------------------------------------------------------1030------------------------------------------------------
物联网工程专业卓工实习也有一阵子了,一部分同学已经实习完回校了,而我。。还在苦逼的奋斗之中。
可以说,卓工实习也有好有坏吧。累,是必然的。每天都要骑车离开学校,晨兴理荒秽,带月荷锄归啊。对于考研的同学,当然是有些耗时间了,不过有些公司还算好,可以挂名,也可以推迟实习时间,只要说明情况就OK。而对于工作的同学,这正是积累工作经验,理论联系实际的好机会,可以趁此机会,向公司的同事们请教。而还有一种是推免或者出国,推免的这个时候已经没啥事了,实习一下可以锻炼锻炼自己的能力,但是这个可能和你今后的研究方向不匹配,就只能权当积累丰富的社会经验和实践经验了,当然也可以学到一些的。出国的可能还需要准备雅思或者托福等语言成绩,这时候肯定会有点辛苦。
这个实习,和上课不同的是,真是一整天都得待在公司,就没有了自由!时间完全不是自己的了。
我所在的实习公司是威莱斯电子,主要是从事计算机视觉研发工作,下面就细细讲讲我们在公司到底干了些什么。
来公司的第一周,先是给了我们一堆Matlab代码,每人挑一个,让我们先看,一周时间到时候再进行汇报,讲解算法的效果和优劣,是否具有实用价值。后来由于夏令营,于是就产生了一个gap。休息了三周,暑假继续,我记得是7.31开始正式实习的。
开始之后,我和另外两位同学一同完成一个所谓的“内部项目”——人脸识别与疲劳检测。当时我是负责人脸识别,而且负责人王工跟我说这个项目需要有一个人从头到尾负责,那个人就是——我!那也真是吓着了,也就是我来负责?!这不是开玩笑吧。。。后来我拿到了一台笔记本电脑,随便我怎么折腾。
后来我听说,这个第一周的任务其实就是摸摸底,来评估一下我们的能力,看看大家到底是什么水平,以后可以布置相应的任务。当然也顺便为公司做事了,看看这些代码熟悉一下cv,这里代码主要的研究对象是人,用来进行人体区域分割,譬如割出头部,躯干,手之类的,这些都是用到一些人体的几何约束,结合了深度数据(tof出来的是深度数据)。
正式开始的第一周实习任务是调研,寻找一个好的(开源)模型、算法来完成人脸识别,起初我一直在找基于PCA、KNN的方法,后来王工提点我们说不要拘泥于普通的机器学习,也可以看看深度学习的框架和模型,不要害怕啊,后来循着这条路找到的是openface(卡内基梅隆大学的Brandon Amos主导研究的),开始我们还是觉得C语言比较容易上手,所以试着调了VS,装了之后配了Opencv,接着感觉太慢了,在学长的指导下,装了CUDA(调用GPU给运行加速)后来,,,cuda并没有安装成功!然后我们看到他的很多demo都是基于python的,所以我们就决定跑python算了,但公司高层都觉得python不方便移植,还是C++稳妥。。。不过我们还是在学长的“怂恿”之下用起了python,因为他比较喜欢脚本语言。用python之前需要安装ubuntu系统。于是就给笔记本装了双系统,也是不会,以前我居然都不会做引导,现在给U盘装引导了ubuntu,很快就上手装系统了,当然这中间也历经曲折,费了一波劲,UEFI的机器好像不好直接装什么的,要从开机时的boot进U盘启动!安装好ubuntu,就按着步骤一步步配环境了,opencv,cuda,cnn,dnn,各种各样的python安装包(包括好多机器学习的包)。在遇到问题时还需要再配,不过ubuntu下安装python的包也很容易了,一条指令pip install …就可以了。
------------------------------------今天就先写到这儿了。有空继续------------------------------------
----------------------------------------------------------1031---------------------------------------------------
装完ubuntu我们就开始在电脑上瞎折腾了,安装了py的各种包。。然后觉得openface还是可行的,就在Git上下载了相关组件,里面有包含demo,但是也不完全符合我们的要求,demo都是python写的调用了其中的包和库,所以就开始学一些python语言,python是一种脚本语言,比较好上手,和matlab比较类似了,方便快捷,容易出一些统计数据。但是其最大的缺点是对齐很严格,一不留神就容易出错还找不到原因!之后我们按照网上的教程,进行了第一次人脸识别,其实这个过程就是,我们拍摄一系列图片作为训练集,每个图片一个文件夹,然后调用一个训练好的神经网络,对于每个文件夹中的图片,都会出一组128维的特征作为这个标签的特征值,获取图像后,再将当前帧输入神经网络同样计算出特征,再调用SVM分类器进行分类,最终得到识别结果和置信度。
完成这个过程后,我们开始研究了头部姿态估计和疲劳检测,都查了很多资料,很多是基于landmark,而这个也是Dlib库里正好有的,他是采用ERT级联回归树,一步步将初始的shape与ground truth之间进行逼近和回归。后来都是在python下面实现了,基本都是调用opencv+dlib中的一些源代码。头部姿态估计我们主要是通过已经标注好的标准世界坐标系中的关键点和二维中的landmark点进行标定,然后根据一系列转换公式,得到偏转的角度(roll,pitch,yaw三个指标)主要存在的问题是晃的很严重,结果数据抖动很剧烈,后来。。。一位同事来了之后进行了改进,当然这个是后话了。
关于疲劳检测,我们查阅相关文献,发现主要和眼睛、嘴巴的状态有关,一个是眯着眼困了,一个是打哈欠疲了。所以主要都是两个指标,一个是眼睛(嘴巴)的睁开(张开)度,一个是持续时长,问题看上去很简单,但是也是很不稳定啊。
暑假的最后一周,我负责将人脸识别系统与ipad进行HMI对接,识别之后通过UDP数据报发送指令到IPAD。这里我们进行了一个小优化,通过连续若干帧的检测结果去判断,若连续9帧中6帧都是判定为A,我们才发送识别结果A,否则一直循环识别,直到满足条件,从而降低误判率,这样带来的问题是时间上可能略大。
我干完暑假的这段时间,就离开去学校继续上课了。这中间我也和坚守公司实习的同学有过交流,据说是人脸识别中需要添加陌生人脸检测的功能。现有的算法仅仅能对库中人脸有效识别,而且还有时候会出现认错的情况,而陌生人就更难了,因为。。这个阈值不好把握啊!因为这里算法中自带的置信度(confidence)他有时候在认错人时也会很高,比如把Z认错为W同时也具有较高的置信度!那么这个问题如何解决呢?
另起一段再说呗,我们尝试在网上搜索开集人脸识别,国外有做。对于这种问题,无非从两个方面优化,一是特征提取,是否有更优的提取方式(训练方式,如何组合样本数据),或者更好的特征来(特征组合,归一化?)表示这些样本数据,二是分类器的方面,即已经提取到很好的特征,那么我们怎么将其进行归类,新的测试样例到底是属于哪一类。所以,一种思想是把库内人作为正样本,好多库外人作为一个负样本,进行训练,这样先区别他是库内还是库外,在库内再进行进一步识别。基于这种方案,我们还可以对样本进行处理比如库内的A,可用5张A和一个任意库外人脸,B用5张B和一个任意库外人脸,这样进行训练,然后还有一个单独的库外人脸。最后进行分类。当然,我们还可以使用Adaboost多弱分类器融合提升学习的方案,他的思想是训练若干个弱分类器(只要分类正确率大于50%)每轮迭代过程都这些分类器进行评估,某个样本分类错了,则对其加重权重,重新训练,直到分类误差很小,从理论上这种方案,可以将分类误差降到0。除了这样的学习方法,另一种思想是采用检索的方法,因为demo中本是用SVM(也就是分类器的方法,事实上多分类SVM也是决策树的形式,本质上是多个SVM叠加而成,因为每个SVM分类器都只能解决二分类问题),检索的办法关键在于距离的选取,距离有哈明距离、欧氏距离、余弦距离等等,我们尝试了欧氏距离,然而效果并不明显。
后来来了一位新同事,他很强啊!他在阅读文献的过程中发现余弦距离可能会对此比较敏感,于是选用了余弦距离(向量之间的夹角),这一试不要紧!距离基本有了明显的界限,库内人和库外人的距离拉开了差距,基本以0.1为一个界限,库内人距离短,小于0.1,库外人大于0.1。在后来的实验中,我们发现,是否佩戴眼镜对检测结果影响很大!毕竟这些是基于视觉、基于光学成像的,而眼镜可以反光,正好对成像造成了影响,其实是呈现出的图像已经变形了!所以可能就为识别带来了一个要求,需要摘下眼镜进行认证。
到目前为止,已经可以较好的识别库内人和库外人。(多亏了预先距离啊)
好的,今天就先讲到这儿吧。
-------------------------------------------------------1101----------------------------------------------
今天,有一个好消息和一个坏消息。。。。。。。。
哈哈今天一早上去就感觉一直在等下班,下班后一下午都在学校开会,然后一下午就没了!以前一听到开会,哎,又要开会了啊。。。现在呢,哇,又要开会了!!真希望多几个开会的日子,一个半天就可以这么水过去 了。
今天早上看了一下阈值的问题,后来来了ROC受试者工作特征,发现可以测试多组数据,然后得到每个阈值下的真正例(True positive)和假正例(False positive),发现可以用这个曲线进行统计从而得到每个阈值的情况下分类器的性能,并且进行拟合,最后找到这个均衡点,即ROC曲线与y=-x+1的交点,这样可以做到真正例最多,假正例最少。。。
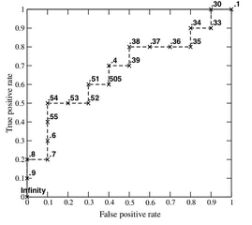
对于ROC曲线,其有一个很好的特性:当测试集中的正负样本的分布变换的时候,ROC曲线能够保持不变。在实际的数据集中经常会出现样本类不平衡,即正负样本比例差距较大,而且测试数据中的正负样本也可能随着时间变化。下图是ROC曲线和Presision-Recall曲线的对比:
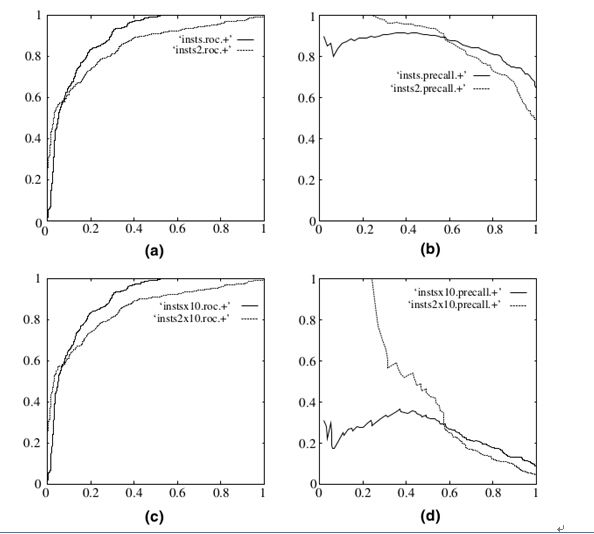
a,c为ROC曲线,b,d为precision-recall曲线。(a)和(b)展示的是分类其在原始测试集(正负样本分布平衡)的结果,(c)(d)是将测试集中负样本的数量增加到原来的10倍后,分类器的结果,可以明显的看出,ROC曲线基本保持原貌,而Precision-Recall曲线变化较大。
而P-R曲线是precision-recall查准率-查重率曲线,其标准图为下图所示:

在两个曲线的交点处取得最佳阈值。
下午开会结束回来,发现了一 个问题!随手打开之前写好的程序,想再看看效果,意想不到的事情出现了,居然运行不了了!main.o发生错误! 这是个什么鬼!
我查了一下,main.o是个目标文件,是二进制文件,在还没转换成exe前的一个目标文件。而这个错误又是个什么问题呢,貌似是编译器的路径问题,没有成功编译啊。后来回想起来,昨天一起的同学在电脑上好像在捣鼓什么编译器之类的,大概就是那个时候就弄出事了吧,这样还能转换回去吗。。。谁也不知道了。晚上尝试着修改了工程的pro文件和makefile文件,似乎也不能解决问题。
倒腾了一晚上想恢复回来,还是没有成功!明天只能继续了,是不是看我这几天没事干,上天给我加了一难。颇有种九九八十一难,还差一难的感觉。
——————————————————————————————————————
---------------------------------------------------1103---------------------------------------------------------
后来,那天晚上,在那位同事的帮助下,电脑恢复了之前的GCC版本。哎,以后真的不能再随便改变编译器的版本了!
接着说实习的情况,上次说到人脸识别了,关于距离,有一篇博文专门介绍除了欧氏距离以外的其他距离的,可以参考。做完人脸识别我就准备回去上课了,上完一个月的课之后我再回来实习。
回来之后,我被安排在“疲劳检测”模块,我是完成嘴部的疲劳特征检测,即哈欠检测。哈欠检测的具体内容在博文中也有介绍,大概是这样的:经过查阅文献,我们发现哈欠的检测大致分为两块内容,一是嘴巴张大的程度,一是嘴巴张大的持续时长,张大程度可以区别普通说话和意外张嘴(如感到吃惊等),持续时间也可以与其他情况的张嘴进行区分。一般而言,嘴巴张大到一定程度不变小,且持续3s,即可判定为打哈欠,而当1分钟打哈欠两次,则可判为疲劳,打一次哈欠可以判定为轻度疲劳,当然除此之外,还需要结合眼部特征(眨眼次数,眨眼速度)、头部姿态估计(是否发生了瞌睡引起的点头动作),从而综合判定疲劳。
首先也是查阅资料,最先尝试的是使用landmark点进行计算,直接用坐标值相减,得到一个张开度aph,然后根据aph值和持续时间t进行判定。这里用到的数据是landmark(Dlib),然而landmark并非很准确,难免会出现丢帧(当检测不到脸时就什么也没有)或者定位不准确(当头部pitch角度偏大,就会不准,或嘴部张到很大,一定程度上丢失了算法的约束特征),此时就会一度使得计算的aph值小于实际值。我们是将大于阈值Taph的值记为1,小于的记为0,建立先进后出(FIFO)的队列,然后对整个队列进行统计,该队列为固定长度,为一个时间窗,仅统计时间窗中的哈欠次数。我们提出一种补1的算法,即如果101的情况,中间直接补1,如为1110X0111的情况也将其中的0全部补为1,从而保证哈欠是连续的,因为一般而言1s有15帧,一般开闭嘴的过程不会小于1/15s。
后面我们对landmark计算aph值进行了一定的改进,为规避landmark偶尔不精确的情况,使用二次函数对两组特征点进行拟合(polyfit_2),通过找到这两个函数一定范围内的最大值、最小值,再相减,除以横坐标的差,就得到了最终的aph值,该值比直接计算具有更好的鲁棒性。
后来针对landmark点不准的情况,考虑了一种基于图像处理的方法提取边缘,即通过多次的膨胀腐蚀操作,然后使用canny算子进行提取边缘,最终在单个图上都能得到较好的效果(因为每张图的嘴巴张开度不同,所需要用到的腐蚀、膨胀的单元结构大小不同)基本思路是:
1、landmark获取粗定位数据,上下左右进行扩充30像素点;
2、得到子矩阵,下面对子矩阵进行处理:
二值化,选用自适应阈值进行二值化(CV_ADAPTIVE_THRESH_GAUSSIAN_C);大津法(OTSU类间距离大于类内距离)在某一图像中效果好,不适用于所有图像;
[if !supportLists]3、[endif]进行腐蚀(erode)-膨胀O(dilatate)-膨胀-腐蚀等操作得到边界图像。对于腐蚀的element元素大小选取会因图像本身嘴巴张开大小而变化。
腐蚀后:会出现更多的黑色区域(对于二值化后的图像而言,白色会收缩腐蚀,黑色会扩散)。
膨胀后:可消除部分黑块(对于白色膨胀,黑色被腐蚀)。
4、最后用canny算子提取边界。
先二值化(针对不同图片的问题采用了自适应二值化的函数,opencv自带),再膨胀、腐蚀,最后canny算子提取边缘,再找到边缘的最高点和最低点,计算aph值,但是该方案不能很好的适应所有帧,所以还有待探讨,如果使用一种自适应的结构单元进行腐蚀膨胀。
后来我们进行了实验,发现头部不同的偏转角,对aph值都有较大的影响。那怎么办呢?是不是存在一种类似如下式所示的数学关系:theta(1)=Acos(theta+C)+B,或者进行一次建模分析,将镜头和人的头部建立基于角度的模型,记录大量40度的数据和0度的数据,考虑使用matlab进行拟合,得到一个对应的参数A,B,C这样,我们就可以根据一个偏转角,对aph进行补偿。
下次将讨论使用机器学习的方法进行特征检测。
-----------------------------------------------------1104----------------------------------------------------------------
继续昨天的内容,使用机器学习的方法进行嘴部的特征检测,是比图像处理这些方法要更加高大上一些了,其实质就是object detection,其实问题就转化为了寻找和训练好的物体一致的目标。
基于机器学习的哈欠识别,优点是克服人脸偏转的影响和光线变化的影响。当然还有一种解决偏转的办法是使用双摄像头,主摄像头定位失败,则启用副摄像头进行定位。
这种方案即:输入训练样本,标注嘴巴图片为闭嘴、中度张嘴和张嘴,分别为不打哈欠、哈欠起始或说话、打哈欠。标注眼睛部分图像为闭眼、微闭、睁眼三种状态,同时将脸部其他图片输入作为“其他样本”进行处理。在样本中我们可以尽可能考虑样本的多样性:比如光线的影响、转头的影响等。这样避免直接计算或者使用landmark所带来的不稳定性。
我们训练分类器时将使用Adaboost学习,其实质就是使用几个特征(haar特征,hog特征等等)训练多个分类器,然后将这些分类器进行结合,而结合的过程也是机器学习的过程,每一次在分类过程中都把分错的样本加大权重,确保下次在分类时该类样本能够被正确分类。Adaboost能够保证在若干个迭代学习后整体错误率低,在每次迭代之后会更新样本的权重,Adaboost算法会对分错的样本加重权重,使得其在下一个分类器中能够被正确分类,最后将这些分类器结合起来得到一个强分类器。这样的话就可以直接通过摄像头获取的图像对脸部特征进行标注。对连续特征的帧数进行统计,一旦达到某一阈值便报警,发生疲劳。
再后来的几天,我们就开始。。。标数据了!这个有个很好的名字,从事数据清洗工作,就是对手型、手势进行标注。当出现手型1的时候,用矩形框框出这个1,矩形框的与手型的边界不超过3个像素点。对,就是这样。框出后记录下这个矩形的坐标到xml文件中,在神经网络训练的时候就可以直接读取这一部分图像进去了。
今天是实习的47天了,一共75天,还剩下28天,一个月多一点的时间,感觉已经习惯了朝9晚6,早上可以避开上学上课的高峰,每天几乎无一例外的8点40达到公司。今天又画了一点油画,每画完一点,也就意味着离结束近了一点。
------------------------------------------------------1111------------------------------------------------------
哈哈 又到周末了,已经实习了52天,还剩下23天。
本周前两天应该还是标注数据。
这周闲暇时间,看了下上周入手的《白话深度学习与Tensorflow》对一些模型稍微有了一点了解,什么CNN(卷积神经网络,权值共享,卷积-池化-全连接,一步步提取特征),深度残差网络(前面层的较为清晰的向量数据会和后面有损压缩过的数据共同作为后面数据的输入)、RNN循环神经网络,就是拥有一个反馈输入的过程(也是两个部分作为输入,一个是前一步的输出,加上上一层到这一层的输入)。还有HMM、LSTM(RNN的一种)。
学习了这些模型后,大概论文的一些术语要好看一些了!
然后我们也测试了之前的代码,修正了帧数显示的问题(就是打哈欠了最长连续哈欠帧有显示问题,修改了判断的逻辑)。再加上了深浅哈欠的判断,把10帧作为一个阈值,0.5的aph阈值,超过这个就作为打哈欠的,而且是浅哈欠,当超过0.65的连续有15帧及以上,那么就认为是深哈欠,其余情况均认为是浅哈欠。(对于是否有必要加深浅哈欠还有待讨论,毕竟每个人哈欠的状态不尽相同)
然后基本需要到封装这一步了。我需要把他封装成.so的动态库。我们选择新建一个C++库,然后在.h文件中声明方法,写所有的define,在.cpp中实现这些方法,点构建,这样就在debug目录下生成了对应的.so文件。然后再新建一个工程,在Main函数中调用这个方法,就大功告成!
这个内容还没尝试,至少main函数调用这一步还没做成功,还需要去搜集资料。
---------------------------------------------1114-----------------------------------------------------------
今天尝试着将函数封装起来了,具体可参见另一博文《Qt生成.so文件》。也是费了一番折腾了,遇到了各种各样的问题,尤其是一些数据结构不熟,再加上封装和调用没有用过。在函数中,需要把之前的全局变量定义成函数中的变量,对于异常帧的处理:对于未检测到人脸的情况,返回alph值为0,然后呢,在序列中对最新的5帧数据先进行遍历,如果当前连续5帧均没有检测到人脸(即连续5个0),则立即报当前帧未检测到人脸,继续进行下一帧的检测,当前5帧不再是连续的5个0时,对连续的200帧进行检测。若满足哈欠的条件即返回。
然而,他们人脸识别还不是很好,今天未通过测试,所以紧急抽调人马进行开始测试人脸识别的其他几个模型,试着用opencv里的库,用数据重新训练深度学习的神经网络。。。我接过LDA的模型,准备再看看,在matlab QT上都试试。
--------------------------------------------1116--------------------------------------------------------
再次试了matlab版本的LDA,这次不再使用图片匹配,而是采用视频流进行匹配,这个结果并不是那么满意:
处理过程如下:
首先分离原来的代码,找到测试图片的部分代码,改写,读取的为一帧一帧的视频流,这样每次测试的均只有一帧图像,将图像送到LDA分类器中进行分类。每次均需要creat一个测试data,所以定义测试data为一帧,然后进行while循环即可。
由于每次送进去的都要是脸部图像,所以找到了matlab中的脸部检测函数,faceDetector = vision.CascadeObjectDetector();videoFrame = step(videoFileReader);
bbox= step(faceDetector, videoFrame);bbox的返回值就是一个矩形Rectangle类,可以框出当前帧的脸部,其值为:【x,y,width,height】。
其中遇到了一个问题!之前每次都是可以识别(而且还挺准的),但是换成了使用matlab工具箱中的cv工具箱检测脸的时候问题就来了,每次都是识别成一个错误的固定的人,无论如何改变测试集的内容,都是一致的结果。这个问题我让它过夜了,今天上午经过多次的单步调试,终于发现了问题所在。
不同函数获取到不同的数据类型!
今天找了半天的错误,总是把人识别错,不管换谁,最后的结果都是一个人,这是为什么呢?当撤去这个人,就会一直识别成另外一个人,可见其中的变与不变性。后来在单步调试中发现是函数的问题,两种读取视频的函数所得到当前帧的数据类型不同,使用mov =VideoReader('filenamei');
得到的是整型uint8数据,而在训练集中获得的特征也是保存成这个类型的,所以识别结果较为准确,而使用videoFileReader = vision.VideoFileReader('filename');%调用vision的库
函数得到的帧数据保存为double、single类型,所以在框出人脸后需要再转换为uint8类型从而去识别即可正确。
最后,再将训练部分代码和测试部分代码分离,这样可以很快的完成测试。分离出需要的变量,这样matlab中会自动保存。再运行测试代码,可直接使用前面的变量。
我们发现,准确率并不是很高,不再使用欧氏距离,改用cosine值,然而并没有什么用,考虑到另外一种改进方案:每次都计算和库中训练集样本的距离,然后对同一类样本的距离求取均值,对这几类进行排序,选择最小距离和次小距离的两类样本,取最小距离的最大值,取次小距离的最小值,将这两张图片取出,这两类也作为最终的candidate,用新的方法进行二次判决,得到最终结果。
然后,又对之前的.so文件进行了测试,这次为啥又显示ld 找不到库的错误了,这儿是“l+工程名”而不是l+.h文件名!
这次学到了几点:
1、shape.push_back(cv::Point2d(shapes.part(i).x(),......y()))就可以直接把他push到队列中去。
2、std::deque
那么,对于这个que而言,可以直接将aa push_pack进去, que.push_pack(aa)这样数据就进去了,另外 &x的可以直接传进去,在函数中定义 int a(int &x,int &y) a(2,5)就可以,而不需要在调用的时候使用&符号,如果传进去的是参数,那么这个值就已经发生了改变。
今天是第56天了,还有19天就结束了!
-------------------------------------------------1118-------------------------------------------------------
人脸识别的主要问题,还是在于光的问题!之前是因为彩色训练,灰度测试不成功,现在更换训练集后,再换用Dlib的库,测试后不同的光照会影响识别的速度,当光照强度变化识别的准确率也会变化,由于阈值抠的很低,所以拒绝率会很大,常把库内人认作陌生人。所以现在考虑自己找样本然后转灰度去训练提取特征的模型(128特征),这样是否能够提高识别的准确率。
今天我对检测到人脸就一定有landmark进行了初步验证,目前的感觉是有人脸检测到就有landmark的。另外我们就深浅哈欠、哈欠进行了测试,测试结果尚可,只要有landmark即能够标注出特征点,基本都是准的。数值上问题不大。但是,如果不是哈欠,有时候张大嘴巴喊一声,持续张大时间较长也会误认为是哈欠。所以对于闭嘴时间这个问题是不是需要拎出来单独讨论或者这个小时间段中的方差作为二次判别的依据。另外就是人脸检测不到、没有landmark的情况,是不是在失效后采用图像检测的方法进行识别。