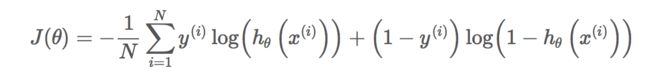
2、平方损失函数
平方损失(Square loss)的标准形式如下:
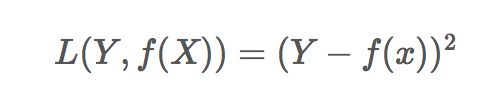
当样本个数为n时,此时的损失函数变为:
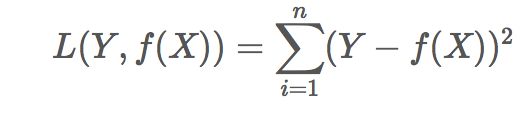
Y-f(X)表示的是残差,整个式子表示的是残差的平方和,而我们的目的就是最小化这个目标函数值(注:该式子未加入正则项),也就是最小化残差的平方和(residual sum of squares,RSS)。
而在实际应用中,通常会使用均方差(MSE)作为一项衡量指标,公式如下:
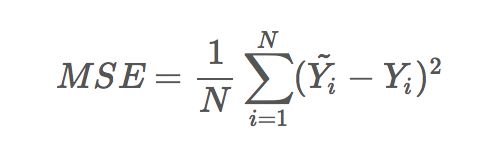
3、指数损失函数
学过Adaboost算法的人都知道,它是前向分步加法算法的特例,是一个加和模型,损失函数就是指数函数。在Adaboost中,经过m此迭代之后,可以得到:
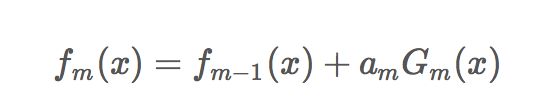
Adaboost每次迭代时的目的是为了找到最小化下列式子时的参数α和G:
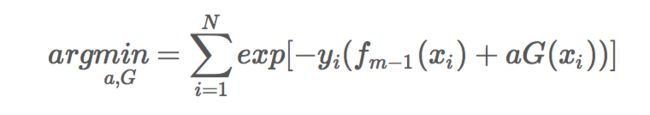
而指数损失函数(exp-loss)的标准形式如下:
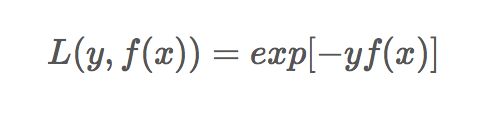
可以看出,Adaboost的目标式子就是指数损失,在给定n个样本的情况下,Adaboost的损失函数为:
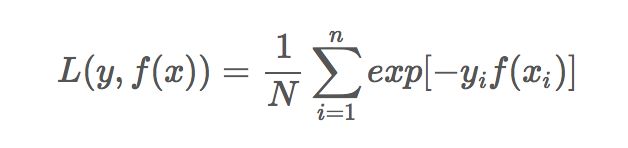
4、合叶损失函数-SVM
首先我们来看什么是合页损失函数(hinge loss function):
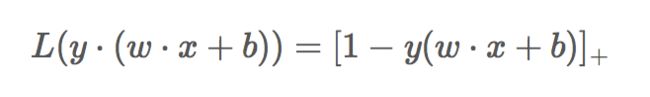
下标”+”表示以下取正值的函数,我们用z表示中括号中的部分:
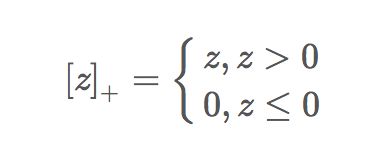
也就是说,数据点如果被正确分类,损失为0,如果没有被正确分类,损失为z。
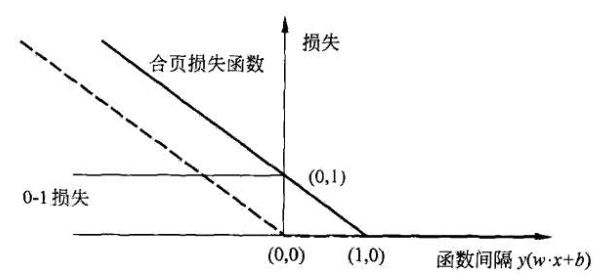
合页损失函数如下图所示:
5、其他损失函数
除了以上这几种损失函数,常用的还有:
0-1损失函数:
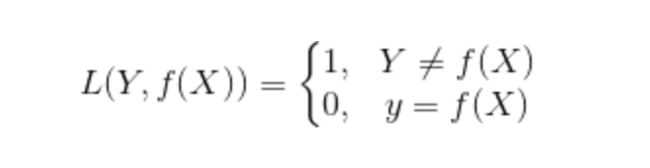
绝对值损失函数:
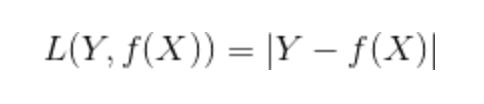
6、各算法的损失函数整理(部分无正则项,不定期更新中)
线性回归
逻辑回归
决策树
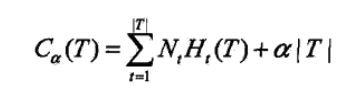
SVM
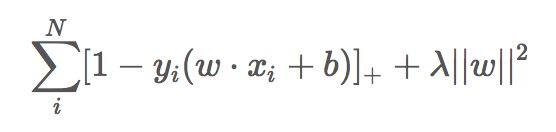
AdaBoost
参考文章:https://plushunter.github.io/2017/07/08/机器学习算法系列(24):损失函数/
http://blog.csdn.net/shenxiaoming77/article/details/51614601