比赛开始的时间与我所要面临的开题有一定的时间冲突, 因此选择一个最为简单(个人认为), 比较容易快点出结果的题目--汽车工况的建立.
主要的工作: 进行汽车工况的聚类划分(本文主要以此为主)
本文的结构为:题目要求-基本报告-实现代码
题目要求:
汽车行驶工况(Driving Cycle)又称车辆测试循环,是描述汽车行驶的速度-时间曲线(如图1、2,一般总时间在1800秒以内,但没有限制标准,图1总时间为1180秒,图2总时间为1800秒),体现汽车道路行驶的运动学特征,是汽车行业的一项重要的、共性基础技术,是车辆能耗/排放测试方法和限值标准的基础,也是汽车各项性能指标标定优化时的主要基准。目前,欧、美、日等汽车发达国家,均采用适应于各自的汽车行驶工况标准进行车辆性能标定优化和能耗/排放认证。
本世纪初,我国直接采用欧洲的NEDC行驶工况(如图1)对汽车产品能耗/排放的认证,有效促进了汽车节能减排和技术的发展。近年来,随着汽车保有量的快速增长,我国道路交通状况发生很大变化,政府、企业和民众日渐发现以NEDC工况为基准所优化标定的汽车,实际油耗与法规认证结果偏差越来越大,影响了政府的公信力(譬如对某型号汽车,该车标注的工信部油耗6.5升/100公里,用户体验实际油耗可能是8.5-10升/100公里)。另外,欧洲在多年的实践中也发现NEDC工况的诸多不足,转而采用世界轻型车测试循环(WLTC,如图2)。但该工况怠速时间比和平均速度这两个最主要的工况特征,与我国实际汽车行驶工况的差异更大。作为车辆开发、评价的最为基础的依据,开展深入研究,制定反映我国实际道路行驶状况的测试工况,显得越来越重要。
另一方面,我国地域辽广,各个城市的发展程度、气候条件及交通状况的不同,使得各个城市的汽车行驶工况特征存在明显的不同。因此,基于城市自身的汽车行驶数据进行城市汽车行驶工况的构建研究也越来越迫切,希望所构建的汽车行驶工况与该市汽车的行驶情况尽量吻合,理想情况下是完全代表该市汽车的行驶情况(也可以理解为对实际行驶情况的浓缩),目前北京、上海、合肥等都已经构建了各城市的汽车行驶工况。
为了更好地理解构建汽车行驶工况曲线的重要性,以某型号汽车油耗为例,简单说明标注的工信部油耗是如何测试出来?标注的工信部油耗并不是该型号汽车在实际道路上的实测油耗,而是基于国家标准(如《GB27840-2011重型商用车辆燃料消耗量测量方法》),在实验室里根据汽车行驶工况曲线,按照一定的标准,经检测、计算得出。由此可见,标注的工信部油耗是否与实际油耗相吻合,与汽车行驶工况曲线有密切关系。

图1 欧洲NEDC工况
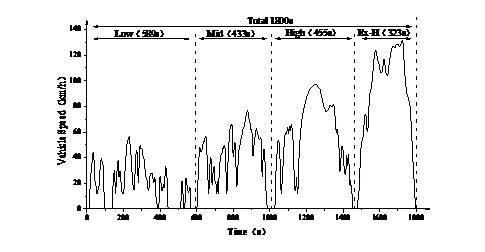
图2. 世界WLTC工况
二、目标的提出
在上述背景下,请根据附件(3个数据文件,每个数据文件为同一辆车在不同时间段内所采集的数据)所提供的某城市轻型汽车实际道路行驶采集的数据(采样频率1Hz),构建一条能体现参与数据采集汽车行驶特征的汽车行驶工况曲线(1200-1300秒),该曲线所体现的汽车运动特征(如平均速度、平均加速度等)能代表所采集数据源的相应特征,两者间的误差越小,说明所构建的汽车行驶工况的代表性越好。
三、解决的问题
1.数据预处理
由汽车行驶数据的采集设备直接记录的原始采集数据往往会包含一些不良数据值,不良数据主要包括几个类型:
(1) 由于高层建筑覆盖或过隧道等,GPS信号丢失,造成所提供数据中的时间不连续;
(2) 汽车加、减速度异常的数据(普通轿车一般情况下:0至100km/h的加速时间大于7秒,紧急刹车最大减速度在7.5~8 m/s2);
(3) 长期停车(如停车不熄火等候人、停车熄火了但采集设备仍在运行等)所采集的异常数据。
(4) 长时间堵车、断断续续低速行驶情况(最高车速小于10km/h),通常可按怠速情况处理。
(5) 一般认为怠速时间超过180秒为异常情况,怠速最长时间可按180秒处理。
请设计合理的方法将上述不良数据进行预处理,并给出各文件数据经处理后的记录数。
2.运动学片段的提取
运动学片段是指汽车从怠速状态开始至下一个怠速状态开始之间的车速区间,如图3所示(基于运动学片段构建汽车行驶工况曲线是日前最常用的方法之一,但并不是必须的步骤,有些构建汽车行驶工况曲线的方法并不需要进行运动学片段划分和提取)。请设计合理的方法,将上述经处理后的数据划分为多个运动学片段,并给出各数据文件最终得到的运动学片段数量。
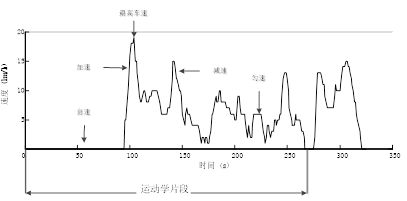
图3 运动学片段的定义
3. 汽车行驶工况的构建
请根据上述经处理后的数据,构建一条能体现参与数据采集汽车行驶特征的汽车行驶工况曲线(1200-1300秒),该曲线的汽车运动特征能代表所采集数据源(经处理后的数据)的相应特征,两者间的误差越小,说明所构建的汽车行驶工况的代表性越好。要求:
(1)科学、有效的构建方法(数学模型或算法,特别鼓励创新方法,如果采用已有的方法,必须注明来源);
(2)合理的汽车运动特征评估体系(至少包含但不限于以下指标:平均速度(km/h)、平均行驶速度(km/h)、平均加速度(m/ )、平均减速度(m/ )、怠速时间比(%)、加速时间比(%)、减速时间比(%)、速度标准差(km/h)、加速度标准差(m/ )等);
(3)按照你们所构建的汽车行驶工况及汽车运动特征评估体系,分别计算出汽车行驶工况与该城市所采集数据源(经处理后的数据)的各指标(运动特征)值,并说明你们所构建的汽车行驶工况的合理性。
基本报告:
模型假设
通过调研文献和对行驶工况构建问题的分析做出如下假设条件:
1、GPS及其他随车设备记录值的有效性。(即在非故障情况下,测量值即为准确值)
2、时间不连续片段能够通过周围时间连续片段进行插值得到。
3、时间长度小于20s或大于700s的运动学片段对行驶工况的构建无贡献。
4、建立的特征参数能够准确的反映行驶工况的运动学特征。
5、经过预处理之后的数据是无噪的。
6、在网络优选片段过程中,聚类损失函数和重建损失函数对目标泛函的贡献度相同。
模型建立
基本理论
(1)IDEC算法
无监督聚类是大数据分析和机器学习的热点问题之一。相比较传统的聚类方法,基于深度学习网络的聚类方法有着分类能力强,运用广泛的优点。IDEC通过定义聚类损失来同时更新网络和聚类中心参数,将自动编码器嵌入到深度聚类算法(DEC)能够结合局部特征学习主要特征来协同聚类,有效地提高了算法的效率和有效性。IDEC使用重建损失和聚类损失来定义目标泛函:
(4-3-1)
其中为重建损失函数,为聚类损失函数,为控制系数。当时,目标函数退化为传统DEC目标函数,也就是算法不再考虑重建损失函数。的定义和DEC方法类似:
(4-3-2)
其中为嵌入点和聚类中心的相似程度,可以通过学生T分布来定义,而目标的分布可以通过来定义:
(4-3-3)
相比较DEC需要对解码器弃置并对编码器微调,IDEC定义了重建损失来实现聚类:
(4-3-4)
其中,和分别为编码和解码函数。重建损失函数的建立来源于自编码器,这种方法可以保持数据生成分布的局部结构。
对于目标函数(4-3-1)的优化可以采用小批量随机梯度下降(SGD)和反向传播来实现。总体来说,在每一次迭代中需要对三种参数进行优化:自编码的权重,聚类中心和目标分布。
首先固定目标分布,计算聚类损失函数关于嵌入点和聚类中心的的梯度,根据SGD原理,使用小批量样点数和学习率来对聚类中心,编码权重和解码权重进行更新,而目标分布的的更新只需要每T次更新一次其标签值。
(2)T-SNE降维
T分布随机邻近嵌入(T-SNE)是一种基于信息论的非线性流行的学习方法,能从高位采样数据恢复低维流行结构,以实现维数降低即数据可视化,是目前高维数据降维可视化方法中效果最好的一种。T-SNE算法的核心思想是将数据点之间的相似属性转化为概率。
原始空间中的相似度由高斯联合概率表示:
(4-3-5)
嵌入空间的相似度由“学生T分布”表示:
(4-3-6)
通过原始空间和嵌入空间的联合概率的Kullback-Leibler(KL)散度来评估可视化效果的好坏:
(4-3-7)
(3)K-means聚类
聚类分析又称为群分析,是研究(样品或变量)分类问题的一种多元统计方法,旨在使类间对象的同质性最大化和类与类间对象的异质性最大化。K-means 聚类法具有能对大型数据集进行高效分类的优势,因而被广泛使用在数据分析与处理中。
K-Means算法的思想很简单,对于给定的样本集,按照样本之间的距离大小,将样本集划分为K个簇。让簇内的点尽量紧密的连在一起,而让簇间的距离尽量的大。
假设簇划分为(),则目标函数可以用最小化平方误差来建立:
(4-3-8)
其中是簇的均值向量,可以表述为:0
(4-3-9)
K-Means通过启发式算法优化目标函数(4-3-8),最终得到比较优质的类别。
4.3.2.2 模型建立
根据上述理论建立目标泛函如下:
(4-3-10)
为输入的运动学片段,经过编码函数得到的能够表征运动学片段的特征向量,称之为网络特征参数,经过解码函数得到重构之后的运动学片段。通过建立输入和重构输出之间的二范数来定义重构损失函数:
(4-3-11)
通过IDEC网络可以得到表征运动学片段的网络特征参数,特征向量的维度为10,因此网络特征参数的数量为10。将网络筛选出来的10的网络特征参数同之前计算的9个特征参数融合,通过S-TNE降维方法获得能够表征的运动学片段3个成分。借助于K-means聚类算法对三个成分进行聚类可以得到4个聚类簇,使用Silhouette系数来定义聚类损失函数
(4-3-12)
其中为样本与同一类别中其他点之间的平均距离,为样本与下一个距离最近的簇中所有其他点之间的平均距离。以此就可以建立完整的目标泛函,并借助于神经网络的反向传播算法更新IDEC网络中的权值。多次迭代直至上述的目标泛函收敛或达到要求。
根据上述模型建立,给出基于IDEC网络构建汽车行驶工况曲线的流程图:
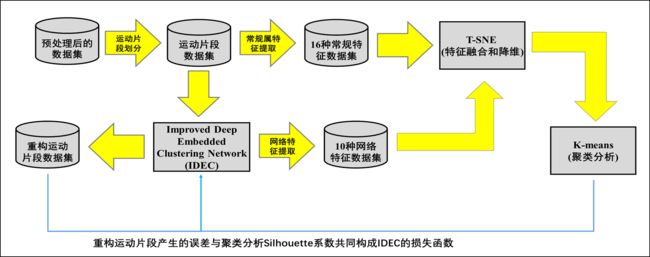
图4-3-1 基于IDEC网络的汽车行驶工况曲线工况构建
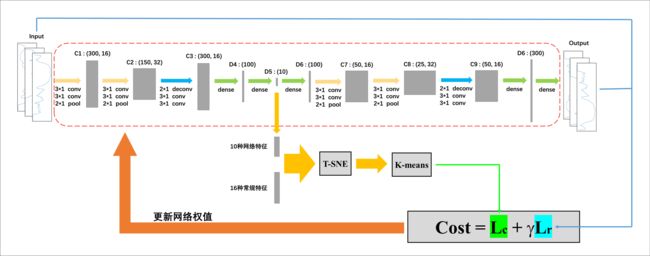
图4-3-1 基于IDEC网络的汽车行驶工况曲线工况构建
实现代码:
可以参见: https://github.com/cui-xiaoang96/2019-China-GMCM