Teambition是一个跨平台的团队协作和项目管理工具,相当于国外的Trello。使用Teambition可以像使用白板与便签纸一样来管理项目进度,如下图所示。

Teambition虽然便于管理项目,但是如果直接在Teambition上面创建一个项目对应的任务,却容易陷入面对茫茫白板,不知道如何拆分任务的尴尬境地。如下图所示。
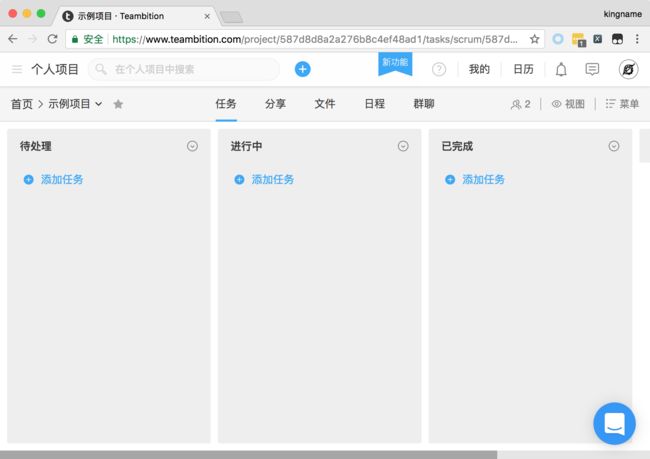
面对这个空荡荡的窗口,应该添加哪些任务进去?直接用脑子现想,恐怕容易出现顾此失彼或者干脆漏掉了任务的情况。
当我要开始一个项目的时候,我一般不会直接打开Teambition就写任务,而是使用一个大纲工具——Workflowy来梳理思路,切分任务。等任务已经切分好了,在誊写到Teambition中,如下图所示。
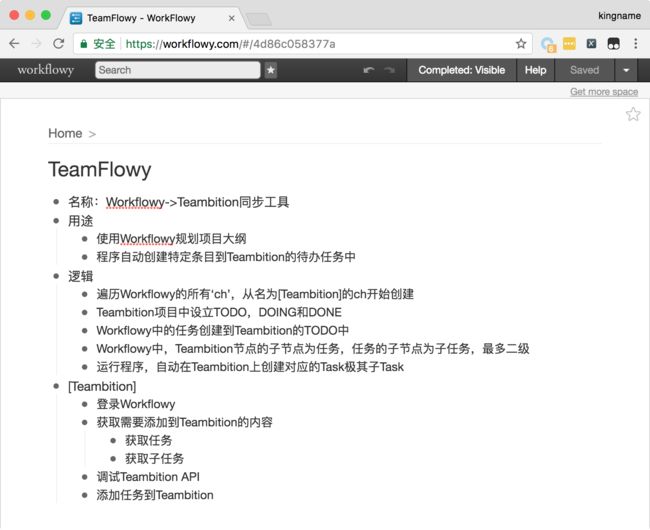
但这样就出现了一个问题:首先在Workflowy上面把需要做的任务写好。然后再打开Teambition,把这些任务又誊写到Teambition中。为了减少“誊写”这一步重复劳动,于是就有了TeamFlowy这个小工具。它的作用是自动誊写Workflowy中的特定条目到Teambition中。
功能介绍
TeamFlowy是一个Python脚本,运行以后,它会登录Workflowy账号,读取上面所有的条目。名为[Teambition]的条目是任务开始的标记,这个条目下面的一级条目会作为任务被添加到Teambition中。如果任务下面还有二级条目,这些二级条目会作为子任务被添加到任务中。由于Teambition是按照项目-Stage-任务-子任务的形式组织一个工程(其中Stage对应了Teambition中工程下面的面板,例如:“待处理”,“进行中”,“完成”。)不会存在子任务的子任务,所以Workflowy中[Teambition]这个条目下面最多出现二级缩进。如下图所示。

实现原理
Workflowy
获取Workflowy上面的条目,需要进行三步操作:
- 登录Workflowy
- 获取所有条目对应的JSON字符串
- 提取需要添加到Teambition中的条目
登录Workflowy
打开Chrome监控登录Wokrflowy的过程,可以看到登录Workflowy需要访问的接口为:https://workflowy.com/accounts/login/。使用HTTP POST方式发送请求,提交的数据包括username,password和一个不知道用途的next。如下图所示。
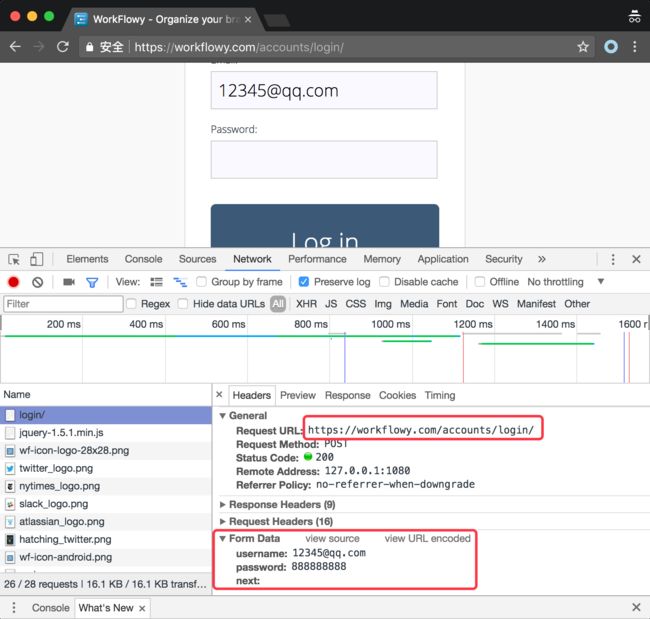
使用Python的第三方网络模块requests向这个模块发送POST请求,提交用户名和密码即可实现登录。其代码如下:
login_url = 'https://workflowy.com/accounts/login/'
session = requests.Session()
session.post(login_url,
data={'username': '[email protected]',
'password': '8888888',
'next': ''})
获取所有条目
使用requests的session登录Workflowy以后,Cookies会被自动保存到session这个对象里面。于是使用session继续访问Workfowy就可以以登录后的身份查看自己的各个条目。
通过Chrome可以看到获取所有条目的接口为https://workflowy.com/get_initialization_data?client_version=18,接口返回的数据是一个包含所有条目的超大型JSON字符串,如下图所示。
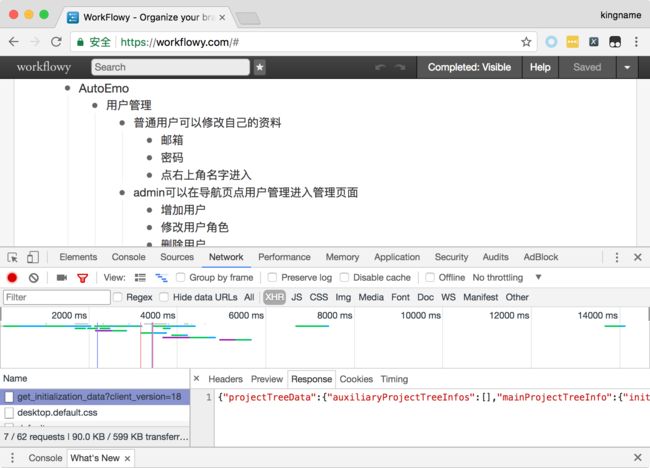
使用Python的json模块可以解析这个JSON字符串为字典,并获取所有条目,代码如下:
outline_url = 'https://workflowy.com/get_initialization_data?client_version=18'
outlines_json = session.get(outline_url).text
outlines_dict = json.loads(outlines_json)
project_list = outlines_dict.get('projectTreeData', {})\
.get('mainProjectTreeInfo', {})\
.get('rootProjectChildren', [])
提取任务与子任务
所有的条目层层嵌套在列表-字典结构中,其基本的形态如下:
{
"ch": [子条目],
"lm": 308496,
"id": "957996b9-67ce-51c7-a796-bfbee44e3d3f",
"nm": "AutoEmo"
}
其中的nm为这个条目的名字。如果一个条目有子条目,那么ch列表中就会有很多个字典,每个字典的都是这个结构,如果一个条目没有子条目,那么就没有ch这个key。这样一层一层嵌套下去:
{
"ch": [
{
"lm": 558612,
"id": "5117e20b-25ba-ba91-59e1-790c0636f78e",
"nm": "准备并熟背一段自我介绍,在任何需要自我介绍的场合都有用"
},
{
"lm": 558612,
"id": "4894b23e-6f47-8028-a26a-5fb315fc4e6f",
"nm": "姓名,来自哪里,什么工作",
"ch": [
{"lm": 5435246,
"id": "4894b23e-6f47-8028-a26a-5fbadfasdc4e6f",
"nm": "工作经验"}
]
}
],
"lm": 558612,
"id": "ea282a1c-94f3-1a44-c5b3-7907792e9e6e",
"nm": "自我介绍"
}
由于条目和子条目的结构是一样的,那么就可以使用递归来解析每一个条目。由于需要添加到Teambition的任务,从名为[Teambition]的条目开始,于是可以使用下面这样一个函数来解析:
task_dict = {}
def extract_task(sections, task_dict, target_section=False):
for section in sections:
name = section['nm']
if target_section:
task_dict[name] = [x['nm'] for x in section.get('ch', [])]
continue
if name == '[Teambition]':
target_section = True
sub_sections = section.get('ch', [])
extract_task(sub_sections, task_dict, target_section=target_section)
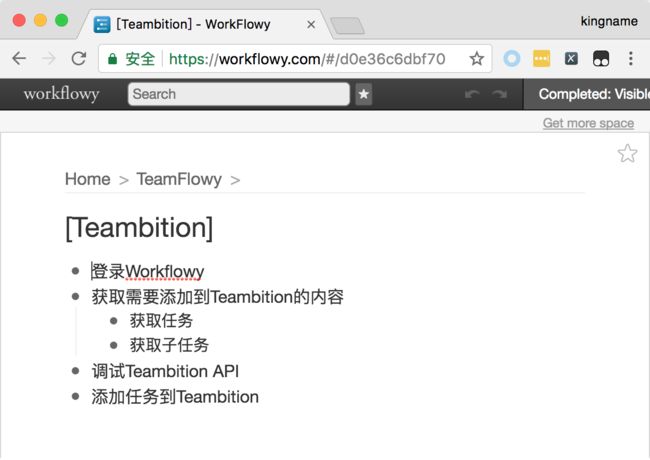
下图所示为一段需要添加到Teambition中的条目,运行这段函数以后,得到的结果为:
{'登录Workflowy': [], '获取需要添加到Teambition的内容': ['获取任务', '获取子任务'], '调试Teambition API': [], '添加任务到Teambition': []}
Teambition
将任务添加到Teambition,需要使用Teambition的Python SDK登录Teambition并调用API添加任务。Teambition的Python SDK在使用OAuth2获取access_token的时候有一个坑,需要特别注意。
登录Teambition
设置Teambition应用
Teambition 是使用OAuth2来进行权限验证的,所以需要获取access_token。
首先打开Teambition的开发者中心并单击新建应用,如下图所示。
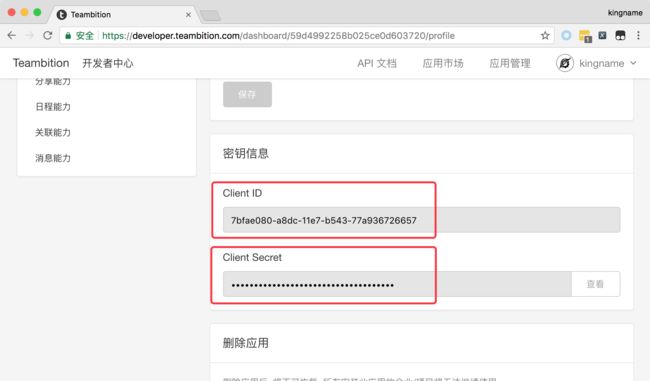
应用名称可以随便写。创建好应用以后,可以看到应用的信息,需要记录Client ID和Client Secret,如下图所示。
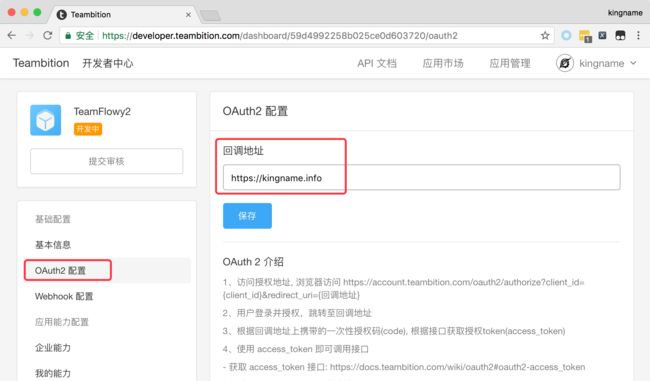
点击左侧的OAuth2配置,填写回调URL,如下图所示。这里的这个URL其实使用任何一个可以访问的网站的域名都可以,这里以我的博客地址为例。
使用Python获取access_token
首先在Python中安装Teambition的SDK:
pip install teambition
接下来,在Python中获取授权URL:
from teambition import Teambition
tb_client_id = '7bfae080-a8dc-11e7-b543-77a936726657'
tb_client_secret = '9830fc8c-81b3-45ed-b3c0-e039ab8f2d8b'
tb = Teambition(tb_client_id,
tb_client_secret)
authorize_url = tb.oauth.get_authorize_url('https://kingname.info')
print(authorize_url)
代码运行以后,会得到一段形如下面这段URL的授权URL:
https://account.teambition.com/oauth2/authorize?client_id=7bfae080-a8dc-11e7-b543-77a936726657&redirect_uri=https://kingname.info&state=&lang=zh
在电脑浏览器中人工访问这个URL,会出现下面这样的页面。
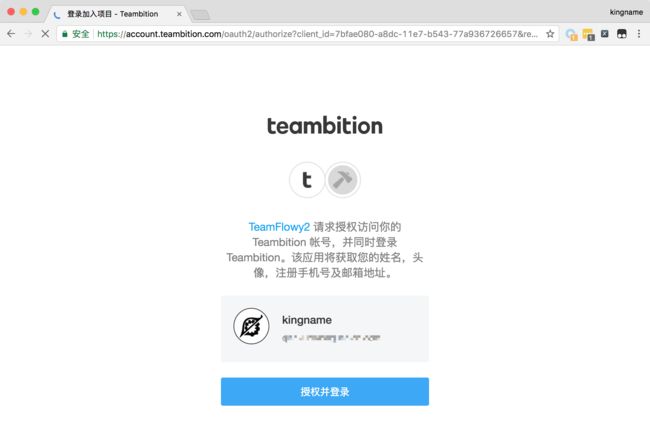
单击授权并登录,可以看到浏览器上面的网址变为形如:https://kingname.info/?code=Pn7ebs4sZh3NYOz2FvVJQ4uu,此时,需要记录code=后面的这一串字符串Pn7ebs4sZh3NYOz2FvVJQ4uu。
接下来就是Teambition的SDK的坑点了,根据Teambition官方文档的说法,要获取access_token,只需要如下两段代码:
code = 'Pn7ebs4sZh3NYOz2FvVJQ4uu' #前面浏览器中的字符串
tb.oauth.fetch_access_token(code)
# 上面的代码完成授权,接下来直接使用tb.xxxx就可以操作任务了。
但实际上,上面这一段代码一定会报错。提示grant invaild。要解决这个问题,就必需使用Teambition的HTTP 接口来人工获取access_token。
code = 'Pn7ebs4sZh3NYOz2FvVJQ4uu' #前面浏览器中的字符串
fetch_result_dict = session.post('https://account.teambition.com/oauth2/access_token',
data={'client_id': tb_client_id,
'client_secret': tb_client_secret,
'code': code,
'grant_type': 'code'}).json()
tb_access_token = fetch_result_dict.get('access_token', '')
此时得到的access_token是一段非常长的字符串。接下来,重新初始化tb变量:
tb = Teambition(tb_client_id,
tb_client_secret,
access_token=tb_access_token)
初始化以后,使用tb这个变量,就可以对工程和任务进行各种操作了。
Teambition的简单使用
要在某个工程里面创建任务,就需要知道工程的ID。首先在Teambition中手动创建一个工程,在浏览器中打开工程,URL中可以看到工程的ID,如下图所示。
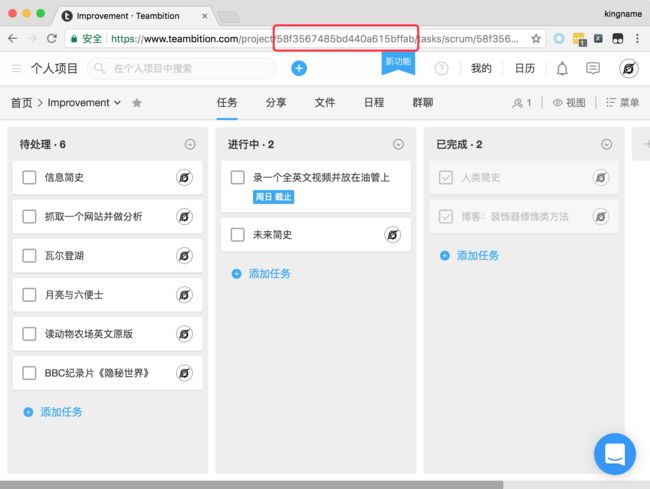
有了工程ID以后,就可以使用下面的代码创建任务:
def create_task(task_name, sub_task_list):
tasklist = tb.tasklists.get(project_id='59d396ee1013d919f3348675')[0]
tasklist_id = tasklist['_id']
todo_stage_id = tasklist['stageIds'][0]
task_info = tb.tasks.create(task_name, tasklist_id=tasklist_id, stage_id=todo_stage_id)
if sub_task_list:
task_id = task_info['_id']
for sub_task_name in sub_task_list:
tb.subtasks.create(sub_task_name, task_id=task_id)
print(f'task: {task_name} with sub tasks: {sub_task_list} added.')
这段代码首先使用tb.tasklists.get()根据工程ID获得任务组的ID和待处理这个面板的ID,接下来调用tb.tasks.create()接口添加任务。从添加任务返回的信息里面拿到任务的ID,再根据任务ID,调用tb.subtasks.create()添加子任务ID。
效果测试
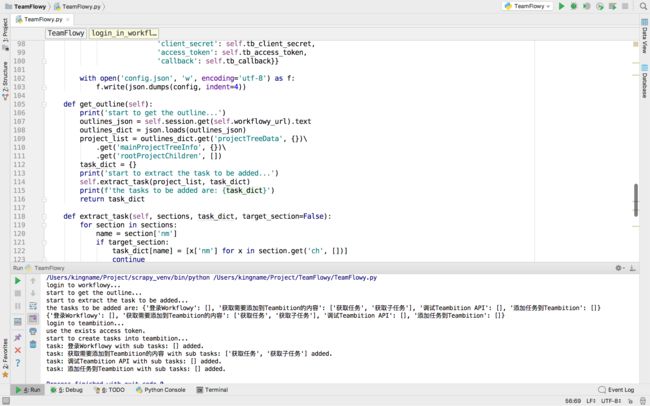
上面的代码实现了TeamFlowy的基本逻辑。运行TeamFlowy脚本以后,[Teambition]这个条目下面的任务被成功的添加到了Teambition中,如下图所示。
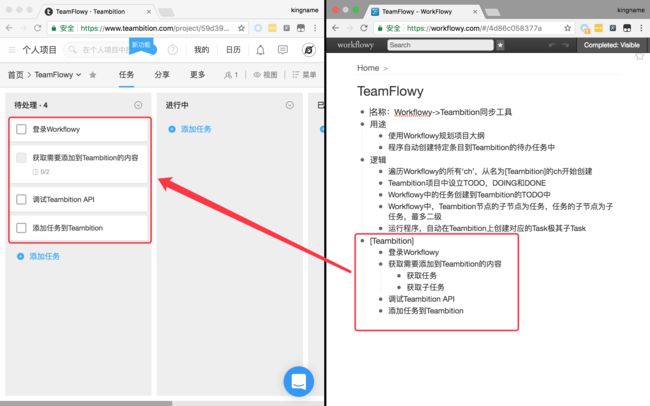
将代码组合起来并进行完善,让代码更容易使用,完整的代码可以查看https://github.com/kingname/TeamFlowy。完整的代码运行效果如下图所示。