目录
- 写在前面
- mlpconv layer实现
- Global Average Pooling
- 网络结构
- 参考
博客:blog.shinelee.me | 博客园 | CSDN
写在前面
《Network in Network》简称NIN,出自颜水成老师团队,首次发表在arxiv的时间为2013年12月,至20190921引用量为2871(google scholar)。

NIN的网络结构仍是在AlexNet基础上修改而来,其主要创新点如下:
- 提出了mlpconv layer:mlpconv layer中使用小的多层全连接神经网络(multilayer perceptron, MLP)“micro network”替换掉卷积操作,micro network的权重被该层输入feature map的所有local patch共享。卷积操作可以看成线性变换,而micro network可以拟合更复杂的变换,相当于增强了conv layer的能力。多个mlpconv layer堆叠构成整个网络,这也是Network in Network名称的由来。
- 提出了global average pooling(GAP):NIN不再使用全连接层,最后一层mlpconv layer输出的feature map数与类别数相同,GAP对每个feature map求全图均值,结果直接通过softmax得到每个类别的概率。GAP在减少参数量的同时,强行引导网络把最后的feature map学习成对应类别的confidence map。
- \(1\times 1\) convolution:在mlpconv layer中首次使用了\(1\times 1\)卷积,\(1\times 1\)卷积可以在不改变尺寸的情况下,灵活调整feature map的channel数,广泛影响了后续网络的设计,如Inception系列等。
本文将依次介绍上面的创新点,同时顺带介绍 全连接 与 卷积的关系、全连接与GAP的关系,最后给出NIN的网络结构。
mlpconv layer实现

论文中讲,mlpconv layer使用一个小的全连接神经网络替换掉卷积,convolution layer与mlpconv layer对比示意图如下,
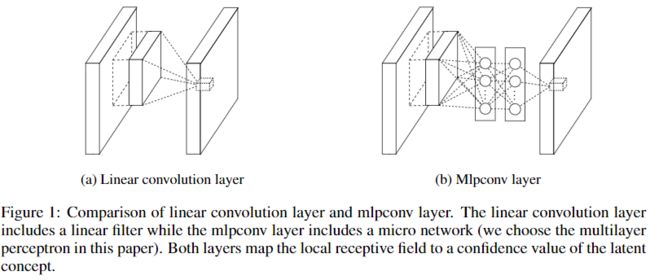
对于convolution layer,假设有N个kernel,每个kernel的尺寸为\(k \times k\),卷积操作将每个\(k \times k\)大小的local recptive field / local patch线性映射为N个输出,汇总所有local patch的卷积结果得到N个feature map。
对于mlpconv layer,使用micro network替换掉卷积,通过micro network将每个\(k \times k\)的local patch非线性映射为N个输出,汇总后仍得到N个feature map。文中说micro network为小的全连接神经网络,但在实现时,这个全连接神经网络却是通过几个卷积层实现的,为什么呢?因为全连接可以转化成卷积。
下面为《Dive into Deep Learning》中提供一个NIN block(mlpconv layer)的mxnet实现,
from mxnet import gluon, nd
from mxnet.gluon import nn
def nin_block(num_channels, kernel_size, strides, padding):
blk = nn.Sequential()
blk.add(nn.Conv2D(num_channels, kernel_size, strides, padding, ctivation='relu'),
nn.Conv2D(num_channels, kernel_size=1, activation='relu'),
nn.Conv2D(num_channels, kernel_size=1, activation='relu'))
return blk一个NIN block通过1个卷积层和2个\(1 \times 1\)卷积层堆叠而成,这3个卷积层的输出channel数相同。对于第1个卷积层,因为kernel_size与local patch大小相同,所以对每一个local patch而言,这个卷积等价于全连接,共num_channels个输出,每个输出与local patch全连接的权重就是对应的整个卷积核,卷积核的数量也为num_channels。对于后面2个\(1\times 1\)的卷积层,输入都是num_channels维的向量,即num_channels个\(1\times 1\)的feature map,kernel_size与整个feature map的尺寸相同,这个\(1\times 1\)的卷积也就相当于全连接了。通过\(1\times 1\)的卷积实现了不同卷积核结果间的信息交流。
实际上,通过调整\(1\times 1\)卷积核的数量,可以在不改变输入feature map尺寸的情况,灵活地增加或减少feature map的channel数量,引入更多的非线性,表达能力更强,在实现feature map间信息交流的同时,获得信息的压缩或增广表示。
Global Average Pooling
卷积神经网络的经典做法是 数个卷积层+几个全连接层,典型视角是将前面的卷积层视为特征提取器,将全连接层视为分类器。卷积层的计算量高但参数少,全连接层的计算量少但参数多,一种观点认为全连接层大量的参数会导致过拟合。作者提出了Global Average Pooling(GAP),取代全连接层,最后一层mlpconv layer输出的feature map数与类别数相同,对每一个feature map取平均,全连接层与GAP的对比如下图所示,图片来自Review: NIN — Network In Network (Image Classification),GAP的结果直接输给softmax得到每个类别的概率。
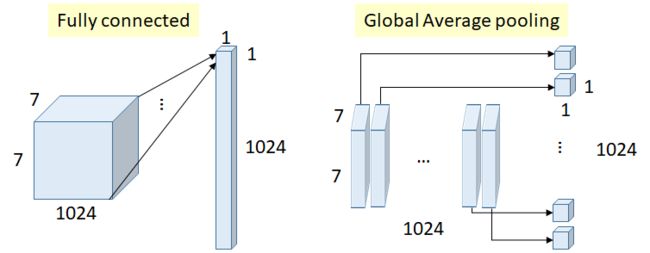
去掉全连接的GAP强制将feature map与对应的类别建立起对应关系,softmax相当于分数的归一化,GAP的输出可以看成是与每个类别相似程度的某种度量,GAP的输入feature map可以解释为每个类别的置信度图(confidence map)——每个位置为与该类别的某种相似度,GAP操作可以看成是求取每个类别全图置信度的期望。因为只有卷积层,很好地保留了空间信息,增加了可解释性,没有全连接层,减少了参数量,一定程度上降低了过拟合。
最后一层mlpconv layer输出的feature map如下,可以看到图片label对应的feature map响应最强,强响应基本分布在目标主体所在的位置。

此外,作者还做将GAP与全连接层、全连接+dropout对比,在CIFAR-10库上的测试结果如下,

GAP可以看成是一种正则,全连接层的参数是学习到的,GAP可以看成是权值固定的全连接层。上面的实验说明,这种正则对改善性能是有效的。
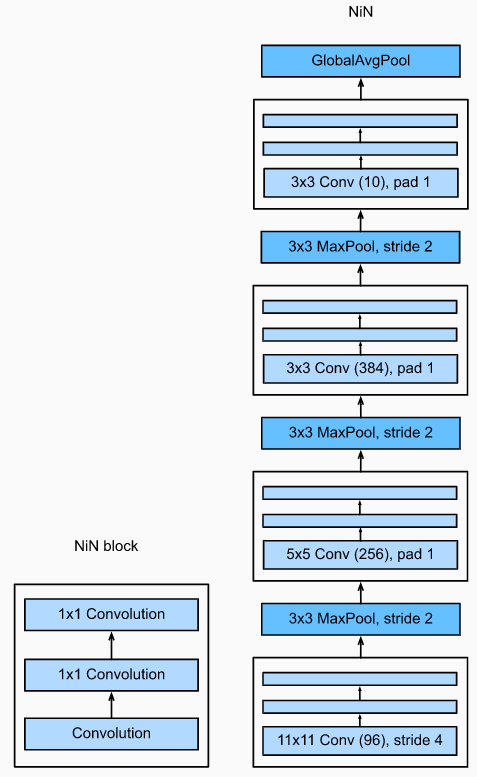
网络结构
论文中给出的整体网络结构如下,
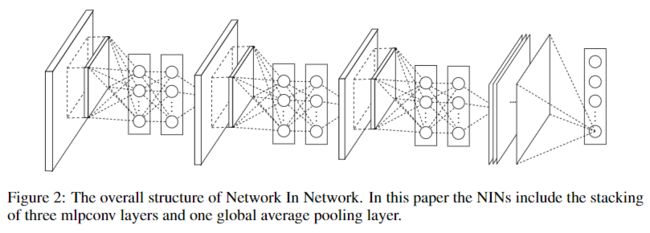
论文中没有给出具体的参数配置,实际上,NIN仍是在AlexNet基础上修改而来,相当于在AlexNet的每个卷积层后插入2个\(1\times 1\)卷积层,移除了Local Response Norm,同时用GAP替换掉全连接层。在这里,mlpconv layer既可以看成是增强了原conv layer的表达能力,也可以看成增加了网络深度。
参考
- arxiv: Network in Network
- 7.3. Network in Network (NiN)
- Review: NIN — Network In Network (Image Classification)
- Network In Network architecture: The beginning of Inception