一、什么是消息一致性
消息一致性指的是消息的时序一致性,即消息收发的一致性。如果不能保证时序一致性,就会造成聊天语义不连贯,引起误会。
对于点对点的聊天场景,时序一致性保证接收方的接收顺序和发送方的发出顺序一致;对于群聊场景,时序一致性保证所有接收人看到的消息展现顺序一致。
二、消息一致性的难点
1.多发送方、多接收方、服务端多线程并发处理情况下,无法保证时序一致性。
2.分布式环境下,多个机器的本地时钟不一致,没有“全局时钟”,不能用“本地时间”保证时序的一致性。
三、消息的一致性的实现
▶1. “全局序号生成器”作为“时序基准”
为什么不以客户端(发送方)的本地序号/本地时钟作为“时序基准”?
如果以发送方的本地时钟作为时序基准,发送方发送消息时,将消息本身和本地的时间戳或一个本地维护的序号发送到IM服务端,IM服务端再将这个消息和时间戳或序号发送给消息接收方,消息接收方根据这个时间戳或序号进行排序。
若发送方随时调整时钟,会导致时间戳回退;若发送方重装应用,会导致序号清零,从而回退。
而针对多发送方场景,如群聊和多点登录,存在同一时钟的某个时间点、多条消息发送给同一接收对象的可能。比如一个群聊内,用户A先发言、用户B后发言,但如果用户A的时钟比用户B的时钟慢,已发送方的本地时钟作为“时序基准”就会出问题;再比如微信在手机、电脑上同时登录,两台设备可以给某一接收方发送消息;若设备的本地时钟不一致,接收方可能会出现消息不连贯的问题。
为什么不以服务器的本地时钟作为“时序基准”?
如果以IM服务器的本地时钟作为时序基准,发送方将消息发送到IM服务端,IM服务端依据自身服务器的时钟生成一个时间戳,然后将消息和时间戳一起发送给消息接收方,消息接收方根据这个时间戳进行排序。
一旦IM服务集群化部署,就会出现多台服务器本地时钟不一致的问题。虽然多台服务器可以通过NTP时间同步服务,但依然存在一定的时间误差。
将“全局序号生成器”作为“时序基准”,可以解决每条消息没有标准“生产日期”的问题,按着实现方式可以分为两类,一是支持单调自增序号的生成,如Redis的原子自增命令incr、MySQL的自增ID,二是分布式时间相关的ID生成,如snowflake算法、时间相关的分布式序号生成服务等。
对于群聊和多点登录的场景,只需要保证一个群的消息有序即可,无需全局的跨多个群的绝对时序性。每个群聊有其独立的“ID生成器”,可以通过哈希规则路由到对应的主库实例上,降低多个群聊共用一个“ID生成器”的压力。
▶2. 消息整流
当 IM 服务端接收到消息后,若 IM 服务器是集群化部署,可能因为服务器性能的差异,导致后收到的消息先发出去;又或者多线程处理消息的流程不能保证先到达的消息先发送出去,从而使接收方收到的消息顺序有误,因此需要消息整流。消息整流又分为服务端包内整流和客户端(接收方)整流。
服务端包内整流
比如实现离线推送,当用户上线,网关机会通知业务层用户已上线,业务层就会把该用户的多条离线消息 pub 给这个网关机的 Topic,网关机再把收到的多条消息通过长连接推送给用户。
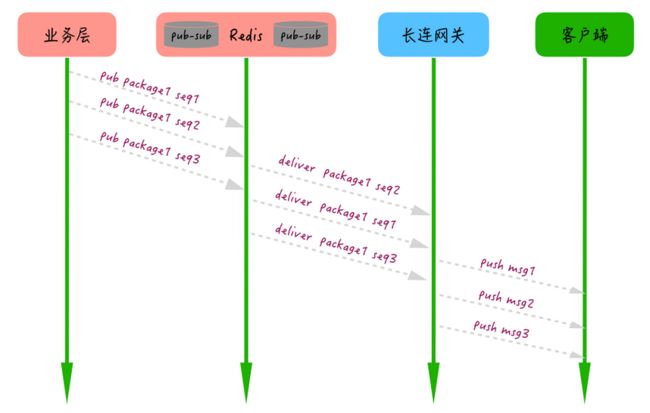
图片来源于《即时消息技术剖析与实战》第 05 讲 1)生产者为每个消息包生成一个packageID,为包内的每条消息加个有序自增的seqID(注:这里的seqID和推送时的SeqID不是一个概念,这是的seqID只是当前这个包的序号,推送时不用看这个);
2)消费者根据每条消息的packageID 和 seqID 进行整流和排序;
3)执行模块只有在一定超时时间内完整有序地收到所有消息才执行最终操作,否则根据业务需要触发重试或直接放弃操作。
消息接收端整流
1)发送方发送消息时,连同消息和序号一起发送给接收方;
2)接收方接收到消息后,先去查找上一条消息的序号,然后比对收到的序号和上一条消息的序号;
3)如果收到的消息序号大于上一条消息序号,直接追加;反之则去查找小于该序号的最大消息序号,并追加到其后。
四、参考
消息时序一致性还可以参考58沈剑大佬的文章:消息“时序”与“一致性”为何这么难?,又会有不一样的收获。