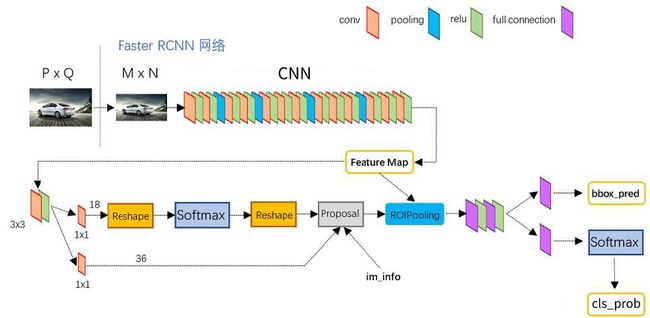
什么是ROI Pooling
ROI(Region Of Interest)是从目标图像中识别出的候选识别区域。在Faster RCNN中,候选识别区域(ROIs)是把从RPN(Region Proposal Network)产生的候选识别框映射到Feature Map上得到的。
ROI Pooling的作用就是把大小形状各不相同的候选识别区域归一化为固定尺寸的目标识别区域。
ROI Pooling算法
ROI Pooling不同于CNN 网络中的池化层,它通过分块池化的方法得到固定尺寸的输出。
假设ROI Pooling层的输出大小为,输入候选区域的大小为,ROI Pooling的过程如下:
- 把输入候选区域划分为大小的子网格窗口,每个窗口的大小为;
- 对每个子网格窗口取最大元素作为输出,从而得到大小为的输出。
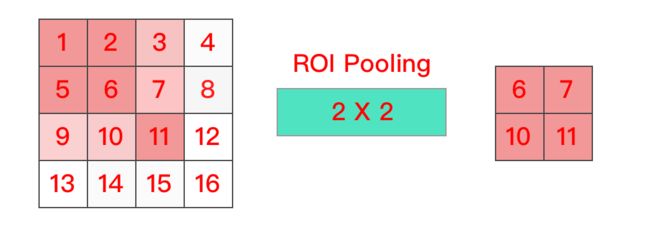 2x2 ROI Pooling Layer
2x2 ROI Pooling Layer
如上图所示,假设Feature Map大小为4x4,候选ROI区域大小为3x3,通过2x2的ROI Pooling Layer得到2x2的归一化输出。4个划分后子窗口分别为1、2、3、5(5最大),3、7(7最大),9、10(10最大),11(11最大),然后对每个子窗口做Max Pooling。
Faster RCNN中的ROI Pooling
ROI Pooling的输入:
- 通过神经网络获取的固定大小的Feature Map;
- RPN网络产生的一系列RoIs,RoIs是nx5的矩阵,N是RoI的数量,每行第一列是图像的索引,其余四列是ROI的左上角和右下角坐标;
代码实现
很多Faster RCNN的代码实现中并未使用原始论文中的方法,而是采用TensorFlow的tf.image.crop_and_resize方法将候选ROI区域进行裁剪缩放为14x14的大小,然后max pooling到7x7大小。
def roi_pool(featureMaps,rois,im_dims):
'''
Regions of Interest (ROIs) from the Region Proposal Network (RPN) are
formatted as:
(image_id, x1, y1, x2, y2)
Note: Since mini-batches are sampled from a single image, image_id = 0s
'''
with tf.variable_scope('roi_pool'):
# Image that the ROI is taken from (minibatch of 1 means these will all be 0)
box_ind = tf.cast(rois[:,0],dtype=tf.int32)
# ROI box coordinates. Must be normalized and ordered to [y1, x1, y2, x2]
boxes = rois[:,1:]
normalization = tf.cast(tf.stack([im_dims[:,1],im_dims[:,0],im_dims[:,1],im_dims[:,0]],axis=1),dtype=tf.float32)
boxes = tf.div(boxes,normalization)
boxes = tf.stack([boxes[:,1],boxes[:,0],boxes[:,3],boxes[:,2]],axis=1) # y1, x1, y2, x2
# ROI pool output size
crop_size = tf.constant([14,14])
# ROI pool
pooledFeatures = tf.image.crop_and_resize(image=featureMaps, boxes=boxes, box_ind=box_ind, crop_size=crop_size)
# Max pool to (7x7)
pooledFeatures = tf.nn.max_pool(pooledFeatures, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
return pooledFeatures
tf.image.crop_and_resize函数
tf.image.crop_and_resize(
image,
boxes,
box_ind,
crop_size,
method='bilinear',
extrapolation_value=0,
name=None
)
参数:
image:形状为[batch, image_height, image_width,channel]四维Tensor;
boxes:形状为[num_boxes, 4]的二维Tensor。Tensor的第i行指定box_ind[i]图像中ROI的坐标,输入格式为 [[ymin,xmin,ymax,xmax]],注意这些坐标都是归一化坐标;
假设crop的区域坐标为[ y1,x1,y2,x2],图片长度为[W,H],则实际输入的boxes为[y1/H,x1/W,y2/H,x2/W];box_ind:形状为[num_boxes]的一维Tensor。box_ind[i]指定第i个ROI要引用的图像;
crop_size:形状为[crop_height, crop_width]的二维Tensor。所有的ROI区域都会被调整为该大小,图像的宽高比不予保留;
method:指定插值方法的字符串,默认为"bilinear",即双线性插值;
返回值:
tf.image.crop_and_resize函数返回形状为[num_boxes,crop_height, crop_width,channel]的Tensor.