1、Standalone
软件要求:
Java 1.8.x or higher
ssh
JAVA_HOME配置
You can set this variable in conf/flink-conf.yaml via the env.java.home key.
Flink配置:
下载解压
配置:conf/flink-conf.yaml
jobmanager.rpc.address : master 节点
jobmanager.heap.mb : JobManager可用的内存数量
taskmanager.heap.mb : 每个TaskManager可以用内存数量
taskmanager.numberOfTaskSlots : 每个机器可用的CPU数量
parallelism.default : 集群中总的CPU数量
taskmanager.tmp.dirs : 临时目录
配置conf/slaves:添加worker节点主机名
下面是三个节点的Standalone模式配置的拓扑结构:

启动Flink
下面的脚本在本地节点上启动一个JobManager,并通过SSH连接到salves文件中列出的所有Worker节点,以便在每个节点上启动TaskManager。现在Flink系统已经开始运行了。在本地节点上运行的JobManager现在将接受已配置RPC端口的作业
bin/start-cluster.sh
bin/stop-cluster.sh
添加JobManager或TaskManager实例到集群
可以使用bin.jobmanager.sh和bin/taskmanager.sh脚本为运行中的集群添加JobManager和TaskManager实例
bin/jobmanager.sh((start|start-foreground) cluster)|stop|stop-all
bin/taskmanager.sh start|start-foreground|stop|stop-all
生产中基本很少使用这种模式的,大多数都是基于YARN来进行提交任务,下面主要给出YARN的任务提交配置方式
2、YARN
在YARN上启动一个长时间运行的Flink集群(start a long-time Flink cluster on YARN),这种模式会长期占用YARN的资源,当我们提交任务时,该YARN上cluster接收任务。
启动一个YARN session用4个TaskManager(每个TaskManager分配4GB的堆空间)
./bin/yarn-session.sh -n4 -jm1024 -tm 4096 -s 2
-n : TaskManager的数量,相当于executor的数量
-s : 每个JobManager的core的数量,executor-cores。建议将slot的数量设置每台机器的处理器数量
-tm : 每个TaskManager的内存大小,executor-memory
-jm : JobManager的内存大小,driver-memory
下面是启动前集群的资源分配:
启动之后的分配:
内存增加了18G,core增加了9core=2*4+1(多出来的是作为APPMaster和JobManager的)

YARN sesstion启动之后就可以使用bin/flink来启动提交作业
./bin/flink run -m yarn-cluster -yn4 -yjm1024 -ytm4096 ./examples/batch/WordCount.jar
下面详解介绍YARN session模式
Flink YARN Session
Flink session 将启动所有需要的Flink服务(JobManager和TaskManager),这样就可以向集群提交任务。注意,每个session中可以运行多个任务
bin/yarn-sseaion.sh
下面是启动yarn session时需要给出的参数

注意:客户端需要设置YARN_CONF_DIR 或者 HADOOP_CONF_DIR环境变量和HDFS的配置
Example:下面的命令分配了10TaskManager,每个TM分配8GB和32slot(vcore)
./bin/yarn-session.sh -n10 -tm8192 -s 32
Flink on YARN需要重写下面的配置参数:
jobmanager.rpc.address : JobManager允许被分配到不同的机器上
taskmanager.tmp.dirs : 使用YARN给出的临时目录
parallelism.default : slots的数量需要被指定
-D 可以动态修改参数
-Dfs.overwrite-files=true -Dtaskmanager.network.memory.min=536346624
上面例子启动了11个container(10个container作为TaskManager的),还有一个作为ApplicationMaster和JobManager的
如果集群上有足够的资源,Flink on YARN上只会启动所有被请求的container。大多数YARN调度器用于container的请求内存,一些也用于core的数量。一般情况下,vcore的数量等于处理的slot(-s)的数量,yarn.containers.vcores运行使用自定义的值覆盖
分离YARN Session
如果不想让Flink YARN客户端一直运行,那么也可以启动一个分离的YARN session。参数:-d or --detached
在这种情况下,Flink YARN客户端断只会提交Flink任务到集群,然后关闭。注意,这种情况下,用Flink来stop YARN Session是不可能的
连接到一个存在的Session:
下面的命令连接到一个运行的Flink YARN session
./bin/yarn-session.sh -id application_1463870264508_0029
submit job to flink
./bin/flink
Run a single Flink Job on YARN
上面内容描述了如何在Hadoop YARN环境中启动FLink 集群。也可以启动Flink任务执行单个Job
./bin/flink run -m yarn-cluster -yn2 ./examples/batch/WordCount.jar
User jars & Classpath
yarn.per-job-cluster.include-user-jar
Recovery behavior of Flink on YARN
Flink’s YARN client has the following configuration parameters to control how to behave in case of container failures. These parameters
can be set either from the conf/flink-conf.yaml or when starting the YARN session, using -D parameters
yarn.reallocate-failed : 控制 Flink是否应该重新分配失败的TaskManager容器,默认true
yarn.maximum-failed-containers : ApplicationMaster接收container失败的最大次数,默认是TaskManager的次数(-n的值)
yarn.application-attempts : ApplicationMaster尝试次数。如果这个值为1(默认),那么当Application Master失败时,整个YARN session就会失败。更高的值是指ApplicationMaster重新启动的次数
Flink and YARN 任务提交流程
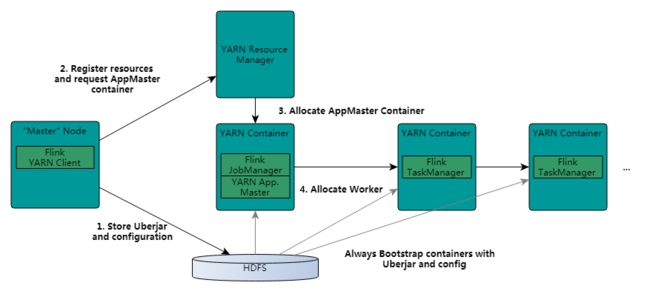
YARN客户端需要访问Hadoop配置来连接YARN资源管理器和HDFS。它使用下面的策略来确定Hadoop的配置:
YARN_CONF_DIR,HADOOP_CONF_DIR,HADOOP_CONF_PATH.其中一个变量被设置,就能读取配置
如果上面的策略失败(在正确的yarn 设置中不应该出来这种情况),客户端使用HADOOP_HOME环境变量。如果设置了,那么客户端就会尝试访问$HADOOP_HOME/tect/hadoop
step1 : 当启动一个新的Flink YARN session时,客户端首先检查资源(container和memory)是否可用。然后,上传一个包含Flink和配置的jar包到HDFS上。
客户端请求(step 2)YARN container启动ApplicationMaster(step 3).由于客户端将配置和jar文件注册到容器,在特定机器上运行的YARN的NodeManager将负责准备container(例如下载文件)。一旦完成,ApplicationMaster就被启动了
JobManager和ApplicationMaster运行在同一个container上。一旦他们被成功启动,AM就知道JobManager的地址(AM它自己所在的机器)。它就会为TaskManager生成一个新的Flink配置文件(他们就可以连接到JobManager)。这个配置文件也被上传到HDFS上。此外,AM容器也提供了Flink的web服务接口。YARN所分配的所有端口都是临时端口,这允许用户并行执行多个Flink
session。
最后,AM开始为Flink的任务TaskManager分配container,它将从HDFS加载jar文件和修改的配置文件。一旦这些步骤完成,Flink就准备好接口Job的提交了
参考资料:
https://ci.apache.org/projects/flink/flink-docs-release-1.4/ops/deployment/cluster_setup.html
https://ci.apache.org/projects/flink/flink-docs-release-1.4/ops/deployment/yarn_setup.html