此作业要求参见https://edu.cnblogs.com/campus/nenu/2019fall/homework/7628
git地址https://e.coding.net/fyzs/gongnengfenxi.git
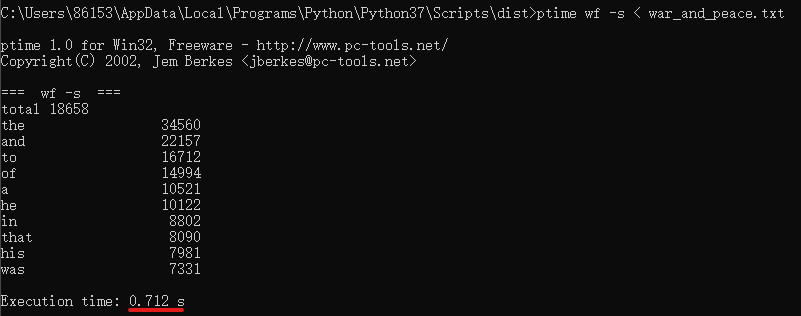
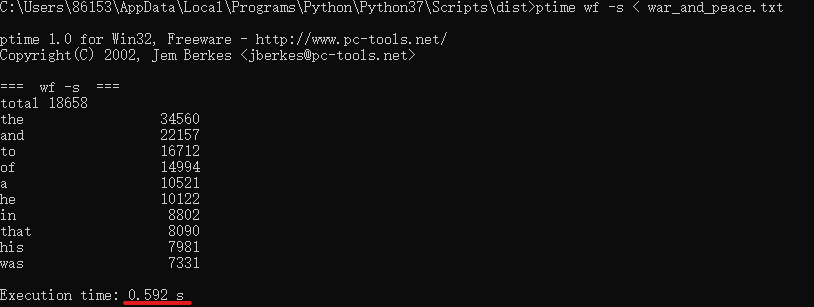
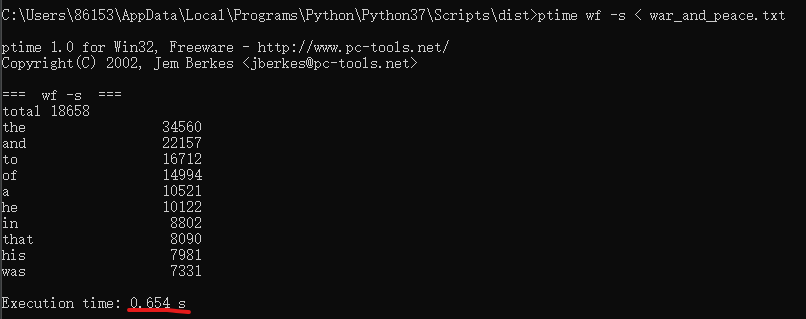
要求0 以 战争与和平 作为输入文件,重读向由文件系统读入。连续三次运行,给出每次消耗时间、CPU参数。 (2分)
cpu参数:Intel Core i7-9750H CPU @2.60Hz 2.59GHz
消耗时间:0.712s,0.592s,0.654s
要求1 给出你猜测程序的瓶颈。你认为优化会有最佳效果,或者在上周在此处做过优化 (或考虑到优化,因此更差的代码没有写出)
def count_split(str): text = re.findall(r'[a-z0-9^-]+', str) dict = {} #创建字典 for str in text: #遍历文件内单词 if str in dict.keys(): dict[str] = dict[str] + 1 else: dict[str] = 1 word_list=sorted(dict.items(), key=lambda x: x[1], reverse=True) return word_list
此处为优化后代码,上版本使用replace进行特殊字符的替换。
redirect_word = sys.stdin.read().lower() count_list = count_split(redirect_word) print('total', len(count_list)) for i in range(10): print('{:20s}{:>5d}'.format(count_list[i][0], count_list[i][1]))
此处为上次作业后完善的功能4,应该还有优化空间。
要求2 通过 profile 找出程序的瓶颈。给出程序运行中最花费时间的3个函数(或代码片断)。要求包括截图。 (5分)

程序最花费时间的三个函数:count_split(),findall(),read()
此三处为几个核心功能都需要调用的代码
要求3 根据瓶颈,"尽力而为"地优化程序性能。 (5分)
def count_split(str): p = re.compile('[-,$()#+&*.![:/"?—]') #指定特殊字符 text = re.sub(p, " ", str).split() dict = {} #创建字典 for str in text: #遍历文件内单词 if str in dict.keys(): dict[str] = dict[str] + 1 else: dict[str] = 1 word_list=sorted(dict.items(), key=lambda x: x[1], reverse=True) return word_list
findall()函数花费较多时间,使用compile函数和sub函数替换完成功能。findall()函数找出所有英文单词,compile()指定字符后用sub()替换为空格。
要求4 再次 profile,给出在 要求1 中的最花费时间的3个函数此时的花费。要求包括截图。(2分)
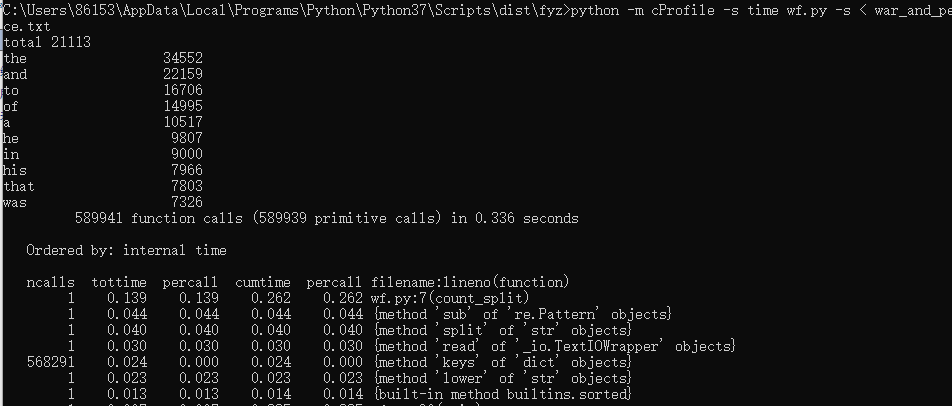
count_split()中原本花费时间较多的findall()函数,使用compile()函数和sub()替换完成功能.减少了消耗时间。
要求5 程序运行时间。根据在教师的机器 (Windows8.1) 上运行的速度排名,分为3档。此题得分,第1档20分, 第2档10分,第3档5分。功能测试不能通过的,0分。(20分)