前言
Disruptor是英国外汇交易公司LMAX开发的一个高性能队列,研发的初衷是解决内存队列的延迟问题。基于Disruptor开发的系统单线程能支撑每秒600万订单,2010年在QCon演讲后,获得了业界关注。
其实Disruptor与其说是一个框架,不如说是一种设计思路,这个设计思路对于存在“并发、缓冲区、生产者—消费者模型、事务处理”这些元素的程序来说,Disruptor提出了一种大幅提升性能(TPS)的方案。
 老司机带带我
老司机带带我
-
来一张全链路流程图
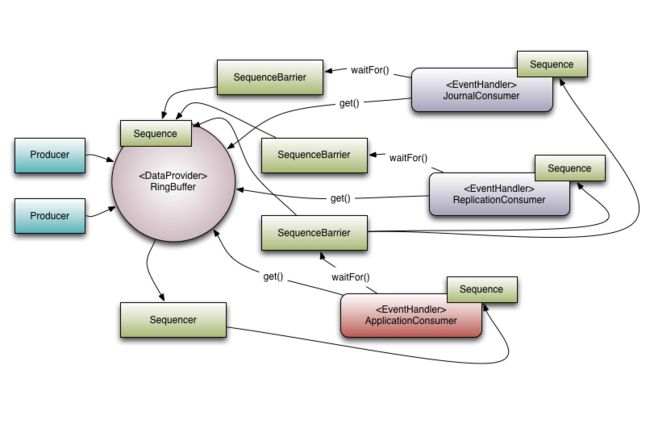
disruptor设计理念很超前,解决了传统队列的痛点
1、false-sharding:CPU伪共享问题
2、无锁编程的极致体验-CAS
3、两个独立的线程之间高效交换数据
一、锁的代价
Disruptor论文中讲述一个实验,一个计数器循环自增5亿次
- 场景1:单线程无锁时,程序耗时300ms
- 场景2:单线程有锁,程序需要耗时10000ms
- 场景3:双线程有锁,耗时224000ms
-
.........

Why?
简而言之就是多线程锁竞争导致的上下文切换时间成本远远大于了线程持有锁的性能损耗
- ArrayBlockQueue伪代码分析
public void put(E e) {
final ReentrantLock lock = this.lock;
//加锁
lock.lock();
//当队列满时,调用notFull.await()方法,阻塞写线程。
while (count == items.length) {
notFull.await(); //Condition条件阻塞
}
//把元素 e 插入到队尾
insert(e);
//解锁
lock.unlock();
//若队列为空,激活读线程
notEmpty.signal();
}
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
//加锁
lock.lock();
//当队列空时,阻塞读线程
while (count == 0) {
notEmpty.await();
}
//取出队头元素
E x = extract();
//若队列full,激活写线程
notFull.signal();
return x;
//解锁
finally{
lock.unlock();
}
}

- tail(takeIndex)和head(putIndex)指针都是锁竞争的冲突点
队列的目的就是为生产者和消费者提供一个地方存放要交互的数据,缓冲上下游的消息,实际场景中缓冲常常是满的(生产者比消费者快)或者空的(消费者比生产者快)。生产者和消费者能够步调一致的情况非常少见。 - ArrayBlockQueue是悲观锁的一种体现,读写线程都假设存在冲突, 多线程并发场景下,性能很差
- 接下来让我们看看Disruptor的实现
disruptor根本就不用锁,取而代之-CAS,严格意义上说仍然是使用锁, 因为CAS本质上也是一种乐观锁 - Java悲观锁和乐观锁逻辑上类似Mysql的锁
CAS:Compare And Swap/Set 顾名思义比较和交换
CPU级别的指令,cpu去更新一个值,但如果跟新过程中值发生了变化,操作就失败,然后重试,直到更新成功!
Disruptor的sequence的自增就是CAS的自旋自增,对应的,ArrayBlockQueue的数组索引index是互斥自增!
-
乐观锁设计思想:假设没有冲突
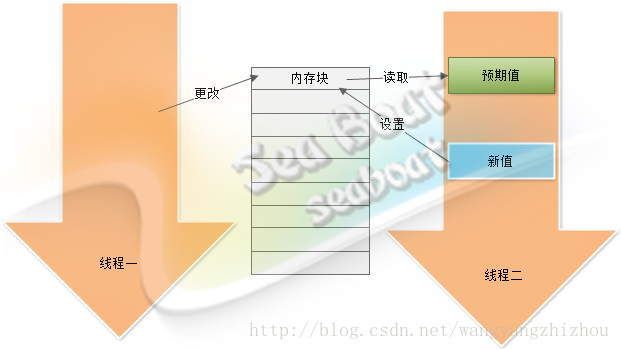 CAS原理图
CAS原理图 -
悲观锁设计思想:假设存在冲突
 悲观锁
悲观锁 CAS 比较适宜持有锁的时间较短的并发场景(自增、简单更新),
反之持有锁时间较长的场景如秒杀,下单,会导致自循环次数过多,线程饥饿程度增加
二、disrupter核心数据结构-ringbuffer
-
队列上下游的缓冲容器
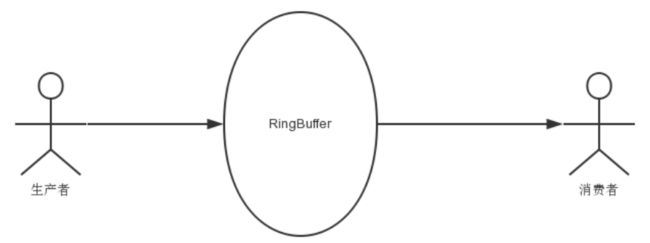
-
首尾相接的环形数组
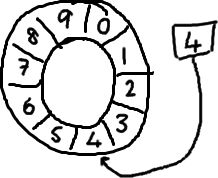
数组长度2^n,通过位运算,加快定位的速度。下标采取递增的形式。不用担心index溢出的问题。index是long类型,即使100万QPS的处理速度,也需要30万年才能用完。
环持续向 buffer 中写入数据,这个序号会一直增长,直到绕过整个环
-
环形数组结构
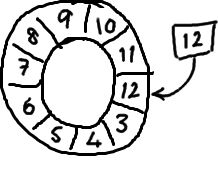
新产生的sequence只覆盖,相对于传统队列不需要频繁GC
private E dequeue() {
final Object[] items = this.items;
E x = (E) items[takeIndex];
items[takeIndex] = null;
if (++takeIndex == items.length)
takeIndex = 0;
count--;/当前拥有元素个数减1
if (itrs != null)
itrs.elementDequeued();
notFull.signal();//有一个元素取出成功,那肯定队列不满
return x;
}
ArrayBloackQueue出队takeIndex索引所在元素设置为NULL,高吞吐量下队列会产生大量GC
- CAS维护了一个sequence,无锁自旋增长
每个生产者或者消费者线程,会先申请可以操作的元素在数组中的位置,申请到之后,直接在该位置写入或者读取数据。
假设两个生产者都想申请第7号slot, 则它们会同时执行CAS自增,执行成功的人得到该序列号slot=7,另一个则重试继续申请下一个可用的slot=8,之后根据mod/size去环形数组中寻找自己的位置。
消费者处理逻辑类似。
三、解决冲突—揭秘内存屏障
-
关键字volatile:Java内存模型将在写操作后插入一个写屏障指令,在读操作前插入一个读屏障指令
 java内存模型
java内存模型
RingBuffer的指针(cursor)属于一个volatile变量,同时也是我们能够不用锁操作就能实现Disruptor的原因之一
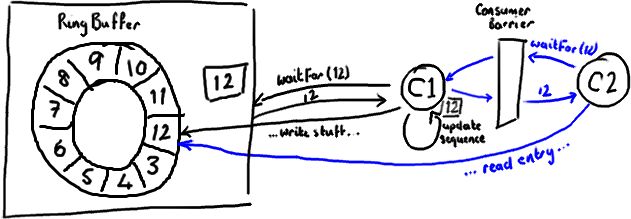
生产者对RingBuffer更新序列号,之后会对volatile字段(cursor)的写操作创建了一个内存屏障,这个屏障将刷新所有缓存里的值(缓存失效)
消费者获取RingBuffer序列号,涉及到读冲突的缓存失效,C2在C1之后,C2拿到C1更新过的序列号之后,C2才能获取next序列号。内存屏障保证了他们之前的执行顺序,消费者总能获取最新的序列号
- 内存屏障作为另一个CPU级的指令,没有锁那样大的开销,volatile意味着你不用加锁,就能让获得性能的提升
四、disruptor多线程并发读写过程浅析
读写并行简图
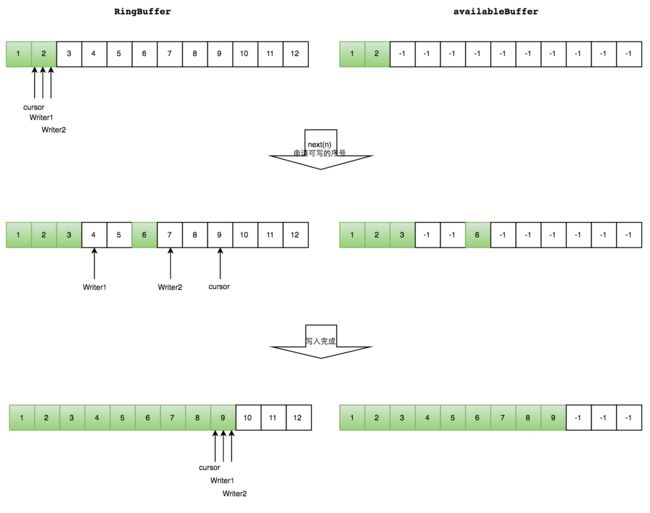
多个生产者的情况下,会遇到“多个线程重复写同一个元素”的问题,解决方法是,每个线程获取不同的一段数组空间进行操作,这个通过CAS很容易达到。只需要在分配元素的时候,通过CAS无脑自增即可判断。
Disruptor在多个生产者的情况下,引入了一个与Ring Buffer大小相同的buffer:AvailableBuffer。当某个位置写入成功的时候,便把Availble Buffer相应的位置置位,标记为写入成功。读取的时候,会遍历available Buffer,来判断元素是否已经就绪。
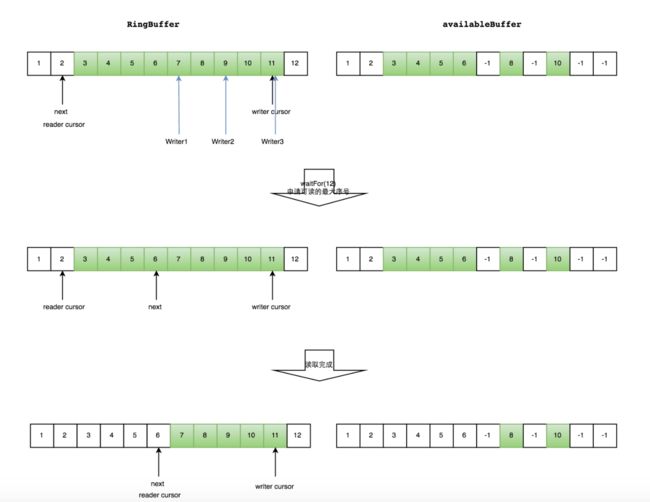
消费者保持一个自己的序列,每次累加后nextSequence,去获取可访问的最大序列。对于一个生产者,就是nextSequence到RingBuffer当前游标的序列。对于多个生产者,就是nextSequence到RingBuffer当前游标之间,最大的连续的序列集。
消费端部分源码分析
public long waitFor(final long sequence){
checkAlert();
//获取最大的可消费的序列,依赖等待策略,策略设计模式的一种体现
long availableSequence = waitStrategy.waitFor(sequence, cursorSequence, dependentSequence, this);
if (availableSequence < sequence) {
return availableSequence;
}
return sequencer.getHighestPublishedSequence(sequence,availableSequence);
}
1、读写不存在冲突:消费者读取到序号 x 位置元素都被生产者写入成功,消费者消费这一段区间数据。
2、读写存在冲突:消费者读取到序号x位置生产者正在写入,也就是下图availble Buffer中标记为-1的位置,则消费者返回该序号x,并执行一段等待策略
- 常见的等待策略
BlockingWaitStrategy:通过线程阻塞的方式,等待生产者唤醒
BusySpinWaitStrategy:线程一直自旋等待,比较耗CPU
YieldingWaitStrategy: 自旋 + yield + 自旋(折中方案)
等等 -
多个生产者情况下,消费者消费过程示意图
- disruptor写线程源码片段分析
do
{
current = cursor.get();
next = current + n;
if (!hasAvailableCapacity(gatingSequences, n, current))
{
throw InsufficientCapacityException.INSTANCE;
}
}
while (!cursor.compareAndSet(current, next));
//next 类比于ArrayBlockQueue的数组索引index
return next;
多线程环境下,多个生产者通过do/while循环的条件CAS,来判断每次申请的空间是否已经被其他生产者占据。假如已经被占据,该函数会返回失败,While循环重新执行,申请写入空间。
-
多个生产者情况下,生产者生产过程示意图
五、聊一聊缓存伪共享
计算机系统中为了解决主内存与CPU运行速度的差距,在CPU与主内存之间添加(Cache)CPU硬件级别缓存系统中是以缓存行(cache line)为单位存储的,当多线程修改互相独立的变量时,如果这些变量共享同一个缓存行,就会无意中影响彼此的性能,这就是伪共享,多线程环境下会导致缓存命中率很低!
-
伪共享问题的产生
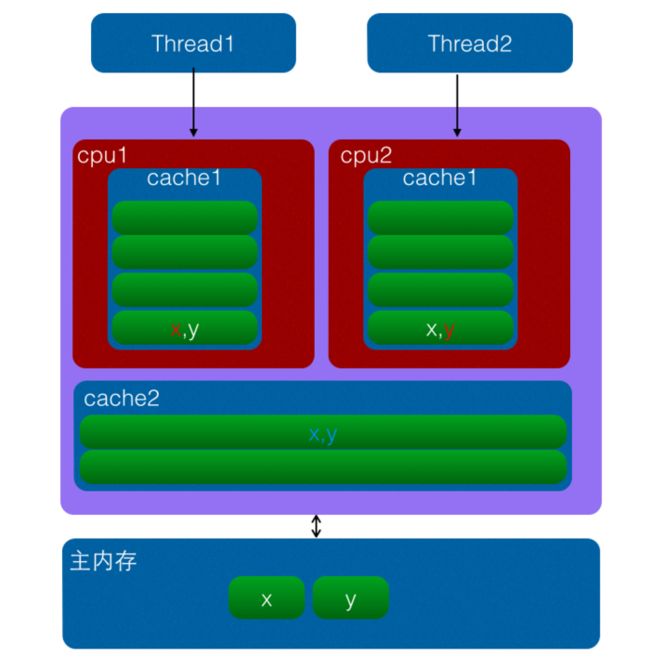
如上图变量x,y同时被放到了CPU的一级和二级缓存,当线程1使用CPU1对变量x进行更新时候,首先会修改cpu1的一级缓存变量x所在缓存行,这时候缓存一致性协议会导致cpu2中变量x对应的缓存行失效,那么线程2写入变量x的时候就只能去二级缓存去查找,这就破坏了一级缓存,而一级缓存比二级缓存更快。更坏的情况下如果cpu只有一级缓存,那么会导致频繁的直接访问主内存,增大系统开销。
-
ArrayBlockingQueue有三个成员变量
takeIndex:出队元素下标
putIndex:入队元素的下标
count:队列中元素的数量
这三个变量很容易放到一个缓存行中,但是之间修改没有太多的关联。所以每次修改,都会使之前缓存的数据失效,需要从主存中重新读取,从而不能完全达到共享的效果。
 ArrayBlockingQueue伪共享示意图
ArrayBlockingQueue伪共享示意图
- 连续内存块巧妙规避伪共享问题
缓存行以64个字节为单位(,long 类型是 8 字节,因此在一个缓存行中可以存 8 个 long 类型的变量,如果你访问一个 long 数组,当数组中的一个值被加载到缓存中,它会额外加载另外 7 个,以致你能非常快地遍历这个数组(缓存共享的免费福利)
Long[] arr = new Long[64 * 1024 * 1024];
long start = System.nanoTime();
for (int i = 0; i < arr.length; i++) {
arr[i] *= 3;
}
System.out.println(System.nanoTime() - start);
long start2 = System.nanoTime();
for (int i = 0; i < arr.length; i += 8) {
arr[i] *= 3;
}
System.out.println(System.nanoTime() - start2);
- 表面上看,循环二工作量为第循环一的1/8;但是执行时间是相差不大的,因为每 8个Long占用8*8=64字节,正好一个cache,也就是说这两个循环访问内存的次数是一致的,导致耗时相差不大(访问cache时间rt忽略不计)
- disruptor怎么解决伪共享问题
其中一个解决思路,就是让不同线程操作的对象处于不同的缓存行即可即缓存行填充(Padding),使一个对象占用的内存大小刚好为64bytes或它的整数倍,这样就保证了一个缓存行里不会有多个对象,这其实是一种以空间换时间的方案。 - disruptor sequence伪代码
//在序号实际value变量(long型)左边填充7个long变量
class LhsPadding
{
protected long p1, p2, p3, p4, p5, p6, p7;
}
class Value extends LhsPadding
{
protected volatile long value;
}
//在序号实际value变量(long型)右边填充7个long变量
class RhsPadding extends Value
{
protected long p9, p10, p11, p12, p13, p14, p15;
}
public class Sequence extends RhsPadding
Sequence实际value变量的左右均被填充了7个long型变量,其自身也是long型变量,一个long型变量占据8个字节,所以序号与他上一个/下一个序号之间的最小内存距离为:158=120byte,加上对象头的8个字节,可以确保sequence大小128byte=264byte(有的CPU缓存行是128byte)
这样直接的代价就是增大的15倍的内存消耗空间,这样的设计导致不可能有两个cursor出现在同一个cpu cache line中, 就解决了”伪共享”问题!
六、demo应用
- 定义事件,Event就是通过 Disruptor 进行交换的数据类型(事件监听模式)
public class LongEvent
{
private long value;
public void set(long value)
{
this.value = value;
}
}
- 定义事件工厂
{
public LongEvent newInstance()
{
return new LongEvent();
}
}
- 事件的具体实现
public class LongEventHandler implements EventHandler
{
//sequence是上图环形数组中的序列号
public void onEvent(LongEvent event, long sequence, boolean endOfBatch)
{
System.out.println("Event: " + event);
}
}
- 启动disruptor
EventFactory eventFactory = new LongEventFactory();
ExecutorService executor = Executors.newSingleThreadExecutor();
int ringBufferSize = 1024 * 1024; // RingBuffer 大小,必须是 2 的 N 次方;
Disruptor disruptor = new Disruptor(eventFactory,
ringBufferSize, executor, ProducerType.SINGLE,
new YieldingWaitStrategy());
EventHandler eventHandler = new LongEventHandler();
disruptor.handleEventsWith(eventHandler);
disruptor.start();
- 发布事件
RingBuffer ringBuffer = disruptor.getRingBuffer();
long sequence = ringBuffer.next();//请求下一个事件序号;
try {
LongEvent event = ringBuffer.get(sequence);//获取该序号对应的事件对象;
long data = getEventData();//获取要通过事件传递的业务数据;
event.set(data);
} finally{
ringBuffer.publish(sequence);//发布事件;
}
六 应用场景
- wacai-zipkin链路跟踪服务端kafka日志处理
- Log4J2