原理:
RDD:
使用内存--基本处理单位RDD:弹性分布式数据集
spark处理的时候,处理的是RDD数据(相当于是将块数据加载到内存中)
类似:
[1,2,3,4,5,...] 1个节点处理 [1,2] 1个节点处理[3,4,5] ......
stage:
一个 Job 会被分成一个或多个Stage, 类似airflow的DAG
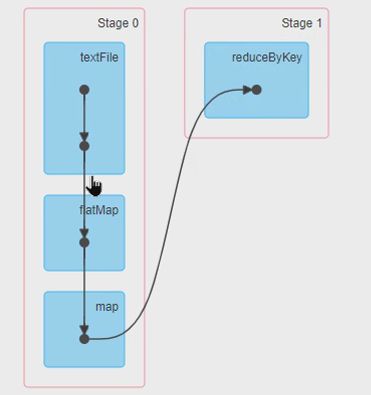
partition:
把RDD分成多个分区运行在分布式的节点上,一个分区对应一个task
相关概念:
spark生态圈:
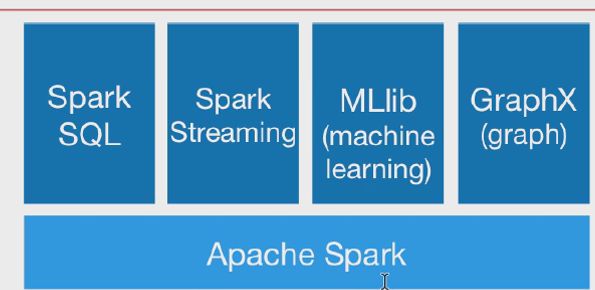
Spark Core:包含Spark的基本功能;尤其是定义RDD的API、操作以及这两者上的动作。其他Spark的库都是构建在RDD和Spark Core之上的 (就是上面的Apache Spark)
Spark SQL:提供通过Apache Hive的SQL变体Hive查询语言(HiveQL)与Spark进行交互的API。每个数据库表被当做一个RDD,Spark SQL查询被转换为Spark操作。即用spark操作hive,和上面的用hive操作spark引擎正好相反。
Spark Streaming:对实时数据流进行处理和控制。Spark Streaming允许程序能够像普通RDD一样处理实时数据。 在kafka的基础上进行一些算子运算。
MLlib:一个常用机器学习算法库,算法被实现为对RDD的Spark操作。这个库包含可扩展的学习算法,比如分类、回归等需要对大量数据集进行迭代的操作。GraphX:控制图、并行图操作和计算的一组算法和工具的集合。
GraphX扩展了RDD API,包含控制图、创建子图、访问路径上所有顶点的操作
集群组件说明:
Cluster Manager:集群管理器。在Standalone模式中即为Master主节点,控制整个集群,监控Worker。在YARN模式中为Resourcemanager
Worker节点:从节点,负责控制计算节点,启动Executor或者Driver。在Standalone模式中指的是通过slave文件配置的Worker节点,在Spark on Yarn模式下就是NoteManager节点
Driver:运行Application的主函数, java的入口函数main,如上面例子中的org.apache.spark.examples.JavaSparkPi
Executor:执行器,是为某个Application运行在worker node上的一个进程。其进程名称为CoarseGrainedExecutorBackend。一个CoarseGrainedExecutorBackend有且仅有一个Executor对象, 负责将Task包装成taskRunner,并从线程池中抽取一个空闲线程运行Task, 这个每一个CoarseGrainedExecutorBackend能并行运行Task的数量取决于分配给它的cpu个数
三种模式对比:
