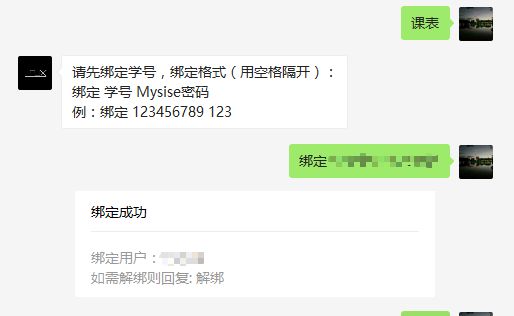
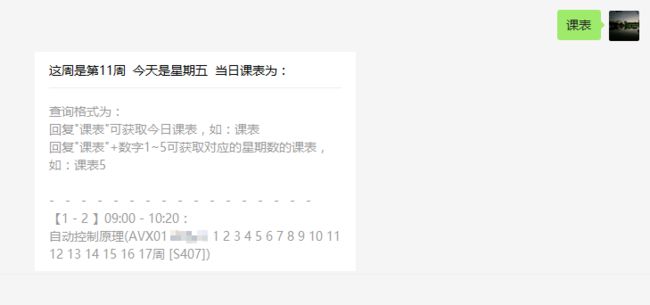
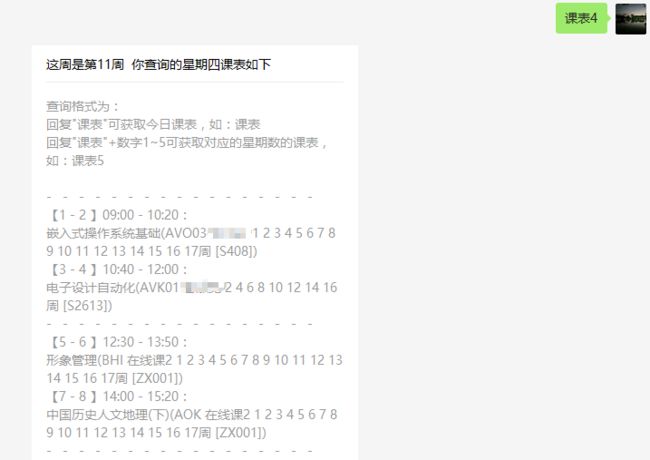
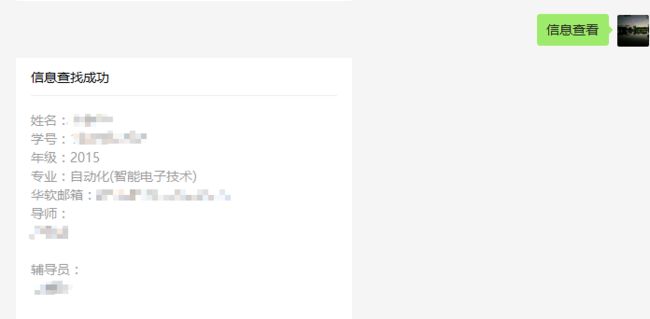
结合之前的Python模拟登录爬取Mysise学生管理系统的信息,在新浪SAE服务器上面做了一个获取学生管理系统的信息,具有绑定学号功能,获取课表、个人信息查询、饭卡充值等功能。
附上github完整代码:https://github.com/bestnike/get_Mysise_infomation
参考资料:使用python一步一步搭建微信公众平台
微信官方开发文档
SAE Python共享服务器文档
微信XML图文消息模版格式
一、注册平台及本地代码部署
注册登录新浪SAE:http://sae.sina.com.cn/(注册地址:http://t.cn/Rlplfty ,你也可以用我的邀请链接注册),创建python 新浪SAE应用,在windows下我个人选择SVN代码托管,记得进行实名认证,不实名认证好像SAE发送出去的信息会被拦截,实名认证提交后大概一天就通过了,创建好应用之后,在代码管理中创建一个新的版本
这里说明一下几个链接
第一个是应用服务器链接,用于接入微信公众号的开发者模式,不同版本号的服务应用是独立的
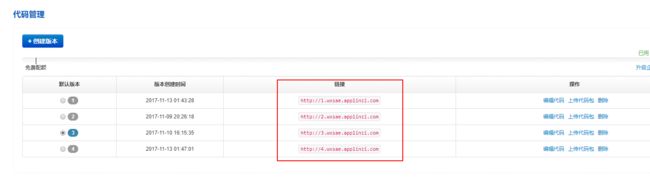
第二个是仓库地址,用于配置本地SVN
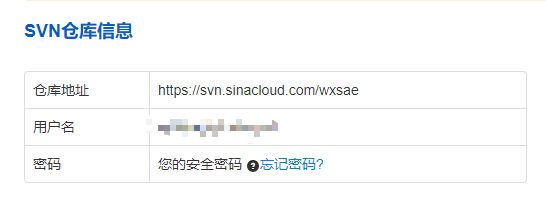
具体SVN代码部署看新浪云提供的开发文档,代码部署手册
注册微信的公众平台:http://mp.weixin.qq.com,这个就不介绍了
二、SAE服务器基本框架及接入微信公众号平台
新建立的SAE Python一般默认有两个文件
第一个是config.yaml,这个文件的作用是说明需要使用到的库
第二个是index.wsgi,这个文件的作用是写Python代码,实现我们的业务逻辑
新浪SAE服务器的Python应用使用的是web.py框架,所以我们的代码多数写在框架上面
想了解web.py的童鞋可以移步http://webpy.org/docs/0.3/tutorial.zh-cn
首先编写config.yaml,注意第一第二行默认用你原始的配置,这两行说明的是你应用名称的版本编号
name:wxsae
version:1
libraries:
- name: webpy
version:"0.36"
- name: lxml
version:"2.3.4"
...
注意严格的缩进
第二个编辑index.wxgi
# coding: UTF-8
import os
import sae
import web
from weixinInterface import WeixinInterface
urls= (
'/weixin','WeixinInterface'
)
app_root= os.path.dirname(__file__)
templates_root= os.path.join(app_root, 'templates')
render= web.template.render(templates_root)
app= web.application(urls, globals()).wsgifunc()
application= sae.create_wsgi_app(app)
代码内容很多是webpy框架内容,这里主要讲几点
第一个是from weixinInterface import WeixinInterface
这里我们需要再创建一个weixinInterface.py文件,文件里面主要写一个WeixinInterface类,你也可以将这个类写在index.wsgi文件中,只是这样看起来会乱乱的,为了实现模块化编程,所以把这些业务逻辑写在这个新建的文件里,文件名和类名只要符合规范就可以,不一定要书写成例子的名,但在index.wxgi文件中导入这个类要注意
第二个是
urls= (
'/weixin','WeixinInterface'
)
注意这个 /weixin 把我们应用服务器链接加上这个/weixin 就构成了用于在微信公众号平台基本配置完整的url http://3.wxsae.applinzi.com/weixin /weixin这个可以随意起,符合命名规则就好,后面的WeixinInterface代表我们上面要写的微信处理类
新建一个weixinInterface.py文件,注意大小写,写入以下代码
# -*- coding: gb2312 -*-
import hashlib
import web
import lxml
import time
import os
import urllib2,json
from lxml import etree
class WeixinInterface:
def __init__(self):
self.app_root = os.path.dirname(__file__)
self.templates_root = os.path.join(self.app_root,'templates')
self.render = web.template.render(self.templates_root)
def GET(self):
#获取输入参数
data = web.input()
signature=data.signature
timestamp=data.timestamp
nonce=data.nonce
echostr=data.echostr
#自己的token
token="youtoken"
#字典序排序
list=[token,timestamp,nonce]
list.sort()
sha1=hashlib.sha1()
map(sha1.update,list)
hashcode=sha1.hexdigest()#sha1加密算法#如果是来自微信的请求,则回echostr
if hashcode == signature:
return echostr
对于Python一定要注意缩进的问题,很多时候直接复制过来出现的问题就在于缩进
解释一下,这个微信类目前写了两个方法,一个是def __init__(self),另一个是def GET(self):
def GET(self)这个函数主要是用来进行token验证,因为微信是将验证信息GET发出去的,所以这里使用了GET方法来取得值并且返回相应的值,当微信进行token验证时,服务器会自动调用GET函数,这里的youtoken可以自己定义,符合命名规则即可
def __init__(self)函数定义了templates,所以还要在根目录下创建一个目录templates的目录,templates目录主要是用来存放XML发送模版文件
全部保存后,用SVN把代码同步在SVN服务器
现在移步到微信公众平台
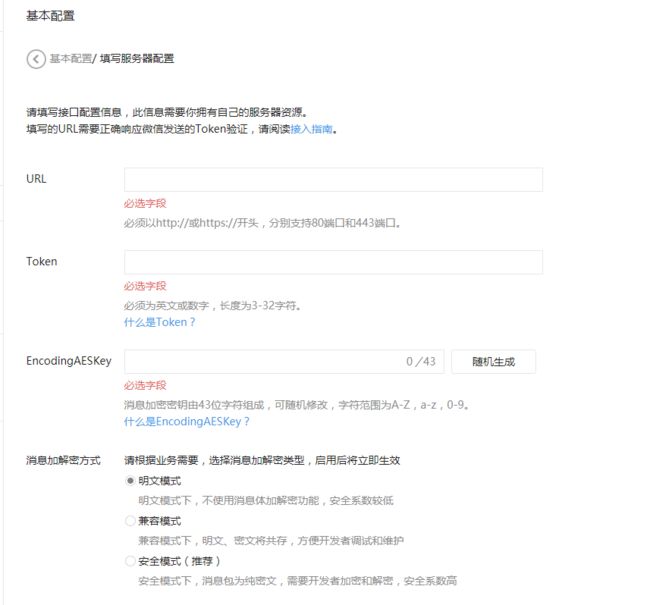
第一个URL就填我们的微信公众号平台基本配置完整的url 例如我们之前的到的http://3.wxsae.applinzi.com/weixin Token填之前在GET函数里面定义的youtoken
EncodingAESKey可以随机,填完这三个参数后就可以提交了
token验证成功会提示提交成功,提交失败的话回去检查自己的代码

下一步就是继续编写weixinInterface.py
def POST(self):
str_xml = web.data()#获得post来的数据
xml = etree.fromstring(str_xml)#进行XML解析
content=xml.find("Content").text#获得用户所输入的内容
msgType=xml.find("MsgType").text
fromUser=xml.find("FromUserName").text
toUser=xml.find("ToUserName").text
return self.render.reply_text(fromUser,toUser,int(time.time()),u"我现在还在开发中,还没有什么功能,您刚才说的是:"+content)
这里的POST函数写在WeixinInterface类里面,与GET函数同级缩进
微信用户向公众号发送数据是以POST请求的方式进行的,所以当用户向公众号发送数据服务器会自动调用POST函数
所以我们需要把对数据处理代码写在POST函数里面
接下来说的是XML,用户对公众号的操作会以XML的格式返回给服务器,所以我们需要XML库对用户的信息进行解析,XML里面的内容有几个参数,消息类型、消息内容、发送者名称、发送给谁的名称,目前这个POST函数没有实现什么功能,只是简单的重复回复用户的消息
当代码在运行中遇到return 语句,服务器会以你设置的XML格式回复微信用户
return self.render.reply_text reply_text就是你XML模版的文件名,后面接的是参数
接着我们在templates目录下创建reply_text.xml模板文件,写入以下代码
$def with (toUser,fromUser,createTime,content)
$createrTime
注意这里的toUser与fromUser是刚才post的是相反的,因为这里的toUser也就是POST函数里的fromUser,这里的fromUser也就是POST函数里的toUser,msgType是text
全部保存,重新同步到SVN服务器,现在就在用你的个人微信关注一下你创建的公众微信号,然后随便输入些内容,如果没有什么问题,你将会收到一条鹦鹉学舌的回复内容!
三、对用户的消息类进行处理
接着完善POST函数
def POST(self):
data_time=str(time.strftime('%Y-%m-%d',time.localtime(time.time())))
str_xml = web.data() #获得post来的数据
xml = etree.fromstring(str_xml)#进行XML解析
#提取用户操作信息
msgType=xml.find("MsgType").text
fromUser=xml.find("FromUserName").text
toUser=xml.find("ToUserName").text
#事件类操作
if msgType == "event":
mscontent = xml.find("Event").text
#关注事件
if mscontent == "subscribe":
replayText = u'''欢迎关注本微信,回复help查看相关使用帮助'''
return self.render.reply_text(fromUser,toUser,int(time.time()),replayText)
#消息类操作
elif msgType == "text":
content=xml.find("Content").text #提取消息的具体内容
#获取服务器时间
if content == "time":
return self.render.reply_text(fromUser,toUser,int(time.time()),data_time)
微信用户提交的XML消息类型有几种,其中包括事件消息(比如关注事件)、文本类消息
当判断消息类型为 event 且事件类型为 subscribe 时,则发送一条欢迎信息
当判断消息类型为 text 且发送内容关键词为 time时,服务器则返回当前时间给用户,时间获取调用的是Python的时间模块,所以需要在前面 import time,具体时间格式可以参考 Python获取并输出当前日期时间
四、关于Python编码遇到的问题
查看之前写的篇文章 记录一下Python微信公众号 中文编码踩下的坑
五、XML模版格式
详细看 微信XML图文消息模版格式
在templates文件夹下新建一个文件 reply_new.xml ,reply_new.xml的内容如下
$def with (toUser,fromUser,createTime,title,description)
<$createTime>
1
<![CDATA[$title]]>
$description
该模版实际为微信XML图文消息模版格式中的图文消息的定义,只是有的参数可以省略而已
例如我在消息类操作里面添加个帮助信息(与获取获取服务器时间的elif 同级缩进,之后添加的对关键词进行判断的都与这个同级缩进)
#帮助信息
elif content == "help":
help = u"课表\n信息查看\n饭卡充值"
return self.render.reply_new(fromUser,toUser,int(time.time()),u"回复一下关键字获取对应内容",help)
保存,用SVN更新到SVN服务器,公众号回复 help 测试下
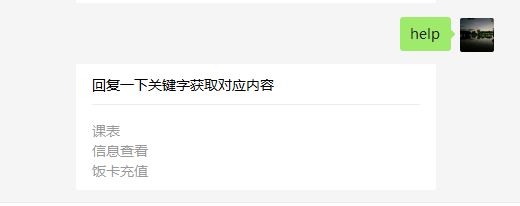
个人比较喜欢图文消息这个XML模版,排版起来比较简洁,你也可以根据自己的喜好更改,比如插入图片,插入链接等
六、利用 Memcached 实现存储数据功能
参考官方文档 Memcached
例如我们需要爬取学生系统课程表的信息,用户在获取课表前得在公众号绑定学号和密码,
没理由让用户在每次查询之前都输入学号和密码,所以我们在第一次查询的时候用Memcached把用户的学号与密码存储起来,使用memcache 需要在前面导入模块
import pylibmc as memcache
mc=memcache.Client()#创建实例
mc.set("foo","bar")#写入数据
value=mc.get("foo")#获取数据
mc.delete("foo")#删除数据
操作格式和字典相似
编写代码
#绑定学号 绑定格式(中间用空格隔开): 绑定 学号 密码
elif content[:2]== u"绑定": #判断前两个字是否是绑定
#分割出学号和密码
content=content.split()
#把获取到的学号、密码以字典嵌套列表的方式存储在数据库,字典关键字fromUser,fromUser是标识不同用户的标志
if mc.get(fromUser) #判断数据库中是否已经有该用户数据
mc.set(fromUser,[content[1],content[2]])
return self.render.reply_text(fromUser,toUser,int(time.time()),u"更新绑定信息成功")
else:
mc.set(fromUser,[content[1],content[2]])
return self.render.reply_text(fromUser,toUser,int(time.time()),u"绑定成功")
#删除对应用户的数据库信息
elif content == u"解绑":
if mc.get(fromUser):
mc.delete(fromUser)
return self.render.reply_text(fromUser,toUser,int(time.time()),u"解绑成功")
else:
return self.render.reply_text(fromUser,toUser,int(time.time()),u"没有绑定")
七、分析Mysise学生管理系统的页面

Mysise有个人信息查询、课表查询、考试时间表等功能,每个功能都有独立的页面,有些页面是需要cookie登录的(比如说课程表、平时成绩等),有些页面则不需要cookie即能访问(比如说个人信息、考试时间表),不需要cookie就能访问的页面我们只需要获取该页面对应的网址,首先我们先分析网址的组成
比如说个人信息的页面

网址的关键信息在于studentid,只需要在主页面把studentid提取出来,再用字符串拼接便可以得到完整的网址,其他的页面同理。
一般的爬虫做法是模拟登录一次后然后获取目标页面的信息再返回信息,假设有一种情况,有一个同一个时间段获取多个不同功能的信息,那么爬虫就得每一次获取信息都需要模拟登录一次,为了加快获取信息的速度,我们可以模拟登录一次成功后,把cookie存储起来,一般情况下cookie的有效期有几个小时的时间。所以我们在用户在最初绑定学号密码时,进行一次模拟登录,登录成功后获取studentid、cookie等页面需要的信息,然后把学号、密码、studentid、cookie等存储在数据库。当用户再次获取信息而cookie失效时再重新模拟登录获取cookie且把cookie更新到数据库
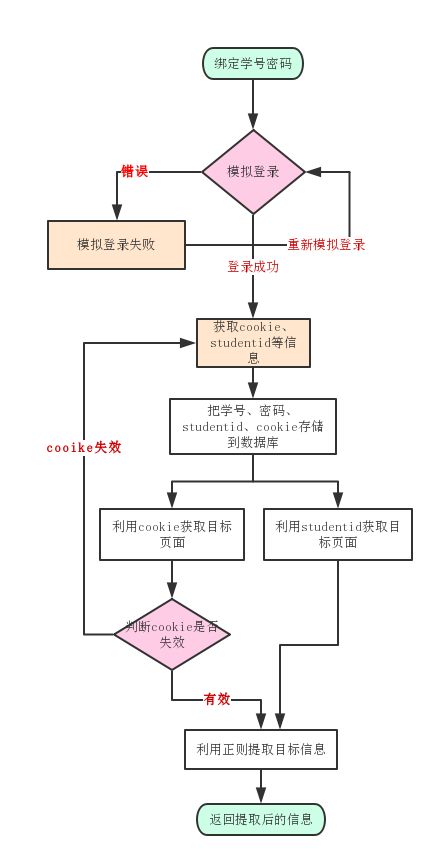
具体爬虫分析过程可以参考之前的文章 记录Python模拟登录爬取华软Mysise学生管理系统的信息
具体的爬虫代码就不重复贴出来了,只是对之前的爬虫代码做了些模块化编写,把各部分代码封装成函数
八、效果