编译 | Debra
编辑 | Vincent
AI前线出品| ID:ai-front
AI 前线导语:“Facebook 人工智能实验室主任 Yann LeCun 曾说道,GAN 是近十年来机器学习领域中最有趣的概念。什么是 GAN(Generative Adversarial Networks,生成式对抗网络)?作为一个快速发展的领域,GAN 发展的最新成果是什么”?
最早提出 GAN 概念的人是谷歌大脑的 AI 研究科学家 Ian Goodfellow,GAN 发展潜力巨大,但仍有待探索。
简单来说,GAN 是指两个神经网络之间相互竞争和学习, 目前,GAN 最常用的用途是生成逼真的假图像,也可用于无监督学习(例如从没有标签的数据中学习特征)。GAN 由生成器和鉴别器两个神经网络组成,这两个神经网络在同一时间受训练,相互之间进行极大极小的竞争。其中,生成器被训练产生逼真的图像来欺骗鉴别器,而鉴别器则被训练如何不被生成器生成的图像所欺骗。

首先,生成器生成图像。通过从简单的分布(例如正态分布)对矢量 Z 采样,将该矢量上的采样生成图像。 在第一次迭代中,这些图像看起来非常杂乱。 随后,鉴别器接收假的和真实的图像,并学会区别它们。 生成器稍后通过反向传播步骤接收鉴别器的“反馈”,从而更好地生成图像。 最后,使得假图像的分布尽量接近真实图像的分布,或看起来尽可能合理。
由于在 GANs 中使用了极大极小优化,导致训练可能相当不稳定。 GANs 发展速度很快,短时间内不断地改进,目前大致已经有以下 10 个发展方向:
原始 GAN:上文已述。
深度卷积(DCGANs)
在训练稳定性和样品质量方面的第一个重大进步。它在训练中生成更高质量的样品,训练更加稳定。DCGAN 非常重要,因为它们已经成为实施和使用 GAN 的主要基准之一,已经可以在 Theano、Torch、Tensorflow 和 Chainer 中,用不同的方法测试数据集。
如果想要处理更复杂的数据集,可以选择 DCGANs,因为 DAGANs 在解决复杂问题上比 GANs 好得多。同样地,DCGANs 的算法也比 GANs 更加先进。从这点上来说,以下的各种 GANs 是基于 DCGANs 上的改进。
Improved DCGANs
在 DCGANs 基础上的又一次改进,可以生成更高分辨率的图像。
虽然 DCGAN 的架构更加完善,Improved DCGANs 训练过程仍然不稳定,但进步显而易见。特征匹配:通过提出一个新的目标函数,而不是训练生成器欺骗鉴别器。这个目标函数需要生成器生成与真实数据统计相匹配的数据。在这种情况下,鉴别器仅用于指定哪些是需要匹配的数据。
历史平均值:更新参数时,也会参考过去的值。
单向标签处理平滑:方法非常简单,只需要鉴别器从 [0 = 假图像,1 = 真实图像] 到 [0 = 假图像,0.9 = 真实图像] 中做鉴别,这样就可以改善训练效果。
虚拟批量标准化:使用在参考批次上收集的统计信息,以避免对同一批次上数据的依赖性。这样做的计算成本很高,所以只用在生成器上。所有这些技术使得该模型能够更好地生成高分辨率的图像,而这是 GAN 的弱项之一。 作为比较,原始 DCGAN 和改进的 DCGAN 在 128x128 图像上作用区别明显:

在左侧狗的图像中,DCGAN 无法显示图像,而改进的 DCGAN 上可以显示出小狗的轮廓。这也暴露了 GAN 的另一个局限性,即生成结构化的内容。总之,DCGAN 可以生成比 GAN 分辨率更高的图像。
有条件 GANs(Conditional GANs ,cGANs)
使用标签信息提高图片质量,生成图像质量更高,且可以控制图片显像的方式。cGANs 是 GAN 框架的延伸。 这里我们将描述数据某些方面的条件信息设为 Y 。例如,在处理脸部图像时,Y 可以描述头发颜色或性别等属性,并将该属性信息插入到生成器和鉴别器中。
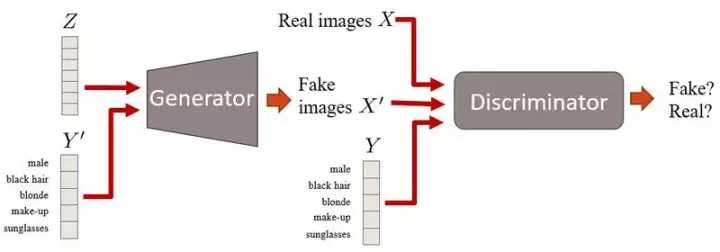
cGANs 有两个特点:
其一,将更多的信息输入到模型中时,cGANs 会学习利用它,因此能够生成更好的样本;
第二,cGANs 可以控制图像显示,非有条件的 GAN 所有的图像信息都编码在 Z 中,而 在 cGANs 加入条件信息 Y 时,Z 和 Y 将编码成不同的信息。
例如,假设 Y 包含手写数字(从 0 到 9)的信息。 然后,Z 会包含所有其他的不是以 Y 编码的变体的信息,比如数字的样式(大小、翻转等)。

cGANs 机制不仅可以控制图像内容怎样显现,还可以通过边界框和标注决定像素的位置。
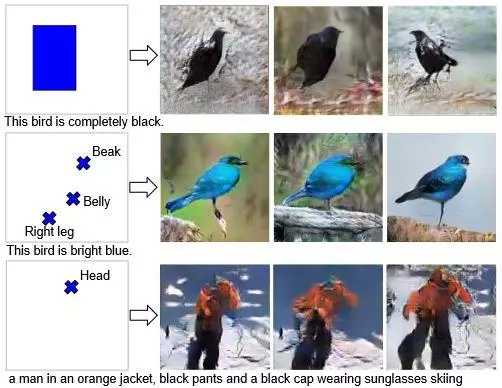
此图中,同时使用 2 个 GAN——阶段 1 和阶段 2 来改善图像的质量。 阶段 -I 用于获得包含图像的“一般”概念的低分辨率图像。,阶段 2 对阶段 1 的图像细节和分辨率做了细化。

cGANs 可以进行标签化训练,以提高图像质量,并控制图像显示方式。
InfoGANs
在无人监督下对有意义图像进行编码。例如,在数字数据集 MNIST 上,编码翻转的数字。
矢量 Z 通常会对图像的不同特征进行编码。例如,可以通过选择 Z 的位置,改变其从 -1 到 1 的数值。

在上图中,生成的图像似乎慢慢换成“Y”(更像 4 和 9 之间的融合)的 4 种变体,编码信息的方式非常杂乱,而 Z 的单一位置是图像多个特征的参数。 在这种情况下,这个位置改变了数字本身(4 到 9)和样式(从粗体到斜体)。所以,无法为 Z 的位置定义任何确切的含义。
那么,我们如果用一些 Z 的位置来表示唯一的和有限的信息,就像 cGAN 中的条件信息 Y 一样呢? 例如,如果第一个位置是一个介于 0 到 9 之间的数字,它控制了数字的位数,第二个位置控制数字翻转。有趣的是,与 cGANs 不同,它们以无监督的方式实现了这一点,而没有任何标签信息。
与之不同的是,InfoGANs 通过把 Z 分成 C 和 Z 两部分来达到这个目的。其中,C 包含数据分布的语义特征,而 Z 包含这种分布的非结构化因素。
C 如何编码这些特征?InfoGANs 改变了损失函数以防止 GAN 简单地忽略 C。换句话说,如果 C 改变,生成的图像也需要改变。 因此,我们不能明确地控制哪种类型的信息将用 C 编码,但是 C 的每个位置应该有唯一的含义。例如:

当数据集不太复杂,数据集缺少标签信息时,想要了解图像特征的意义并控制图像时,可以使用这种方法。
Wasserstein GANs (WGANs)
重新设计与图像质量相关的原始损失函数。
这种模型可以提高训练的稳定性,减小 WGAN 对网络架构的依赖。GANs 会遇到的问题之一,时不知道什么时候停止训练,即损失函数与图像质量无关。这是个让人头疼的问题,因为我们需要不断地看样本,以了解模型的训练是否步入正轨,但是我们无法知晓什么时候应该停止训练,也没有一个数值可以明确显示调整参数的效果。
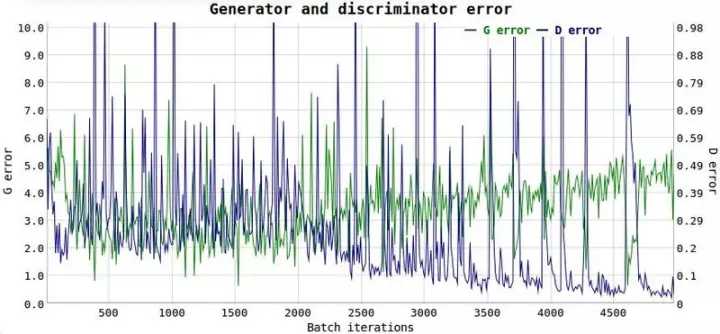
如上图所示,我们无法从图中得知什么时候应该停止训练。可解释性问题就是 Wasserstein GANs 旨在解决的问题之一,这个问题应该怎么解决?GANs 可以被理解为最小化 Jensen-Shannon 分歧,如果真实分布和假分布不重叠(通常是这种情况),则为 0。 而 WGANs 不是最小化 JS 分歧,而是使用 Wasserstein 距离,描述从一个分布到另一个分布的“点”之间的距离。 WassGAN 具有与图像质量相关的损失函数,并且能够收敛,也更稳定,这意味着它不依赖于架构。 例如,即使删除批处理规范化,或建立奇奇怪怪的体系结构,它也能很好地完成工作。
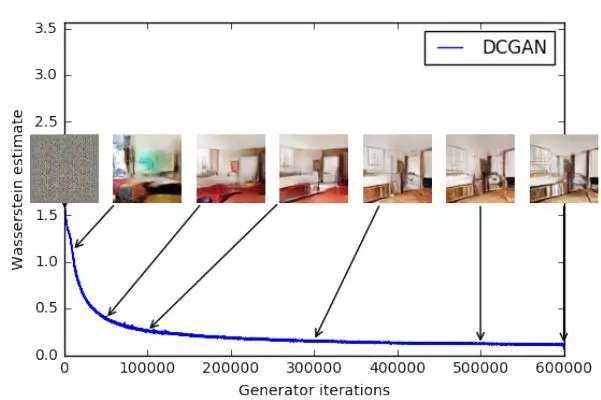
WassGAN 的训练稳定性最高,损失函数也具有信息性和可解释性。
Improved WGANs (WGAN-GP)

WGAN-GP 生成的图像质量明显更高。

WGANs-GP 收敛更快,可使用的框架和数据集范围广泛,也不需要其他 GANs 所需的大量超参数。
边界平衡 GANs (BEGANs)
与其他 GANs 不同,BEGANs 的鉴别器使用自动编码框架(与 EBGANs 类似),以及应用到生成器和鉴别器上的特殊损失函数,这使得生成器生成鉴别器更易重构的真实图像,鉴别器则以最大程度的误差重建真实图像。

WGANs-GP 与 BEGANs 均能提供稳定的训练,但后者能生成更高质量的样品。
Progressive growing of GANs (ProGANs)
在训练过程中逐步添加新的高分辨率图层,以生成让人震惊的逼真图像。
一直以来,生成高分辨率的图像是个很大挑战,因为图像越大,机器需要学习生成更加微小复杂的图像,一般生成图像的像素为 256x256,而 ProGANs 则可以生成 1024x1024 的图像。
ProGANs 建立在 WGANs-GP 的基础上,逐步添加新的高分辨率图层,每一层生成更高分辨率的图像。这个过程大致分为三个步骤,第一步:生成器和鉴别器训练低分辨率的图像;第二步,在某一个点开始增加图像分辨率,称为“过渡期”;第三步,继续训练生成器和鉴别器,如果分辨率未达期望,则重复步骤 2。
经过 ProGANs,图像的质量更高,生成 1024x1024 像素图像的训练时间减少 5.4 倍。此外,这个系统还让 Minibatch 标准误差减小,学习率提高,像素也更加规范化。
Cycle GANs
目前为止最先进的 GANs 系统。
如果想要把下图中的斑马变成马,把夏天的景色加入冬天的元素,使用 Cycle GANs 模型不需要配对数据集来学习在域之间进行翻译,但仍然需要用来自两个不同域的 X 和 Y(如,X:马,Y:斑马)进行数据训练。

为了在两个域之间进行翻译,Cycle GANs 使用一种称之为“循环一致损失”(cycle consistent loss)的方法。 这基本上意味着,如果将马 A 转换成斑马 A,再将斑马 A 转换回马 A,结果会变成原来的马 A。
从一个领域到另一个领域的映射不同于 neural style 转换,后者将一个图像的内容与另一个图像的内容相结合,而 Cycle GAN 学习的则是从一个域到另一个域的高级特征映射。因此,Cycle GANs 更加通用,也可以用于各种映射,如将目标对象的草图转换为真实图像。
总之,WGANGP 和 BEGANs 是 GAN 模型发展过程中的两个重大突破,ProGAN 也可为生成逼真的高分辨率图像指明了方向。 同时,CycleGAN 则告诉我们,GAN 具有从数据集中提取有意义的信息的能力,以及如何将这些信息转移到另一个不相关的数据分布中。
-全文完-
人工智能已不再停留在大家的想象之中,各路大牛也都纷纷抓住这波风口,投入AI创业大潮。那么,2017年,到底都有哪些AI落地案例呢?机器学习、深度学习、NLP、图像识别等技术又该如何用来解决业务问题?
2018年1月11-14日,AICon全球人工智能技术大会上,一些大牛将首次分享AI在金融、电商、教育、外卖、搜索推荐、人脸识别、自动驾驶、语音交互等领域的最新落地案例,应该能学到不少东西。目前大会8折报名倒计时,更多精彩可点击阅读原文详细了解。
http://t.cn/Rl2MftP
