笔者根据自身的技术和行业理解,探索分析AIOps在企业落地的前提条件。
涉及关键字:自动化运维、AIOps、技术运营PaaS、蓝鲸等。
作者:张敏
AIOps概念
Gartner在2016年时便提出了AIOps的概念,AIOps即人工智能与运维的结合,并预测到2020年,AIOps 的采用率将会达到 50%。
简单来说,AIOps 就是基于已有的运维数据(日志、监控信息、应用信息等)并通过机器学习的方式来进一步解决自动化运维没办法解决的问题。
软件的一些“算法逻辑”不代表真正的AIOps,判断是否是真正AIOps的关键点在于:是否能自动从数据学习中总结规律,并利用规律对当前的环境给予决策建议。

AIOps的概念:
智能运维是以大数据平台和机器学习(算法平台)为核心。
智能运维需要与监控、服务台、自动化系统联动,智能运维需要从各个监控系统中抽取数据、面向用户提供服务、并有执行智能运维产生决策模型的自动化系统。
AIOps的应用:
通过对运维数据的计算和分析支持智能监控、智能的故障分析和处理,智能IT知识图谱等。
AIOps的价值:
传统运维面对海量的运维数据,要快速止损和进行决策,人工专家的分析判断往往需要花费数小时或更大。
而AIOps在于通过机器学习来进行运维数据的挖掘,能帮助人甚至代替人进行更有效和快速的决策。
智能运维在企业的落地,能够提升业务系统的SLA,提升用户的体验,减小故障处理的时间等,带来业务的价值;并最终实现真正意义上的无人值守运维。
AIOps应用领域
目前各大传统客户围绕AIOps的探讨和建设主要是如下内容:
发现问题:基于机器学习的异常检测;
例如,目前监控数据的异常阈值往往是静态的,无法有效规避变更时间、特殊节假日、业务正常的高低峰等,简单阈值、同环比算法的覆盖面有限,很容易漏警和误警。
基于历史数据或进行样本标记的KPI异常检测,能第一时间发现问题,检测模型能覆盖大多数曲线类型,能较好适应业务生命周期中的变化。
根因分析:基于机器学习的故障树挖掘,定位故障发生的根源以及其原因;
例如,首先实现故障精准定位,在多指标情况下的业务异常(多指标检测的异常),出现异常的原因具体是哪个指标导致的;然后根据故障树挖掘和知识图谱,实现故障的精准根因分析与定位。
预测未来:基于机器学习模型的指标预测;
例如,基于多种回归和统计方法,实现对不同级别粒度的业务数据的预测,包括业务指标预测、容量预测等,如双11业务对组件容量和资源容量的容量预测等。
IT辅助决策支持:深入运营场景,实现业务运营的IT辅助决策应用;
如营收预测、舆情分析与预测等场景。
算法层面则可以跟学术界进行合作或在社区中获取,在早期训练数据集和反馈数据量比较少的情况下,采用无监督学习,具体实现是用模式识别(pattern recognition)的技术来判断指标是否关联。关联性是通过时间序列曲线相似度(similarity distance)来衡量的。
机器学习算法库提供计算时间序列曲线相似度的各种算法,比如:欧几里德距离(Euclidean Distance)、曼哈顿距离(Manhattan Distance)、明科斯基距离(Minkowski Distance)等。
在有足够数据集以后,算法演化成有:监督学习、随机森林(Random Forrest)、GBDT(Gradient Boosted Decision Tree) 、神经网络(Neutal Network)等。
AIOps对基础设施的要求
AIOps从技术层面来讲,需要数据、算法模型两个最为核心的要素,数据的支撑需要一套整体的运维大数据体系,而算法模型的支撑则需要一套整体的挖掘框架体系,以及执行决策的自动化系统。
运维大数据:
需要有集成多类数据源、一站式低门槛的数据开发、统一的多样化数据存储和查询等功能。
数据挖掘:
全流程、可视化数据建模,支持多种机器学习框架、交互式建模IDE、可视化样本标记等功能。
自动化系统:
需要集成企业CMDB、作业执行、编排引擎、自定义场景等功能。
更为核心的是这些功能模块之间应该有效交互,不能仅仅是独立的各个模块,需要有一套平台架构来去支撑各个个性化的场景,尤其是打破数据烟囱、功能烟囱,这样才能实现有效的智能运维生命周期落地:
数据采集→数据建模→机器学习挖掘→自动化执行→反馈
而腾讯蓝鲸,腾讯IEG自用的一套用于构建企业研发运营一体化体系的PaaS开发框架,则通过解耦原子能力与场景,能完全支撑AIOps的生命周期落地。
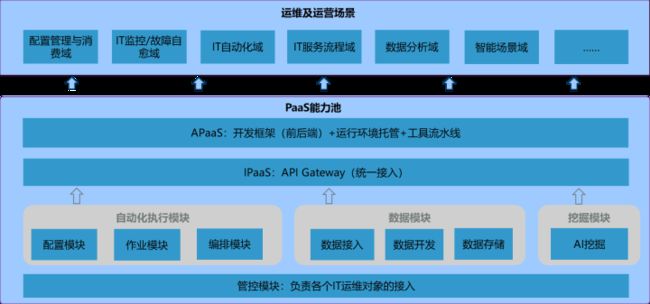
PaaS能力模块层:
1、管控模块负责通过Agent、通用协议和API接口等方式将公有云、私有云或者混合云中的服务器、存储、网络、虚拟化平台、数据库、中间件、基础应用、业务应用、云管平台、容器等企业所有需要统一运维的IT资源进行纳管;有统一的管道进行接入数据、有统一的管道执行命令。
2、平台层中的每个原子平台都是一个或者多个相关功能的集中实现:
配置模块(CMDB):
企业所有IT对象配置信息的集中存储和消费中心。
作业模块:
针对IT对象进行脚本执行和文件分发层面的自动化编排的作业中心。
编排模块:
跨系统编排及调度引擎,实现覆盖全生命周期场景的运维工作。
数据接入、开发与存储:
运维大数据平台,针对运维和运营数据进行大数据接入、清洗、存储、实时和离线计算、展示以及数据消费的中心,是实现数据运维和辅助运营的关键。
AI挖掘:
通全流程、可视化数据建模,支持多种机器学习框架、交互式建模IDE、可视化样本标记,并支持自己写入算法。
PaaS架构层
iPaaS层:
API GateWay(统一接入模块),将配置管理(CMDB)平台、作业平台、数据平台、挖掘平台等原子平台统一接入、集成、驱动和调度,供上层运维场景SaaS驱动和调用。
aPaaS开发者中心:
开发者中心提供完整的前后端开发框架,当企业在未来出现新的运维需求的时候,企业可以快速利用开发者中心完成相应的运维系统开发,并一键部署。
运维场景应用层
平台所有的运维场景的实现运行在这个层次,包含配置管理与消费、IT监控与故障自愈、运维自动化、运维流程管理、数据分析和智能运维场景。

AIOps落地前提条件探索
从整体上来讲,AIOps的引入和使用需要具备一定的条件,但并不需要企业把所有东西准备好才能动工。
例如很多企业觉得应该准备好数据完整性和人才才能开始应用AIOps,但是,数据的完整性取决于探索之后才知道怎样的数据才是完整的;AIOps人才更为关键的在于了解智能运维场景;算法也只有根据实际情况不断调优才能有更好的应用效果。
只要有痛点,和通过智能运维带来价值,AIOps就可以先引入,并逐步带动企业智能化运维的发展。
总结来讲,AIOps落地的前提条件应该分为三个方面:
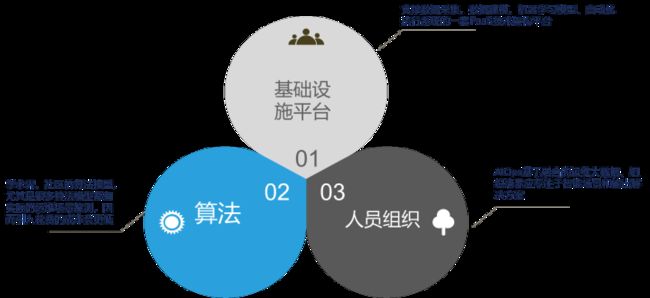
但是三个条件都不是指必须完全准备好才能开始实践:
基础设施平台:
可以从自动化能力,以及数据一体化能力进行起步建设,而不是一开始就建设一套于运维人员简单易用的模型设计框架;
算法:
目前已经有很多运维领域通用的算法,可以采用跟学术界、社区以及腾讯这些有实际落地经验的算法提供方进行合作,算法引入后需要不断调试优化才能有一个更为准确的百分比;企业也可以自建算法人才,但是算法本身属于科学领域,于企业而言,可以从性价比上综合来考虑;
人员组织:
人员组织的准备,更为关注的应该是跨技术领域的综合性运维人才,他们更懂运维场景,以及智能运维能实际解决哪些问题点,不能为了智能而智能。
以上,是笔者参考和研究一些资料后,以及结合企业经验的一些个人感受和理解,欢迎留言探讨。