研究图像到一定程度的人,应该都对积分图像有所了解,大家在百度或者google中都可以搜索到大量的相关博客,我这里不做多介绍。用积分图也确实能解决很多实际的问题,比如我博客中的基于局部均方差相关信息的图像去噪及其在实时磨皮美容算法中的应用 一文我就在网上看到很多人用累计积分图和乘积积分图来实现了。不过我浏览了很多人的博客,觉得很多人哪怕是图像方面的似乎还比较牛的人都对这个积分图的理解还不到位或者说理解有误,这里有必要借助我微弱的力量再次校正下。
首先一个普遍的问题就是:积分图像的大小。你可以看到,90%自己写的积分图的作者都是把积分图像定位为W * H,但是不知道他们有没有注意到OpenCV里积分图的相关文档,我这里贴出OpenCV的官方文档:
C++: void integral(InputArray image, OutputArray sum, int sdepth=-1
| Parameters: |
|
|---|
注意到sum这一项的大小了吗, (W + 1) X (H + 1)而非W X H,为什么呢,我们知道,某个点的积分图反应的是原图中此位置左上角所有像素之和,这里是的累加和是不包括这个点像素本身的,那么这样,对于原图的第一行和第一列的所有像素,其对应位置的积分图就应该是0, 这样考虑到所有的像素,为了能容纳最后一列和最后一行的情况,最终的积分图就应该是 (W + 1) X (H + 1)大小。
如果你还是希望定义成W X H大小,那么就必须每次判断你访问的积分图的位置,作为写程序来说,这样做对程序的性能和代码的简洁性都是不好的,并且你稍微不注意就会把代码写错。
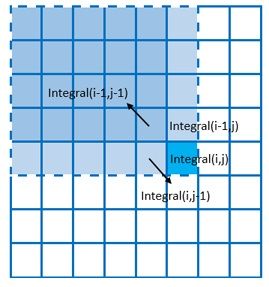
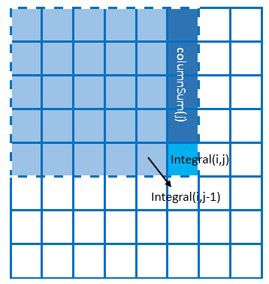
第二,就是积分图的计算的优化,很多博客也都描述了他们的优化方式,虽然他们都是描述的同一个算法,比如百度上比较靠前的博文: 【图像处理】快速计算积分图 中就用下述前两幅图描述了他的优化过程:
 --------->
--------->  --------->
---------> 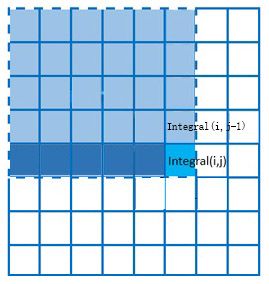
(1) 最原始方案 (2)网络上的优化方案 (3)我的优化方案
不错,这样做已经很不错了,但是有一个问题就是我们需要多一个大小为W的内存来更新保存每一列相应的累计和,但是我们如果换成行方向呢,如上面的(3)所示,则只需要一个变量来累计行方向上的值,而我们知道单个变量CPU可能会把他放置到寄存器中或者我们可以强制把他声明为register变量的,而列方向上的内存数据就无法做到这一点了。
另外,我们申请了积分图后,是没有必要先给他来一个清零操作的,因为后续我们会对每一个位置的值都填充0的。
好,下面我们贴出了优化后的代码:
1 void GetGrayIntegralImage(unsigned char *Src, int *Integral, int Width, int Height, int Stride) 2 { 3 memset(Integral, 0, (Width + 1) * sizeof(int)); // 第一行都为0 4 for (int Y = 0; Y < Height; Y++) 5 { 6 unsigned char *LinePS = Src + Y * Stride; 7 int *LinePL = Integral + Y * (Width + 1) + 1; // 上一行位置 8 int *LinePD = Integral + (Y + 1) * (Width + 1) + 1; // 当前位置,注意每行的第一列的值都为0 9 LinePD[-1] = 0; // 第一列的值为0 10 for (int X = 0, Sum = 0; X < Width; X++) 11 { 12 Sum += LinePS[X]; // 行方向累加 13 LinePD[X] = LinePL[X] + Sum; // 更新积分图 14 } 15 } 16 }
代码很简单,但是集成了很多细节信息,只有有心人才能理解。
在PC上,也许还是可以考虑到SSE优化,要使用SSE,就必须对Sum这个做改造,又要用一个W长度的int型内存记录,然后对 LinePD[X] = LinePL[X] + Sum; 用SSE优化,一次性处理4个数据据的加法,但是这么做SSE的提速和前面sum那句的处理的耗时那个更厉害,我没有去验证了。
那么上面方法(2)的进一步的语法优化的代码如下(比原作者那个应该效率会好很多的)
1 void GetGrayIntegralImage(unsigned char *Src, int *Integral, int Width, int Height, int Stride) 2 { 3 int *ColSum = (int *)calloc(Width, sizeof(int)); // 用的calloc函数哦,自动内存清0 4 memset(Integral, 0, (Width + 1) * sizeof(int)); 5 for (int Y = 0; Y < Height; Y++) 6 { 7 unsigned char *LinePS = Src + Y * Stride; 8 int *LinePL = Integral + Y * (Width + 1) + 1; 9 int *LinePD = Integral + (Y + 1) * (Width + 1) + 1; 10 LinePD[-1] = 0; 11 for (int X = 0; X < Width; X++) 12 { 13 ColSum[X] += LinePS[X]; 14 LinePD[X] = LinePD[X - 1] + ColSum[X]; 15 } 16 } 17 free(ColSum); 18 }
可以看到,在最内层的循环里多了几个内存变量的访问,朋友们可以自己测试,我的优化方案在这一块的耗时只有方案(2)的一半左右,而且代码更简洁。
当我们需要访问中心点为(x, y),半径为r的范围内的矩形像素内的累积值,相应的坐标计算就应该为:
Integral(x - r, y - r) + Integral(x + r + 1, y + r + 1) - Integral(x - r, y + r + 1) - Integral(x + r + 1, y - r)
注意上式计算中的加1,这主要是因为积分图是计算左上角像素的累计值这个特性决定的。
那么下面我贴出用积分图实现0(1)的均值模糊的部分代码:
void BoxBlur(unsigned char *Src, unsigned char *Dest, int Width, int Height, int Stride, int Radius) { int *Integral = (int *)malloc((Width + 1) * (Height + 1) * sizeof(int)); GetGrayIntegralImage(Src, Integral, Width, Height, Stride); //#pragma omp parallel for for (int Y = 0; Y < Height; Y++) { int Y1 = max(Y - Radius, 0); int Y2 = min(Y + Radius + 1, Height - 1); /*int Y1 = Y - Radius; int Y2 = Y + Radius + 1; if (Y1 < 0) Y1 = 0; if (Y2 > Height) Y2 = Height;*/ int *LineP1 = Integral + Y1 * (Width + 1); int *LineP2 = Integral + Y2 * (Width + 1); unsigned char *LinePD = Dest + Y * Stride; for (int X = 0; X < Width; X++) { int X1 = max(X - Radius, 0); int X2 = min(X + Radius + 1, Width); // int X1 = X - Radius; // if (X1 < 0) X1 = 0; // int X2 = X + Radius + 1; // if (X2 >= Width) X2 = Width - 1; int Sum = LineP2[X2] - LineP1[X2] - LineP2[X1] + LineP1[X1]; int PixelCount = (X2 - X1) * (Y2 - Y1); LinePD[X] = (Sum + (PixelCount >> 1)) / PixelCount; } } free(Integral); }
代码也很简洁明了,注意下我注释掉的几个部分。
第一:
//#pragma omp parallel for
由于进行的积分图的操作,每个像素点的周边半径为r区域内的像素之和的计算就是前后无关的了,因此像素和像素之间的计算就是独立的了,这样就可以并行执行,这里用了OpenMP作为简易并行实现的一个例子而已。
第二:我原来编程习惯怎是不怎么喜欢用max和min这样的函数,我总觉得用if这种判断效率应该会比max或者min高,而实际上却是max厉害一些,我看了下反汇编,max和min充分利用了条件按传送指令比如cmovg,cmovl,而一般的if语句很大程度上会调用jmp指令的(当然和常数比较一般编译也会用条件传送替代的,比如和0比较),jmp指令时比较耗时的。因此.......
还有一个注意点就是积分图的最大X坐标是Width,最大Y坐标是Height, 这点和图像有所不同,正如上述代码所示。
通过积分图技术实现的均值模糊和之前我在文章解析opencv中Box Filter的实现并提出进一步加速的方案(源码共享) 中介绍的方式(非SSE优化的代码)耗时基本差不多,内存占用也差不多,但是积分图技术有个优势,就是如果某个算法需要计算同一个图像的多个半径的模糊值,则积分图只需要计算一次,只在众多的基于多尺度模糊的算法中也是能提速的方案之一。
上述是普通的累计积分图,我们常用的还有平方积分图,还有两幅图对应的乘积积分图,本质上和本例是没有啥,只需将 Sum += LinePS[X]; 这一句稍作修改。但是有一点,一直是我不太愿意用积分图的主要原因,就是保存积分图数据的内存区域或者数据类型问题,普通的积分图还好,就算是每个像素都为255,也只有当图像大于2800*3000左右时,才会超出int类型所能表达的范围,如果用uint类型表示,能容纳的图像大小又能提高一倍,一般来说够用了,但是如果是平方积分图,int类型在极端情况下只能处理不大于 256*256大小的图像,这样在实际中基本上是无用的,因此,可能我们就需要float类型或者int64为来表示。但是,第一,float类型会引来计算速度下降,特别是非PC的环境下。第二,int64会占用更大的内存,大约是8倍的原图像内存,同时在32位系统上也会带来速度的下降。
对于彩色的图像,处理方式也类似,这里就不赘述了。
本文对应的代码下载地址:http://files.cnblogs.com/files/Imageshop/IntegralImage.rar
