网络应用集成了我们已经学到的很多概念:进程、信号、字节顺序、存储器映射、动态分配等,同时客服端-服务器模型是一个新的知识,我们将所有的这些结合起来,创建一个微小的Web服务器,提供浏览器静态和动态的访问。
1.1 客户端--服务器模型

每一个网络应用都是基于一个客户端进程和一个服务器进程建立起来的,服务器管理资源,客服端请求某种服务,客户端和服务器都是一个运行中的程序。典型的示意图如下:
我们以一个邮件客服端访问文件为例:
① 客户端发送一个浏览文件的请求给Web服务器;
② 服务器接收请求以后,解释它,从资源中取出相应的文件;
③ 服务器将文件发送到请求的客户端;
④ 客户端接收并显示在屏幕上。
1.2 网络
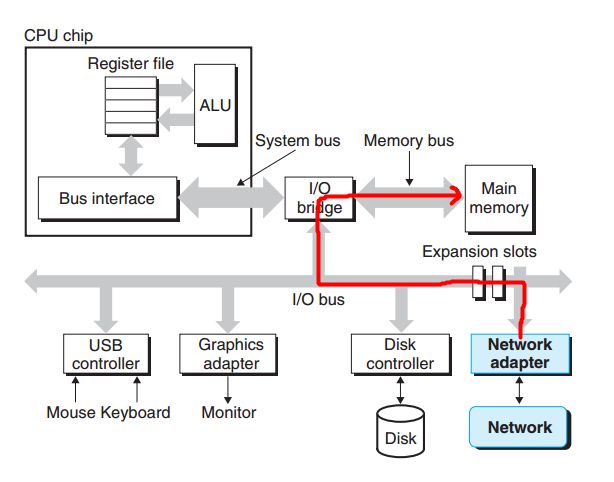
网络是连接客户端与服务器之间的通路,对于单个的主机而言,网络只是插在IO总线上的一种,从网络上接收的数据经过适配器-IO总线-桥-存储器总线-主存:
上图只是一个简图,我们来简单的讨论一下具体的实现
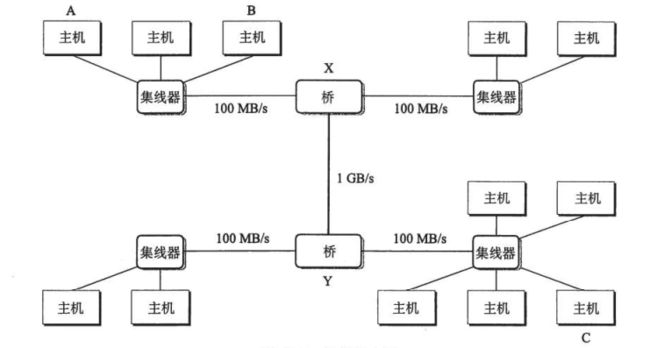
在网络建立的初期,是通过一个集线器,实现无差别的所有主机之间的数据交换。同交换机不同,集线器不是点到点,它的每次转发都是针对所有的主机,这就形成了一个局域网。后来又加入了桥,实现局域网直接的互相连接,总体的架构图如下:
新加入的桥,可以实现自动学习,哪儿主机可以通过哪个端口方便到达,如果将A发送到B,当到达桥X的时候,桥发现A到B就是本局域网的事情,就会丢弃到这个帧。而当A发送到C的时候,桥X只会将帧发送到桥Y再由桥Y分发到C,而节省了带宽。
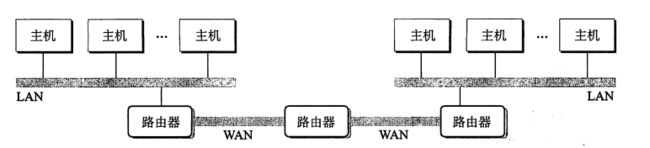
路由器有两个不同的端口,WAN(广域网)连接更大的局域网,LAN(本地网)连接本地主机,结构如下:
网络上的硬件已经全部连接好了,但是我们的主机各有不同,有不同的主机、不同的系统各种千差万别,是如何通过这个网络发送数据实现求同存异的。
通过协议发送,我们人类社会也是一样的,为了达成某种一致性,不至于以后扯皮,我们会实现签订一个协议,将需要调解的问题和责任全部列出,而且竟可能倾其所有,在以后的操作中不会有含糊不清或者界定不明的问题,也就能更好的合作,计算机网络也是一样通过建立一套TCP/IP协议族,实现不同主机之间的数据传输:
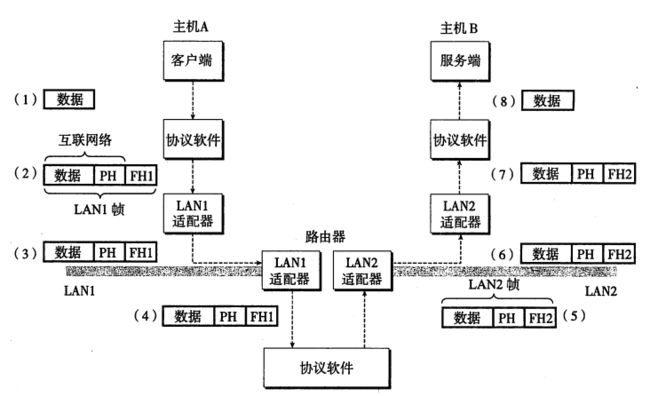
下图是客户端A发送数据到服务端B的过程:
① 客服端将需要发送的数据拷贝到缓冲区;
② 主机A上运行的协议软件(TCP|IP)把实际要发送的数据加入PH(互联网包头)和FH1(LAN1帧头),创建一个LAN1的帧发送到网络适配器中;
③ 主机上的网络适配器(连接在IO总线)收到了这个LAN1帧以后通过网线发送到路由器的LAN1端口;
④ 收到了这个LAN1帧的时候,将其发送到协议软件上;
⑤ 路由器的协议软件将LAN1帧的旧的LAN1帧头剥落,加入到实际发送的主机LAN2帧头,并将其发送到路由器LAN2端口上;
⑥ 路由器LAN2将数据拷贝到网线上;
⑦ 主机B的适配器从网线上收到了这个帧的时候,将其传送到协议软件;
⑧ 协议软件帧头和包头吧实际的数据拷贝出来;
1.3 全球IP因特网
每台主机都支持TCP\IP协议,并运行着这个软件,IP协议提供基本的命名方法和传送机制,我们来看看windows上运行的这个协议:
① IP地址

IP地址是一个无符号的32位整数,存储在如下的结构中:

统一的网络字节顺序是以大端的字节顺序,IP地址也是使用大端法存放的,如果不同的话需要使用一些函数进行转换:
IP地址有时候是使用点分的十进制表示的如:192.168.1.1,而下面的函数可以实现将点分十进制的IP地址转成网络字节顺序的IP地址:

② 域名
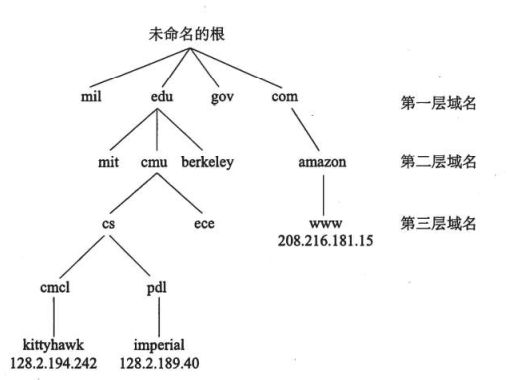
域名是一种将IP地址映射为一组人性化的字符串的机制,而域名的集合是一个层次结构:
第一层域名是一个非营利性组织定义的,常见的有.com、edu、gov等
第二层cmu.edu是按照先后顺序获得的,一旦获得了cmu,就可以向下生成cs\ece等

每一组由字符串映射到IP地址的数据结构如下图:

而负责解析这种映射的称为DNS数据库,保存着成千上万的上图中的条目结构。应用程序可以通过gethostbyname和gethostbyaddr函数显示的从DNS数据库中检索条目:
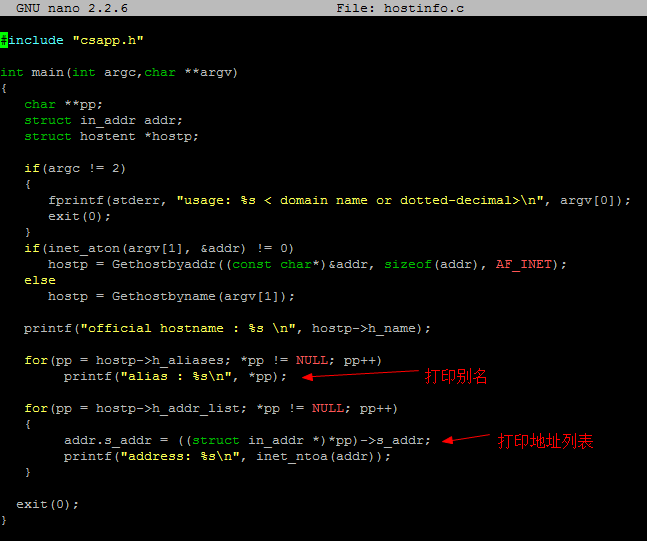
我们来看一个程序:
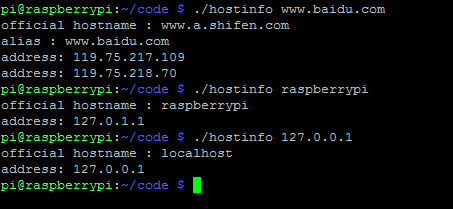
从给定的域名或者IP地址中打印出相应的主机名、别名和地址列表:
可以看出,多个域名可以映射多个IP地址
③ 因特网的连接
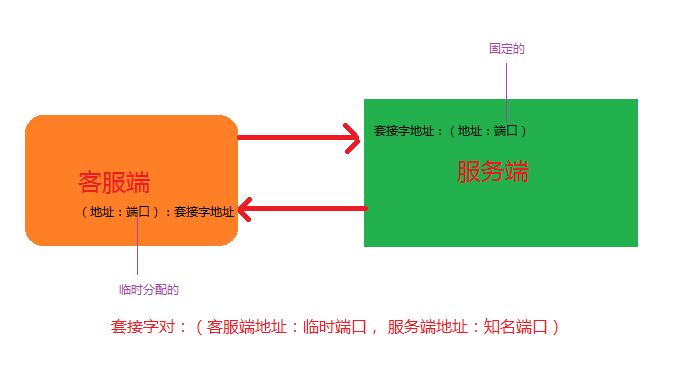
我们通常使用的是一个套接字完成一个客服端与服务端之间的双向连接的
每个端是由该端的地址:端口组成,其中服务端的端口通常是固定的,而客服端的端口是临时分配的,当形成了一个套接字对的时候,就可以开始双向通信了。
1.4 套接字函数
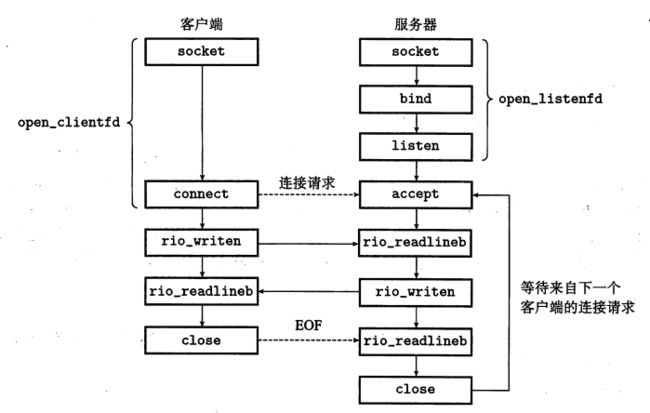
当我们进行客户端与服务端之间的双向通信的时候,我们使用的是一组套接字函数,来看一张总的图:
客户端:
① socket函数:创建一个套接字描述符
我们通常使用clientfd = socket(AF_INET, SOCK_STREAM, 0);来描述,其中AF_INET表示使用互联网,SOCK_STREAM表示使用套接字连接的一个端点;

② connect函数:客服端建立同服务器的连接
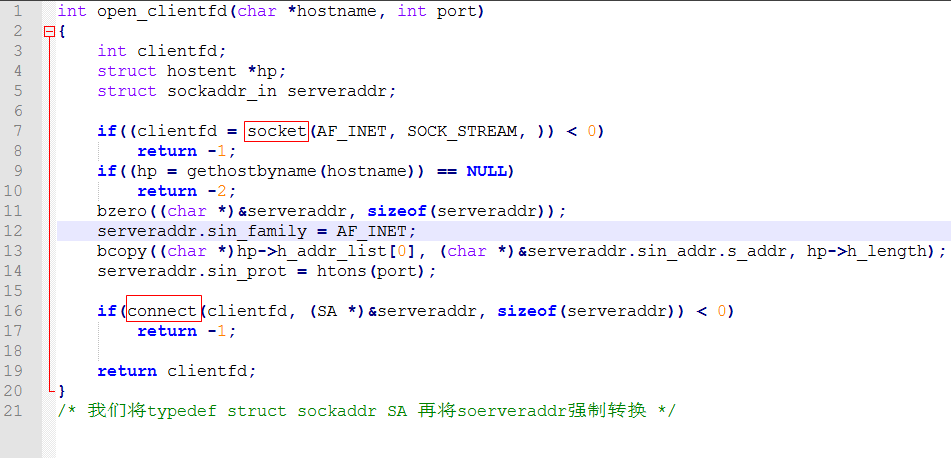
③ 客户端封装socket和connect函数:open_clientfd函数
我们首先创建了套接字的描述(行7),然后检索DNS主机条目,并拷贝第一个IP地址到serveraddr中,发起一个connect(行16)请求,成功时返回clientfd给调用函数。
服务端:
① bind函数:高数内核将my_addr中的服务器套接字地址和套接字描述符sockfd联系起来:
原型是:int bind(int sockfd, struct scokaddr *my_addr, int addrlen);
② listen函数:被动的监听,告诉内核被服务端使用
原型是:int listen(int sockfd, int backlog);将sockfd转化为监听套接字
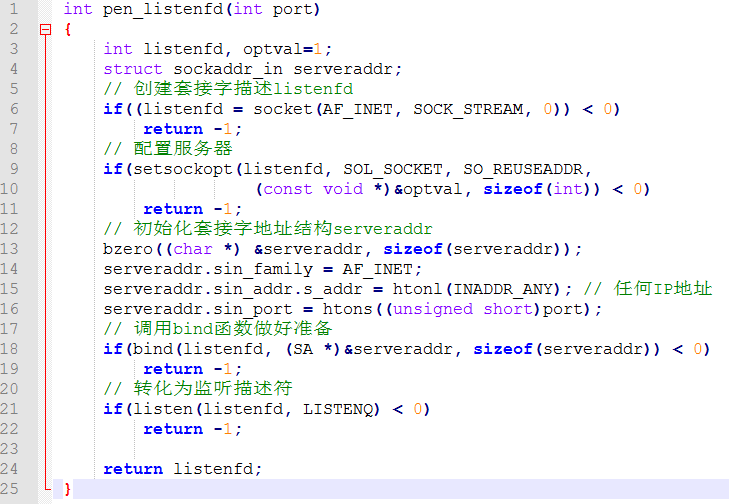
③ 封装:bind和listen成为open_listenfd函数

④ accept函数:等待客户端的连接,创建已连接描述符
监听描述符创建一次存在于整个生命周期,已连接描述符只存在于一个客户端,可以创建并发服务器。

第一步:服务器调用accept,等待连接到达监听描述符;
第二步:客户端调用connect函数,发送一个连接请求到监听描述符;
第三步:打开一个已连接描述符connfd(4)通过connfd和clientfd交换数据。
实例:回声(echo)客服端与服务端
客户端:echoclient.c
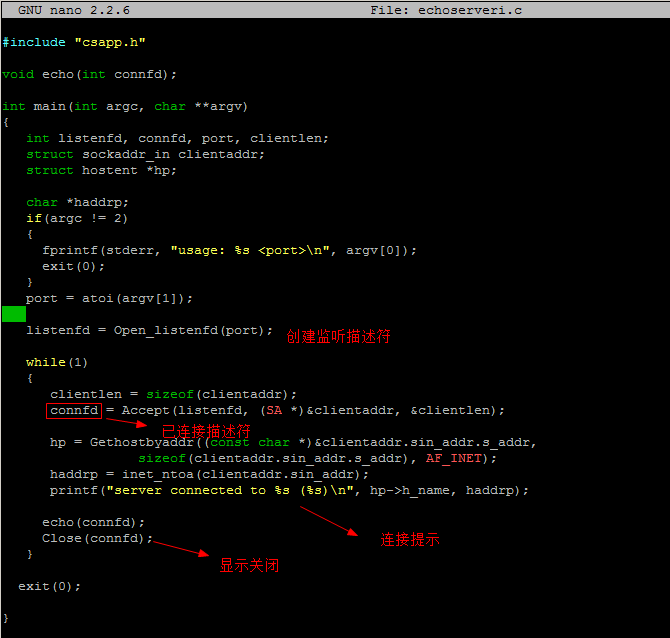
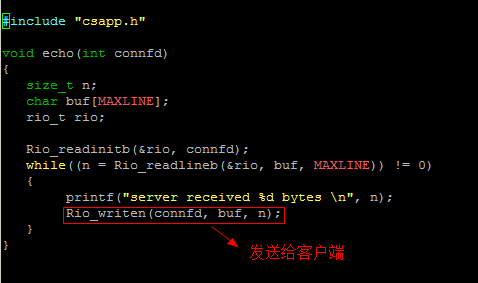
服务端:echoserveri.c
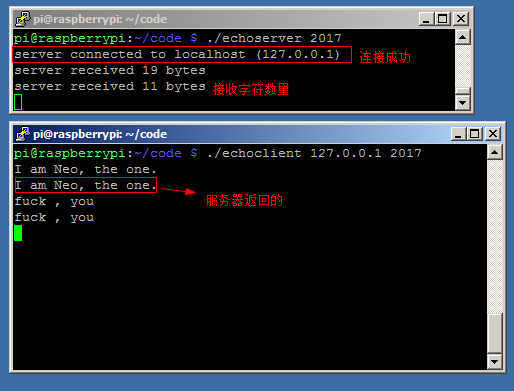
运行效果:
第一步:启动服务器2017端口
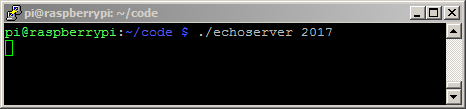
第二步:客服端开始连接本机127.0.0.1 2017端口,并发送字符串
1.5 Web服务器相关知识
① 基础:
Web客户端(浏览器)与服务器之间的交互是基于一个HTTP协议,同常规的FTP协议不同,传输的是超文本标记语言(HTML)
② Web服务器发送的内容
是一个MIME类型的序列

以两种不同的方式发送到浏览器:
1> 取一个磁盘文件,返回给浏览器(静态内容);
2> 取一个可执行文件,返回给浏览器(动态内容)。
URL:通用资源定位符(Universal Resource Locator)
URL是为每个文件定位使用的,其实也就是每个文件的名字,如:
访问:http://www.google.com:80/index.html请求/index.html文件静态内容
访问:http://www.google.com:8000/cgi-bin/adder?15000&213请求可执行文件cgi-bin/adder
注:其中1500&213是执行文件的两个传入参数
注:后缀中的“/”不代表根目录,请求的时候所有服务器默认为主页,解释为/index.html
③ HTTP事务
1> 请求
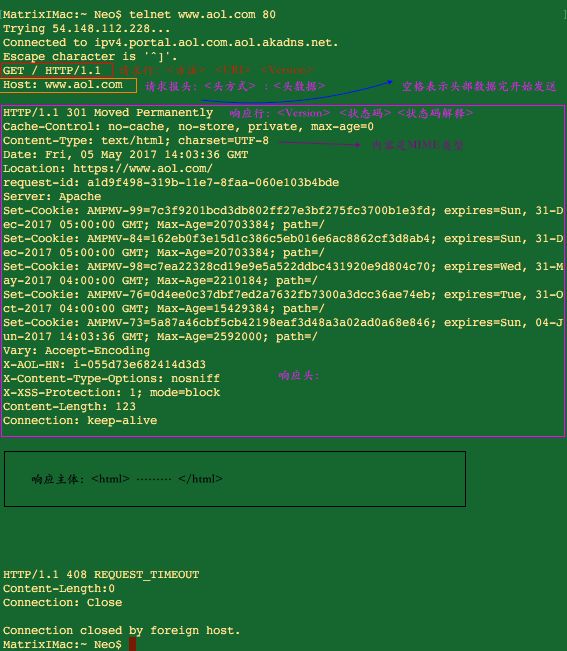
我们使用telnet 对www.aol.com 80端口进行连接,然后输入我们的请求:由两部分组成
请求行:GET / HTTP/1.1要求获取/index.html文件的内容;
请求头:host:www.aol.com附加额外信息;
最后我们以一个换行符号将我们的请求发送给服务器。
2> 响应
响应由三部分组成
响应行:HTTP/1.1 301 Moved Permanently ;
多个响应头和响应主体构成

其中状态码有以下几种:
④ 服务动态内容
1> 浏览器如何将参数传递给服务器
使用 ?符号分割文件名和参数,使用&符号分割不同的参数;
2> 服务器如何将参数传递给子进程
如果一个服务器收到一个浏览器(客户端)发送的一个类似请求:
GET /cgi-bin/adder?15000&213 HTTP/1.1
我们的adder程序遵照CGI标准编写,这样子进程将传入CGI的环境变量QUERY_STRING设置为15000&213,这样在adder程序运行的时候就可以调用getenv(获取环境变量)来获得参数
3> 服务器如何将其他信息传递给子进程
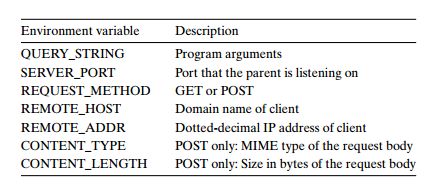
依照CGI标准定义的函数还可以设置环境变量,有下面这些可以使用
4> 子进程将输出发送到哪里
子进程加载并运行CGI程序以前,将CGI程序的标准输出从定位到了客服端已关联描述符(使用dup2函数),这样一来任何标准输出都会发送到客服端去了。同时子进程还要负责生成conten-type和content-length两个响应头,解释所发送的内容,以及终止的空行。
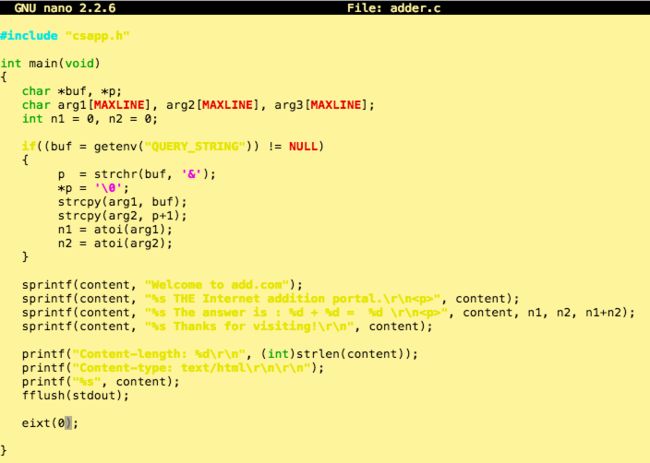
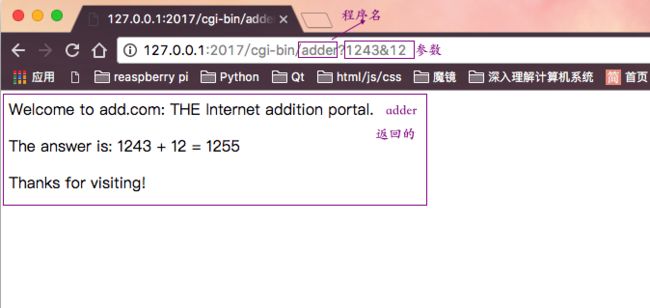
一个标准的CGI程序adder,只是简单的将传入的参数相加,并返回给客户端
1.6 实例:创建一个微小的Web服务器
我们汇总我们已经学到的所有内容,创建一个只有200多行代码的小型Web服务器,不过麻雀虽小,东西还是满多的,可以实现对静态和动态内容的访问,我们直接上完整的代码。
① 主程序mian部分:
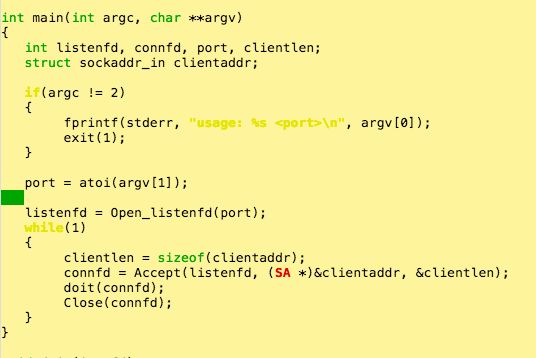
首先通过特定的端口创建一个监听描述符,然后就进入了无限循环中,通过accept函数创建已连接的描述符connfd,执行doit事务。
② doti事务
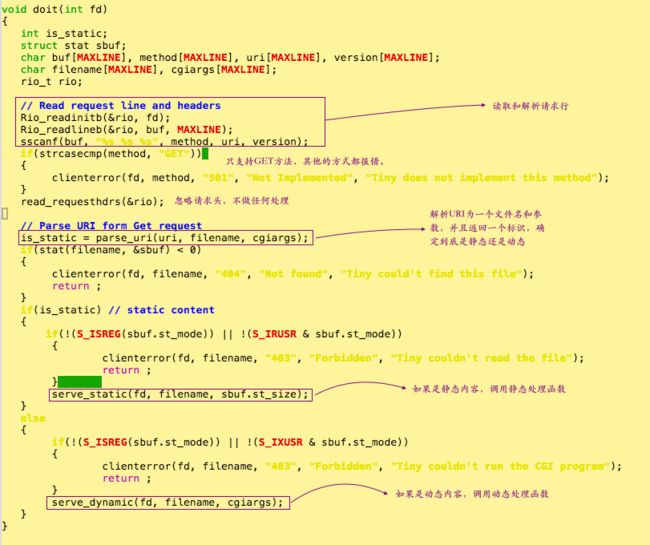
③ 解析URI函数:parse_uri
首先,我们解析请求行,并且只处理GET方法,然后对URI进行解析,返回一个标识确定到底是静态页面还是动态页面,分别调用相应的函数处理。

首先是确定到底是静态内容还是动态内容,如果是静态内容,首先清除CGI参数串,然后将URI转化为一个相对路径名,如果没有指定,默认的转向到home.html页面,返回1;如果是动态的内容,定位到?后面,抽取相应的参数,将URI转化为一个Unix文件名,返回0;
④ 忽略请求头:read_requesthdrs函数

只是简单的已报头结束的地方循环读取整个报头,然后不做任何处理,忽略它;
⑤ 处理静态页面:serve_static 和get_filetype


⑥ 处理动态内容:serve_dynamic

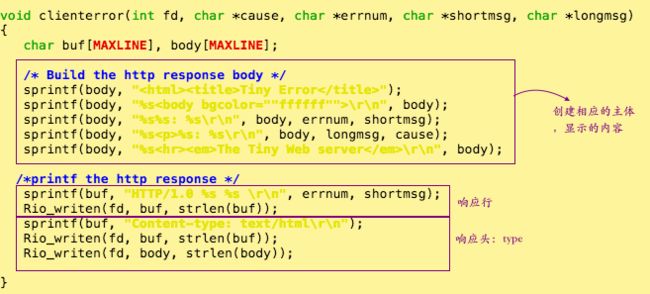
⑦ 错误处理函数:clienterror
我们来看看运行的效果,首先是解析动态内容,我们创建了一个主页:home.html文件,并且在服务端启用了
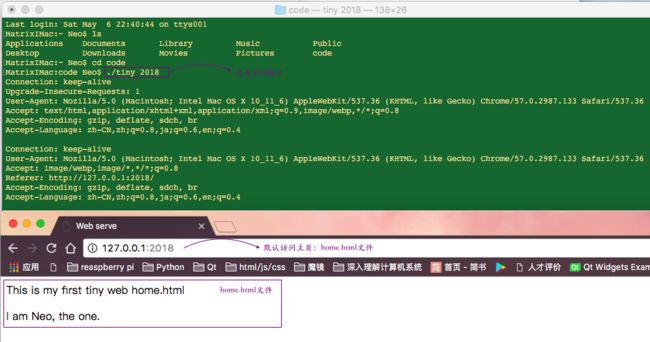
显示动态内容,我们使用之前的adder程序,将1243和12相加,并显示
2017年05月07日 完