深度学习入门笔记(十一):深度学习数据读取
专栏——深度学习入门笔记
声明
1)该文章整理自网上的大牛和机器学习专家无私奉献的资料,具体引用的资料请看参考文献。
2)本文仅供学术交流,非商用。所以每一部分具体的参考资料并没有详细对应。如果某部分不小心侵犯了大家的利益,还望海涵,并联系博主删除。
3)博主才疏学浅,文中如有不当之处,请各位指出,共同进步,谢谢。
4)此属于第一版本,若有错误,还需继续修正与增删。还望大家多多指点。大家都共享一点点,一起为祖国科研的推进添砖加瓦。
文章目录
- 专栏——深度学习入门笔记
- 声明
- 深度学习入门笔记(十一):深度学习数据读取
- 1、Mini-batch 梯度下降
- 2、数据读取之 h5py
- 3、数据读取之 TFRecords
- 4、六种 Python 图像库读取
- 推荐阅读
- 参考文章
深度学习入门笔记(十一):深度学习数据读取
1、Mini-batch 梯度下降
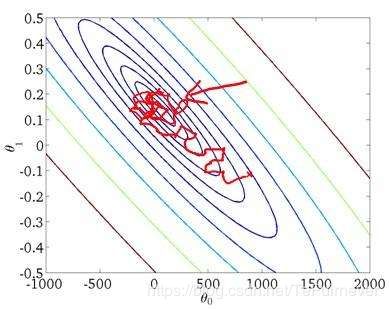
机器学习的应用是一个高度依赖经验的过程,伴随着大量迭代的过程,需要训练诸多模型,才能找到合适的那一个,所以,优化算法能够帮助你快速训练模型。
其中一个难点在于,虽然深度学习在大数据领域的效果不错,但是如果利用一个巨大的数据集来训练神经网络的话,训练速度往往很慢,比如我现在跑一次训练,需要一天一夜。。。因此,你会发现,使用快速的、好用的优化算法,能够大大提高你和团队或者实验室的效率。
那么,首先来谈谈 mini-batch 梯度下降法,这应该是大部分人第一个学习的数据读取方式。

之前学过,向量化(深度学习入门笔记(四):向量化)能够有效地对所有 m m m 个样本进行计算,允许处理整个训练集,而无需某个明确的公式。所以如果要把训练样本放大巨大的矩阵 X X X 当中去, X = [ x ( 1 ) x ( 2 ) x ( 3 ) … … x ( m ) ] X= \lbrack x^{(1)}\ x^{(2)}\ x^{(3)}\ldots\ldots x^{(m)}\rbrack X=[x(1) x(2) x(3)……x(m)], Y Y Y 也是如此, Y = [ y ( 1 ) y ( 2 ) y ( 3 ) … … y ( m ) ] Y= \lbrack y^{(1)}\ y^{(2)}\ y^{(3)}\ldots \ldots y^{(m)}\rbrack Y=[y(1) y(2) y(3)……y(m)],所以 X X X 的维数是 ( n x , m ) (n_{x},m) (nx,m), Y Y Y 的维数是 ( 1 , m ) (1,m) (1,m)。
向量化能够相对较快地处理所有 m m m 个样本。但是如果 m m m 很大的话,处理速度仍然缓慢。比如, m m m 是500万或5000万或者更大的一个数,在对整个训练集执行梯度下降法时,你要做的是,必须处理整个训练集,然后才能进行一步梯度下降法,然而这个时候你需要再重新处理500万个训练样本,才能进行下一步梯度下降法,所以如果在处理完整个500万个样本的训练集之前,先让梯度下降法处理一部分,算法的速度会不会更快?准确地说,这是你可以做的一些事情!
我们可以把训练集分割为小一点的子集训练,这些子集被取名为 mini-batch,假设每一个子集中只有1000个样本,那么把其中的 x ( 1 ) x^{(1)} x(1) 到 x ( 1000 ) x^{(1000)} x(1000) 取出来,将其称为第一个子训练集,也叫做 mini-batch,然后再取出接下来的1000个样本,从 x ( 1001 ) x^{(1001)} x(1001) 到 x ( 2000 ) x^{(2000)} x(2000),然后再取1000个样本,…以此类推。
接下来把 x ( 1 ) x^{(1)} x(1) 到 x ( 1000 ) x^{(1000)} x(1000) 称为 X { 1 } X^{\{1\}} X{1}, x ( 1001 ) x^{(1001)} x(1001) 到 x ( 2000 ) x^{(2000)} x(2000) 称为 X { 2 } X^{\{2\}} X{2},等等…如果训练样本一共有500万个,每个 mini-batch 都有1000个样本,也就是说,你有5000个 mini-batch,因为5000乘以1000就是5000万。有5000个 mini-batch,就意味着最后得到的是 X { 5000 } X^{\left\{ 5000 \right\}} X{5000}。
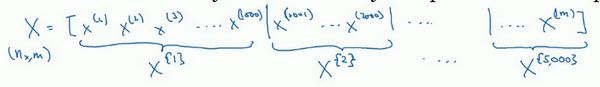
对 Y Y Y 也要进行相同处理,也要相应地拆分 Y Y Y 的训练集,所以这是 Y { 1 } Y^{\{1\}} Y{1},然后从 y ( 1001 ) y^{(1001)} y(1001) 到 y ( 2000 ) y^{(2000)} y(2000),这个叫 Y { 2 } Y^{\{2\}} Y{2},一直到 Y { 5000 } Y^{\{ 5000\}} Y{5000}。
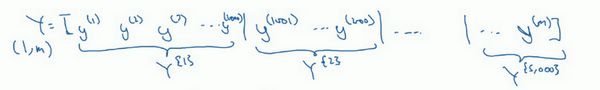
mini-batch 的数量 t t t 组成了 X { t } X^{\{ t\}} X{t} 和 Y { t } Y^{\{t\}} Y{t},这就是1000个训练样本,包含相应的输入输出对。
来一起确定一下符号, x ( i ) x^{(i)} x(i) 是第 i i i 个训练样本, z [ l ] z^{\lbrack l\rbrack} z[l] 表示神经网络中第 l l l 层的 z z z 值,大括号 t {t} t 代表不同的 mini-batch。如果 X { 1 } X^{\{1\}} X{1} 是一个有1000个样本的训练集,或者说是1000个样本的 x x x 值,所以维数应该是 ( n x , 1000 ) (n_{x},1000) (nx,1000), X { 2 } X^{\{2\}} X{2} 的维数应该是 ( n x , 1000 ) (n_{x},1000) (nx,1000),以此类推,所有的子集维数都是 ( n x , 1000 ) (n_{x},1000) (nx,1000),而这些( Y { t } Y^{\{ t\}} Y{t})的维数都是 ( 1 , 1000 ) (1,1000) (1,1000)。
其实这个词有一点拗口,不过如果你了解了意思之后,就明白这个词的作用了。
batch 是批量的意思,mini 就是小的意思,现在再来解释一下这个算法的名称,batch 梯度下降法指的是之前讲过的梯度下降法算法,就是同时处理整个训练集,这个名字就是来源于能够同时看到整个 batch 训练集的样本被处理,这个名字不怎么样,但就是这样叫它,所以记住就行。相比之下,mini-batch 梯度下降法,指的是每次同时处理的单个的 mini-batch X { t } X^{\{t\}} X{t} 和 Y { t } Y^{\{ t\}} Y{t},而不是同时处理全部的 X X X 和 Y Y Y 训练集,也就是小批量数据的梯度下降法。
那么究竟 mini-batch 梯度下降法的原理是什么?
在训练集上运行 mini-batch 梯度下降法,你运行 for t=1……5000,因为有5000个各有1000个样本的组,在 for 循环里要做得基本就是对 X { t } X^{\{t\}} X{t} 和 Y { t } Y^{\{t\}} Y{t} 执行一步梯度下降法,就好比现在有一个拥有1000个样本的训练集,而且假设你已经很熟悉一次性处理完的方法,要用向量化去一次性处理1000个样本,这就是其中一个过程,然后共计执行5000次,这样就算是完成了一个 mini-batch。
现在你应该大概了解了什么是 mini-batch,我们来详细地说一下整个过程。
首先对输入也就是 X { t } X^{\{ t\}} X{t},执行前向传播,然后执行 z [ 1 ] = W [ 1 ] X + b [ 1 ] z^{\lbrack 1\rbrack} =W^{\lbrack 1\rbrack}X + b^{\lbrack 1\rbrack} z[1]=W[1]X+b[1],之前只有一个数据,但是现在正在处理整个训练集,即第一个 mini-batch,故 X X X 变成了 X { t } X^{\{ t\}} X{t},即 z [ 1 ] = W [ 1 ] X { t } + b [ 1 ] z^{\lbrack 1\rbrack} = W^{\lbrack 1\rbrack}X^{\{ t\}} + b^{\lbrack1\rbrack} z[1]=W[1]X{t}+b[1],然后执行 A [ 1 ] k = g [ 1 ] ( Z [ 1 ] ) A^{[1]k} =g^{[1]}(Z^{[1]}) A[1]k=g[1](Z[1]),之所以用大写的 Z Z Z 是因为这是一个向量内涵,…以此类推,直到 A [ L ] = g [ L ] ( Z [ L ] ) A^{\lbrack L\rbrack} = g^{\left\lbrack L \right\rbrack}(Z^{\lbrack L\rbrack}) A[L]=g[L](Z[L]),这就是网络的输出,即模型的预测值。注意这里需要用到一个向量化的执行命令,是一次性处理1000个而不是500万个数据样本。接下来计算损失成本函数 J J J,因为子集规模是1000, J = 1 1000 ∑ i = 1 l L ( y ^ ( i ) , y ( i ) ) J= \frac{1}{1000}\sum_{i = 1}^{l}{L(\hat y^{(i)},y^{(i)})} J=10001∑i=1lL(y^(i),y(i)),说明一下,这( L ( y ^ ( i ) , y ( i ) ) L(\hat y^{(i)},y^{(i)}) L(y^(i),y(i)))指的是来自于 mini-batch X { t } X^{\{ t\}} X{t} 和 Y { t } Y^{\{t\}} Y{t} 中的样本,这一块一定不要弄混了,是完成一个 batch 内的数据训练过程,即1000。
如果用到了正则化(深度学习入门笔记(十):正则化), J = 1 1000 ∑ i = 1 l L ( y ^ ( i ) , y ( i ) ) + λ 21000 ∑ l ∣ ∣ w [ l ] ∣ ∣ F 2 J =\frac{1}{1000}\sum_{i = 1}^{l}{L(\hat y^{(i)},y^{(i)})} +\frac{\lambda}{2 1000}\sum_{l}^{}{||w^{[l]}||}_{F}^{2} J=10001∑i=1lL(y^(i),y(i))+21000λ∑l∣∣w[l]∣∣F2,因为这是一个 mini-batch 的损失,所以将 J J J 损失记为上角标 t t t,放在大括号里( J { t } = 1 1000 ∑ i = 1 l L ( y ^ ( i ) , y ( i ) ) + λ 21000 ∑ l ∣ ∣ w [ l ] ∣ ∣ F 2 J^{\{t\}} = \frac{1}{1000}\sum_{i = 1}^{l}{L(\hat y^{(i)},y^{(i)})} +\frac{\lambda}{2 1000}\sum_{l}^{}{||w^{[l]}||}_{F}^{2} J{t}=10001∑i=1lL(y^(i),y(i))+21000λ∑l∣∣w[l]∣∣F2)。到这里了,你应该会注意到,我们做的一切都是那么的似曾相识,其实跟之前执行梯度下降法如出一辙,除了现在的对象不是 X X X, Y Y Y,而是 X { t } X^{\{t\}} X{t} 和 Y { t } Y^{\{ t\}} Y{t}。
接下来,执行反向传播来计算 J { t } J^{\{t\}} J{t} 的梯度,只是使用 X { t } X^{\{ t\}} X{t} 和 Y { t } Y^{\{t\}} Y{t},然后更新加权值, W W W 实际上是 W [ l ] W^{\lbrack l\rbrack} W[l],更新为 W [ l ] : = W [ l ] − a d W [ l ] W^{[l]}:= W^{[l]} - adW^{[l]} W[l]:=W[l]−adW[l],对 b b b 做相同处理, b [ l ] : = b [ l ] − a d b [ l ] b^{[l]}:= b^{[l]} - adb^{[l]} b[l]:=b[l]−adb[l]。这是使用 mini-batch 梯度下降法训练样本的一步,写下的代码也可被称为进行 一代(1 epoch) 的训练,一代的意思是只是一次遍历了训练集。
使用 batch 梯度下降法,一次遍历训练集只能让你做一个梯度下降,使用 mini-batch 梯度下降法,一次遍历训练集,能让你做5000个梯度下降。mini-batch 梯度下降法比 batch 梯度下降法运行地更快,所以几乎每个研习深度学习的人在训练巨大的数据集时都会用到,希望你可以好好理解理解。
2、数据读取之 h5py
HDF(Hierarchical Data Format)指一种为存储和处理大容量科学数据设计的文件格式及相应库文件。其中当前比较流行的版本是 HDF5。它拥有一系列的优异特性,使其特别适合进行大量科学数据的存储和操作,如支持非常多的数据类型,灵活,通用,跨平台,可扩展,高效的 I/O 性能,支持几乎无限量(高达 EB)的单文件存储等,详见其官方介绍:https://support.hdfgroup.org/HDF5/ 。
HDF5 三大要素:
- hdf5 files: 能够存储两类数据对象 dataset 和 group 的容器,其操作类似 python 标准的文件操作;File 实例对象本身就是一个组,以 / 为名,是遍历文件的入口
- dataset(array-like): 可类比为 Numpy 数组,每个数据集都有一个名字(name)、形状(shape) 和类型(dtype),支持切片操作
- group(folder-like): 可以类比为 字典,它是一种像文件夹一样的容器;group 中可以存放 dataset 或者其他的 group,键就是组成员的名称,值就是组成员对象本身(组或者数据集)
Python 中有一系列的工具可以操作和使用 HDF5 数据,其中最常用的是 h5py 和 PyTables。目前比较火热的pytorch就可以使用 h5py 进行数据的读取,这样相较于 minibatch 也会更好。
入门的建议博客是这个——深度学习之10分钟入门h5py,如果你比较迷惑的话,就把它当成是一个存储数据的工具即可,可以类比于Excel表格存储数据一样。

3、数据读取之 TFRecords
关于 TensorFlow 读取数据的方法,官网给出了三种方法:
- 供给数据: 在 TensorFlow 程序运行的每一步,让 Python 代码来供给数据。
- 从文件读取数据: 在 TensorFlow 图的起始,建立一个输入管线从文件中读取数据。
- 预加载数据: 在 TensorFlow 图中定义常量或变量来保存所有数据(仅适用于数据量比较小的情况)。
输入数据集一般被存储在各种类型的文件系统中,根据文件系统类型和输入数据集大小,有两种不同的数据读取方法:
- 大数据集(如 ImageNet )一般由大量数据文件构成,因为数据规模太大,所以无法一次性全部加载到内存中,因为太耗内存,这个时候最好使用 TensorFlow 提供的队列
queue,也就是第二种方法从文件读取数据。 - 小数据集(如 MNIST )可能仅包含一个文件,因此用户可以在模型训练开始前一次性地将其加载到内存处理,然后再分
batch输入网络进行训练,也就是第三种方法预加载数据。
小数据集时多采用 minibatch,而大数据集时则多采用 TFRecords 格式。
入门的建议是这个博客——TensorFlow学习笔记之30分钟学会 TFRecords 格式高效处理数据,如果你还是很迷糊的话,只要记得 TFRecords 格式和 h5py 格式是类似的效用即可。
4、六种 Python 图像库读取
主流Python图像库有:
-
opencv——cv2.imread
OpenCV作为最常用的图像处理库,实现了图像处理和计算机视觉方面的很多通用算法,可以说是很全面和强大了。如果你只想掌握一个图像库的话,OpenCV是你的最佳选择。 -
PIL——PIL.Image.open
PIL即Python Imaging Library,也即为我们所称的Pillow,已经是 python 平台事实上的图像处理标准库了。PIL功能非常强大,但API却非常简单易用。它比OpenCV更为轻巧,正因如此,它深受大众的喜爱。 -
matplotlib——matplotlib.image.imread
Matplotlib是 python 的 2D 绘图库,它以各种硬拷贝格式和跨平台的交互式环境生成出版质量级别的图形。 它可与NumPy一起使用,提供了一种有效的MatLab开源替代方案。 -
scipy.misc——scipy.misc.imread
Scipy是一个 python 中用于进行科学计算的工具集,有很多功能,如计算机统计学分布、信号处理、计算线性代数方程等。 -
skimage——skimage.io.imread
skimage对scipy.ndimage进行了扩展,提供了更多的图片处理功能,是基于 python 脚本语言开发的数字图片处理包。 -
Tensorflow——tf.image.decode
tf.image.decode函数可以对图像进行很多操作,如放大缩小,旋转,平移,等等。
详细的实例和代码可以看这个博客——你不能不知道的六种 Python 图像库的图片读取方法总结。
推荐阅读
- 深度学习入门笔记(一):深度学习引言
- 深度学习入门笔记(二):神经网络基础
- 深度学习入门笔记(三):求导和计算图
- 深度学习入门笔记(四):向量化
- 深度学习入门笔记(五):神经网络的编程基础
- 深度学习入门笔记(六):浅层神经网络
- 深度学习入门笔记(七):深层神经网络
- 深度学习入门笔记(八):深层网络的原理
- 深度学习入门笔记(九):深度学习数据处理
- 深度学习入门笔记(十):正则化
- 深度学习入门笔记(十一):深度学习数据读取
参考文章
- 吴恩达——《神经网络和深度学习》视频课程